1. Spring框架的作用
- 轻量:Spring是轻量级的,基本的版本大小为2MB
- 控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们。
- 面向切面的编程AOP:Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开。
- 容器:Spring包含并管理应用中对象的生命周期和配置
- MVC框架: Spring-MVC
- 事务管理:Spring提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务JTA
- 异常处理:Spring提供方便的API把具体技术相关的异常
2. Spring的组成

Spring由7个模块组成:
- Spring Core: 核心容器提供 Spring 框架的基本功能。核心容器的主要组件是BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转 (IOC) 模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
- Spring 上下文:Spring 上下文是一个配置文件,向 Spring 框架提供上下文信息。Spring 上下文包括企业服务,例如 JNDI、EJB、电子邮件、国际化、校验和调度功能。
- Spring AOP:通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了 Spring 框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
- Spring DAO:JDBC DAO 抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写的异常代码数量(例如打开和关闭连接)。Spring DAO 的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。
- Spring ORM:Spring 框架插入了若干个 ORM 框架,从而提供了 ORM 的对象关系工具,其中包括 JDO、Hibernate 和 iBatis SQL Map。所有这些都遵从 Spring 的通用事务和 DAO 异常层次结构。
- Spring Web 模块:Web 上下文模块建立在应用程序上下文模块之上,为基于 Web 的应用程序提供了上下文。所以,Spring 框架支持与 Jakarta Struts 的集成。Web 模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
- Spring MVC 框架:MVC 框架是一个全功能的构建 Web 应用程序的 MVC 实现。通过策略接口,MVC 框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括 JSP、Velocity、Tiles、iText 和 POI。
3. Spring容器
Sping的容器可以分为两种类型
- BeanFactory:(org.springframework.beans.factory.BeanFactory接口定义)是最简答的容器,提供了基本的DI支持。最常用的BeanFactory实现就是XmlBeanFactory类,它根据XML文件中的定义加载beans,该容器从XML文件读取配置元数据并用它去创建一个完全配置的系统或应用。
- ApplicationContext应用上下文:(org.springframework.context.ApplicationContext)基于BeanFactory之上构建,并提供面向应用的服务。
4. ApplicationContext通常的实现
- ClassPathXmlApplicationContext:从类路径下的XML配置文件中加载上下文定义,把应用上下文定义文件当做类资源。
- FileSystemXmlApplicationContext:读取文件系统下的XML配置文件并加载上下文定义。
- XmlWebApplicationContext:读取Web应用下的XML配置文件并装载上下文定义。
|
1
|
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml"); |
5. IOC & DI
Inversion of Control, 一般分为两种类型:依赖注入DI(Dependency Injection)和依赖查找(Dependency Lookup).依赖注入应用比较广泛。
Spring IOC负责创建对象,管理对象(DI),装配对象,配置对象,并且管理这些对象的整个生命周期。
优点:把应用的代码量降到最低。容器测试,最小的代价和最小的侵入性使松散耦合得以实现。IOC容器支持加载服务时的饿汉式初始化和懒加载。
DI依赖注入是IOC的一个方面,是个通常的概念,它有多种解释。这概念是说你不用床架对象,而只需要描述它如何被创建。你不在代码里直接组装你的组件和服务,但是要在配置文件里描述组件需要哪些服务,之后一个IOC容器辅助把他们组装起来。
IOC的注入方式:1. 构造器依赖注入;2. Setter方法注入。
6. 如何给spring容器提供配置元数据
- XML配置文件
- 基于注解的配置
- 基于Java的配置@Configuration, @Bean
7. bean标签中的属性:
- id
- name
- class
- init-method:Bean实例化后会立刻调用的方法
- destory-method:Bean从容器移除和销毁前,会调用的方法
- factory-method:运行我们调用一个指定的静态方法,从而代替构造方法来创建一个类的实例。
- scope:Bean的作用域,包括singleton(默认),prototype(每次调用都创建一个实例), request,session, global-session(注意spring中的单例bean不是线程安全的)
- autowired:自动装配 byName, byType, constructor, autodetect(首先阐释使用constructor自动装配,如果没有发现与构造器相匹配的Bean时,Spring将尝试使用byType自动装配)
8. beans标签中相关属性
default-init-method
default-destory-method
default-autowire:默认为none,应用于Spring配置文件中的所有Bean,注意这里不是指Spring应用上下文,因为你可以定义多个配置文件
9. Bean的生命周期
1) 创建Bean的实例(factory-method, autowireConstrutor)
2) 属性注入(autowireByName, autowireByType)
3) 初始化Bean
3.1 激活Aware方法:(invokeAwaresMethods)Spring中提供了一些Aware相关接口,比如BeanNameAware, BeanFactoryAware, ApplicationContextAware等,实现这些Aware接口的bean在被初始化之后,可以取得一些相对应的资源。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
private void invokeAwareMethods(final String beanName, final Object bean){ if(bean instanceof Aware) { if(bean instanceof BeanNameAware){ ((BeanNameAware) bean).setBeanName(beanName); } if(bean instanceof BeanClassLoaderAware){ ((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader()); } if(bean instanceof BeanFactoryAware){ ((BeanFactoryAware) bean).setBeanFactory(AbstactAutowire CapableBeanFactory.this); } }} |
3.2 处理器的应用(BeanPostProcessor接口):调用客户自定义初始化方法前以及调用自定义初始化方法后分别会调用BeanPostProcessor的postProcessBeforeInitialization和postProcessAfterInitialization方法,使用户可以根据自己的业务需求进行响应的处理。
3.3 激活自定义的init方法(init-method & 自定义实现InitializingBean接口)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
protected Object initializeBean(final String beanName, final Object bean, RootBeanDefinetion mbd){ if(System.getSecurityManager() != null){ AccessController.doPrivileged(new PrivilegedAction @Override public Object run() { invokeAwareMethods(beanName,bean); return null; } }); } else{ //对特殊的bean处理:Aware, BeanClassLoaderAware, BeanFactoryAware invokeAwareMethods(beanName,bean); } Object wrappedBean = bean; if(mbd == null !! !mbd.isSynthetic()){ wrappedBean = applyBeanPostProcessorsBeforeInitialization(wappedBean,beanName); } try{ invokeInitMethods(beanName, wappedBean, mbd); } catch(Throwable ex){ throw new BeanCreationException((mbd != null ? mbd.getResourceDescription():null),beanName,"Invocation of init method failed",ex); } if(mbd == null || !mbd.isSynthetic()){ wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName); } return wappedBean;} |
4) 使用Bean。 驻留在应用的上下文中,直到该应用上下文被销毁。
5) 销毁(destory-mthod & 实现DisposableBean接口)
Or represent like this:
1. Bean的构造
2. 调用setXXX()方法设置Bean的属性
3. 调用BeanNameAware的setBeanName()
4. 调用BeanFactoryAware的setBeanFactory()方法
5. 调用BeanPostProcessor的postProcessBeforeInitialization()方法
6. 调用InitializingBean的afterPropertiesSet()方法
7. 调用自定义的初始化方法
8. 调用BeanPostProcessor类的postProcessAfterInitialization()方法
9. 调用DisposableBean的destroy()方法
10. 调用自定义的销毁方法
10. Spring中注入集合
- 允许值相同
不允许值相同 -
键和值都可以为任意类型,key, key-ref, value-ref, value可以任意搭配
XXX
11. 装配空值
|
1
|
|
12. 自动装配(autowiring)
有助于减少甚至消除配置
与之对应的是:自动检测(autodiscovery),比自动装配更近了一步,让Spring能够自动识别哪些类需要被配置成SpringBean,从而减少对
13. 注解
Spring容器默认禁用注解装配。最简单的开启方式
Spring支持的几种不同的用于自动装配的注解:
- Spring自带的@Autowired注解
- JSR-330的@Inject注解
- JSR-250的@Resource注解
14. @Autowired
@Autowired具有强契约特征,其所标注的属性或参数必须是可装配的。如果没有Bean可以装配到@Autowired所标注的属性或参数中,自动装配就会失败,抛出NoSuchBeanDefinitionException.
属性不一定非要装配,null值也是可以接受的。在这种场景下可以通过设置@Autowired的required属性为false来配置自动装配是可选的,如:
|
1
2
|
@Autowired(required=false)private Object obj; |
注意required属性可以用于@Autowired注解所使用的任意地方。但是当使用构造器装配时,只有一个构造器可以将@Autowired的required属性设置为true。其他使用@Autowired注解所标注的构造器只能将required属性设置为false。此外,当使用@Autowired标注多个构造器时,Spring就会从所有满足装配条件的构造器中选择入参最多的那个构造器。
可以使用@Qualifier明确指定要装配的Bean.如下:
|
1
2
3
|
@Autowired@Qualifier("objName")private Object obj; |
15. 自定义的限定器
|
1
2
3
4
|
@Target({ElementType.FIELF, ElementType.PARAMETER, ElementType.TYPE})@Retention(RetentionPolicy.RUNTIME)@Qualifierpublic @Interface SpecialQualifier{} |
此时,可以通过自定义的@SpecialQualifier注解来代替@Qualifier来标注,也可以和@Autowired一起使用:
|
1
2
3
|
@Autowired@SpecialQualifierprivate Object obj; |
此时,Spring会把自动装配的范围缩小到被@SpecialQualifier标注的Bean中。如果被@SpecialQualifier标注的Bean有多个,我们还可以通过自定义的另一个限定器@SpecialQualifier2来进一步缩小范围。
16. @Autowired优缺点
Spring的@Autowired注解是减少Spring XML配置的一种方式。但是它的类会映入对Spring的特定依赖(即使依赖只是一个注解)。
17. @Inject
和@Autowired注解一样,@Inject可以用来自动装配属性、方法和构造器;与@Autowired不同的是,@Inject没有required属性。因此@Inject注解所标注的依赖关系必须存在,如果不存在,则会抛出异常。
18. @Named
相对于@Autowired对应的Qualifier,@Inject所对应的是@Named注解。
|
1
2
3
|
@Inject@Named("objName")private Object obj; |
19. SpEL表达式
语法形式在#{}中使用表达式,如:
|
1
|
|
20. @Value
@Value是一个新的装配注解,可以让我们使用注解装配String类型的值和基本类型的值,如int, boolean。我们可以通过@Value直接标注某个属性,方法或者方法参数,并传入一个String类型的表达式来装配属性,如:
|
1
2
|
@Value("Eruption")private String song; |
@Value可以配合SpEL表达式一起使用,譬如有些情况下需要读取properties文件中的内容,可以使用:
|
1
|
@Value("#{configProperties['ora_driver']}") |
详细可以参考Spring+Mybatis多数据源配置(三)——Spring如何获取Properties文件的信息
21. 自动检测Bean
|
1
|
|
22. 为自动检测标注Bean
默认情况下,查找使用构造型(stereotype)注解所标注的类,这些特殊的注解如下:
- @Component:通用的构造型注解,标志此类为Spring组件
- @Controller:标识将该类定义为SpringMVC controller
- @Repository:标识将该类定义为数据仓库
- @Service:标识将该类定义为服务
以@Component为例:
|
1
2
|
@Componentpublic class Guitar implements Intrument{} |
这里@Component会自动注册Guitar 为Spring Bean,并设置默认的Bean的Id为guitar,首字母大写变小写。注意如果第一个和第二个字母都是大写,默认的Bean的id会有特殊处理。
也可以指定Bean的Id如:
|
1
2
|
@Component("guitarOne")public class Guitar implements Intrument{} |
23. AOP
面向切面的编程AOP,是一种编程技术,允许程序模块化横向切割关注点,或横切典型的责任划分,如日志和事务管理。
AOP的核心是切面,它将多个类的通用行为封装成可重用的模块,该模块含有一组API提供横切功能。比如,一个日志模块可以被称作日志的AOP切面。根据需求的不同,一个应用程序可以有若干切面。在SpringAOP中,切面通过带有@Aspect注解的类实现。
关注点是应用中的一个模块的行为,一个关注点可能会被定义成一个我们想实现的一个功能。
横切关注点一个关注点,此关注点是整个应用都会使用的功能,并影响整个应用,比如日志,安全和数据传输,几乎应用的每个模块都需要的功能。因此这些都属于横切关注点。
连接点代表一个应用程序的某个位置,在这个位置我们可以插入一个AOP切面,它实际上是个应用程序执行Spring AOP的位置。
切点是一个或一组连接点,通知将在这些位置执行。可以通过表达式或匹配的方式指明切入点。
引入运行我们在已存在的类中添加新的方法和属性。
24. AOP通知
通知是个在方法执行前后要做的动作,实际上是程序执行时要通过SpringAOP框架触发的代码
Spring切面可以应用五种类型的通知:
before:前置通知,在一个方法执行前被调用。@Before
after: 在方法执行之后调用的通知,无论方法执行是否成功。@After
after-returning: 仅当方法成功完成后执行的通知。@AfterReturning
after-throwing: 在方法抛出异常退出时执行的通知。@AfterThrowing
around: 在方法执行之前和之后调用的通知。@Around
25. Spring的事务类型
编程式事务管理:这意味你通过编程的方式管理事务,给你带来极大的灵活性,但是难维护。
声明式事务管理:这意味着你可以将业务代码和事务管理分离,你只需用注解和XML配置来管理事务。
26. ACID
- Atomic原子性:事务是由一个或多个活动所组成的一个工作单元。原子性确保事务中的所有操作全部发生或者全部不发生。
- Consistent一致性:一旦事务完成,系统必须确保它所建模的业务处于一致的状态
- Isolated隔离线:事务允许多个用户对象头的数据进行操作,每个用户的操作不会与其他用户纠缠在一起。
- Durable持久性:一旦事务完成,事务的结果应该持久化,这样就能从任何的系统崩溃中恢复过来。
27. JDBC事务
如果在应用程序中直接使用JDBC来进行持久化,譬如博主采用的是Mybatis,DataSourceTransactionManager会为你处理事务边界。譬如:
|
1
2
3
4
5
6
7
8
9
10
11
|
destroy-method="close"> |
28. JTA事务
如果你的事务需要跨多个事务资源(例如:两个或多个数据库;或者如Sping+ActiveMQ整合需要将ActiveMQ和数据库的事务整合起来),就需要使用JtaTransactionManager:
|
1
|
|
JtaTransactionManager将事务管理的职责委托给了一个JTA的实现。JTA规定了应用程序与一个或多个数据源之间协调事务的标准API。transactionManagerName属性指明了要在JNDI上查找的JTA事务管理器。
JtaTransactionManager将事务管理的职责委托给javax.transaction.UserTransaction和javax.transaction.TransactionManager对象。通过UserTransaction.commit()方法来提交事务。类似地,如果事务失败,UserTransaction的rollback()方法将会被调用。
29. 声明式事务
尽管Spring提供了多种声明式事务的机制,但是所有的方式都依赖这五个参数来控制如何管理事务策略。因此,如果要在Spring中声明事务策略,就要理解这些参数。(@Transactional)
1. 隔离级别(isolation)
- ISOLATION_DEFAULT: 使用底层数据库预设的隔离层级
- ISOLATION_READ_COMMITTED: 允许事务读取其他并行的事务已经送出(Commit)的数据字段,可以防止Dirty read问题
- ISOLATION_READ_UNCOMMITTED: 允许事务读取其他并行的事务还没送出的数据,会发生Dirty、Nonrepeatable、Phantom read等问题
- ISOLATION_REPEATABLE_READ: 要求多次读取的数据必须相同,除非事务本身更新数据,可防止Dirty、Nonrepeatable read问题
- ISOLATION_SERIALIZABLE: 完整的隔离层级,可防止Dirty、Nonrepeatable、Phantom read等问题,会锁定对应的数据表格,因而有效率问题
2. 传播行为(propagation)
- PROPAGATION_REQUIRED–支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
- PROPAGATION_SUPPORTS–支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY–支持当前事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW–新建事务,如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED–以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER–以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED–如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。
3. 只读(read-only)
如果事务只进行读取的动作,则可以利用底层数据库在只读操作时发生的一些最佳化动作,由于这个动作利用到数据库在只读的事务操作最佳化,因而必须在事务中才有效,也就是说要搭配传播行为PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED来设置。
4. 事务超时(timeout)
有的事务操作可能延续很长一段的时间,事务本身可能关联到数据表的锁定,因而长时间的事务操作会有效率上的问题,对于过长的事务操作,考虑Roll back事务并要求重新操作,而不是无限时的等待事务完成。 可以设置事务超时期间,计时是从事务开始时,所以这个设置必须搭配传播行为PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED来设置。
5. 回滚规则(rollback-for, no-rollback-for)
rollback-for指事务对于那些检查型异常应当回滚而不提交;no-rollback-for指事务对于那些异常应当继续运行而不回滚。默认情况下,Spring声明事务对所有的运行时异常都进行回滚。
|
1
2
3
4
5
|
|
30. SpringMVC

核心架构的具体流程:
- 首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
- DispatcherServlet——>HandlerMapping, HandlerMapping将会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象、多个HandlerInterceptor拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
- DispatcherServlet——>HandlerAdapter,HandlerAdapter将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
- HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView对象(包含模型数据、逻辑视图名);
- ModelAndView的逻辑视图名——> ViewResolver, ViewResolver将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
- View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
- 返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
31. DispatcherServlet
SpringMVC的核心是DispatcherServlet,这个Servlet充当SpringMVC的前端控制器。与其他Servlet一样,DispatcherServlet必须在Web应用程序的web.xml文件中进行配置。
|
1
2
3
4
5
|
2 |
默认情况下,DispatcherServlet在加载时会从一个基于这个Servlet名字的XML文件中加载Spring应用上下文。因为servlet的名字是viewspace,所以配置文件的名称为viewspace-servlet.xml。
接下来,必须申明DispatcherServlet处理那些URL:
|
1
2
3
4
|
|
通过将DispatcherServlet映射到/,声明了它会作为默认的servlet并且会处理所有的请求,包括对静态资源的请求。
可以配置:
|
1
2
3
4
5
6
|
cache-period="31556926" /> cache-period="31556926" /> cache-period="31556926" /> |
处理静态资源。
32. 配置HandlerMapping
Spring自带了多个处理器映射实现:
- BeanNameUrlHandlerMapping:根据控制器Bean的名字将控制器映射到URL。
- ControllerBeanNameHandlerMapping:与BeanNameUrlHandlerMapping类似,根据控制器Bean的名字将控制器映射到URL。使用该处理器映射实现,Bean的名字不需要遵循URL的约定。
- ControllerClassNameHandlerMapping:通过使用控制器的类名作为URL基础将控制器映射到URL。
- DefaultAnnotationHandlerMapping:将请求映射给使用@RequestingMapping注解的控制器和控制器方法。
- SimpleUrlHandlerMapping:使用定义在Spring应用上下文的熟悉集合将控制器映射到URL。
- 使用如上这些处理器映射通常只需在Spring中配置一个Bean。如果没有找到处理器映射Bean,DisapatchServlet将创建并使用BeanNameUrlHandlerMapping和DefaultAnnotationHandlerMapping。我们一般使用基于注解的控制器类。
|
1
2
3
4
|
class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter"> |
在构建控制器的时候,我们还需要使用注解将请求参数绑定到控制器的方法参数上进行校验以及信息转换。提供注解驱动的特性。
33. 配置HandlerAdapter
|
1
2
|
class="org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping" /> |
34. 配置视图
在SpringMVC中大量使用了约定优于配置的开发模式。InternalResourceViewResolver就是一个面向约定的元素。它将逻辑视图名称解析为View对象,而该对象将渲染的任务委托给Web应用程序上下文中的一个模板。
|
1
2
3
4
5
6
7
8
|
class="org.springframework.web.servlet.view.InternalResourceViewResolver"> value="org.springframework.web.servlet.view.JstlView" /> |
当DispatcherServlet要求InternalResourceViewResolver解析视图的时候,它将获取一个逻辑视图名称,添加”/WEB-INF/jsp/”前缀和”.jsp”后缀。等待的结果就是渲染输出的JSP路径。在内部,InternalResourceViewResolver接下来会将这个路径传递给View对象,View对象将请求传递给JSP.
参考文献
1. 《Sping In Action》 Craig Walls
2. 69道Spring面试题和答案
3. Sping+ActiveMQ整合
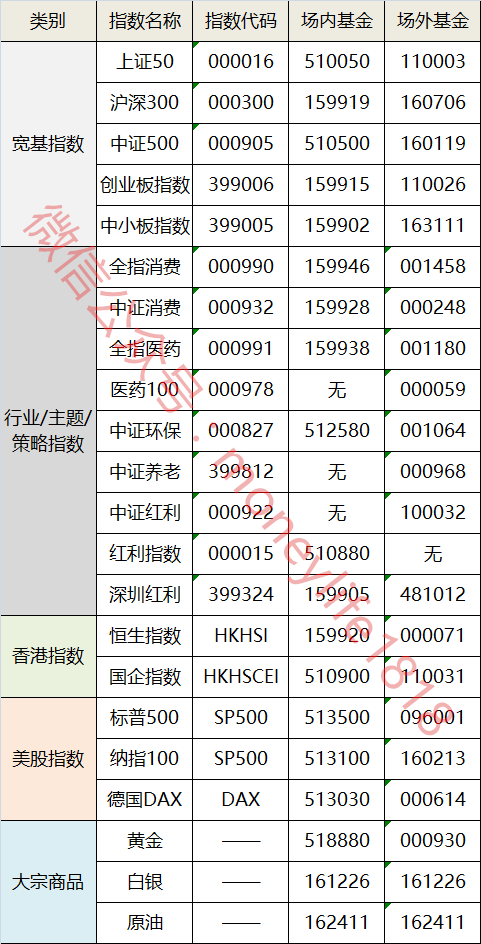

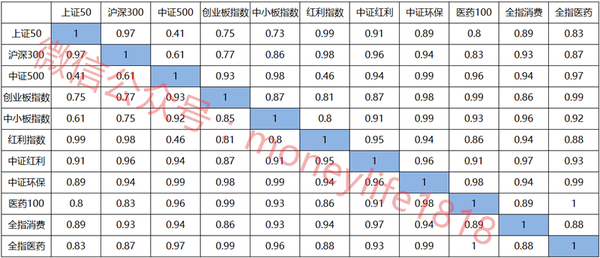

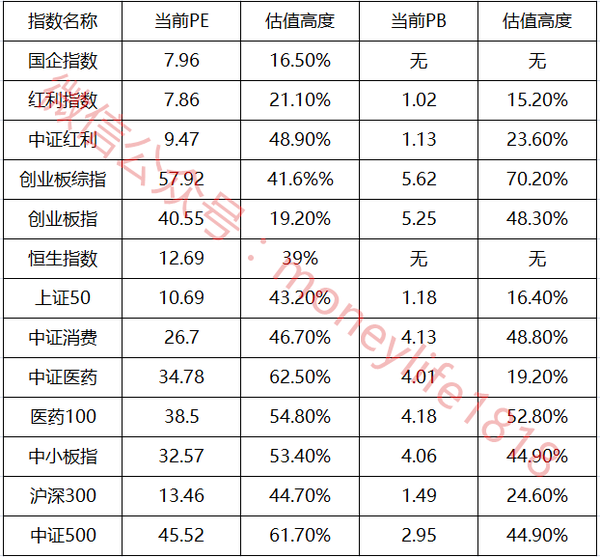

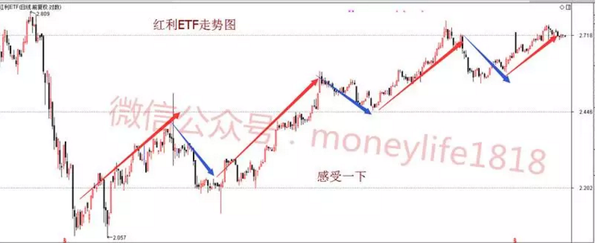

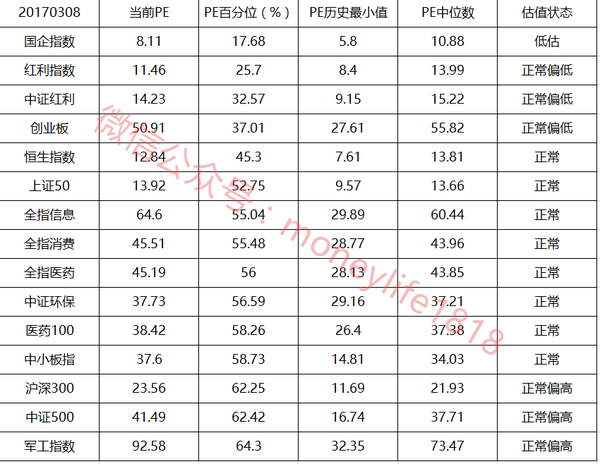

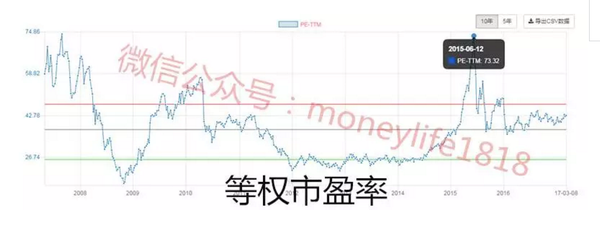





































 各算法比较
各算法比较

