For the last five years, the Internet Engineering Task Force (IETF), the standards body that defines internet protocols, has been working on standardizing the latest version of one of its most important security protocols: Transport Layer Security (TLS). TLS is used to secure the web (and much more!), providing encryption and ensuring the authenticity of every HTTPS website and API. The latest version of TLS, TLS 1.3 (RFC 8446) was published today. It is the first major overhaul of the protocol, bringing significant security and performance improvements. This article provides a deep dive into the changes introduced in TLS 1.3 and its impact on the future of internet security.
An evolution
One major way Cloudflare provides security is by supporting HTTPS for websites and web services such as APIs. With HTTPS (the “S” stands for secure) the communication between your browser and the server travels over an encrypted and authenticated channel. Serving your content over HTTPS instead of HTTP provides confidence to the visitor that the content they see is presented by the legitimate content owner and that the communication is safe from eavesdropping. This is a big deal in a world where online privacy is more important than ever.
The machinery under the hood that makes HTTPS secure is a protocol called TLS. It has its roots in a protocol called Secure Sockets Layer (SSL) developed in the mid-nineties at Netscape. By the end of the 1990s, Netscape handed SSL over to the IETF, who renamed it TLS and have been the stewards of the protocol ever since. Many people still refer to web encryption as SSL, even though the vast majority of services have switched over to supporting TLS only. The term SSL continues to have popular appeal and Cloudflare has kept the term alive through product names like Keyless SSL and Universal SSL.

In the IETF, protocols are called RFCs. TLS 1.0 was RFC 2246, TLS 1.1 was RFC 4346, and TLS 1.2 was RFC 5246. Today, TLS 1.3 was published as RFC 8446. RFCs are generally published in order, keeping 46 as part of the RFC number is a nice touch.
TLS 1.2 wears parachute pants and shoulder pads

MC Hammer, like SSL, was popular in the 90s
Over the last few years, TLS has seen its fair share of problems. First of all, there have been problems with the code that implements TLS, including Heartbleed, BERserk, goto fail;, and more. These issues are not fundamental to the protocol and mostly resulted from a lack of testing. Tools like TLS Attacker and Project Wycheproof have helped improve the robustness of TLS implementation, but the more challenging problems faced by TLS have had to do with the protocol itself.
TLS was designed by engineers using tools from mathematicians. Many of the early design decisions from the days of SSL were made using heuristics and an incomplete understanding of how to design robust security protocols. That said, this isn’t the fault of the protocol designers (Paul Kocher, Phil Karlton, Alan Freier, Tim Dierks, Christopher Allen and others), as the entire industry was still learning how to do this properly. When TLS was designed, formal papers on the design of secure authentication protocols like Hugo Krawczyk’s landmark SIGMA paper were still years away. TLS was 90s crypto: It meant well and seemed cool at the time, but the modern cryptographer’s design palette has moved on.
Many of the design flaws were discovered using formal verification. Academics attempted to prove certain security properties of TLS, but instead found counter-examples that were turned into real vulnerabilities. These weaknesses range from the purely theoretical (SLOTH and CurveSwap), to feasible for highly resourced attackers (WeakDH, LogJam, FREAK, SWEET32), to practical and dangerous (POODLE, ROBOT).
TLS 1.2 is slow
Encryption has always been important online, but historically it was only used for things like logging in or sending credit card information, leaving most other data exposed. There has been a major trend in the last few years towards using HTTPS for all traffic on the Internet. This has the positive effect of protecting more of what we do online from eavesdroppers and injection attacks, but has the downside that new connections get a bit slower.
For a browser and web server to agree on a key, they need to exchange cryptographic data. The exchange, called the “handshake” in TLS, has remained largely unchanged since TLS was standardized in 1999. The handshake requires two additional round-trips between the browser and the server before encrypted data can be sent (or one when resuming a previous connection). The additional cost of the TLS handshake for HTTPS results in a noticeable hit to latency compared to an HTTP alone. This additional delay can negatively impact performance-focused applications.
Defining TLS 1.3
Unsatisfied with the outdated design of TLS 1.2 and two-round-trip overhead, the IETF set about defining a new version of TLS. In August 2013, Eric Rescorla laid out a wishlist of features for the new protocol:
https://www.ietf.org/proceedings/87/slides/slides-87-tls-5.pdf
After some debate, it was decided that this new version of TLS was to be called TLS 1.3. The main issues that drove the design of TLS 1.3 were mostly the same as those presented five years ago:
- reducing handshake latency
- encrypting more of the handshake
- improving resiliency to cross-protocol attacks
- removing legacy features
The specification was shaped by volunteers through an open design process, and after four years of diligent work and vigorous debate, TLS 1.3 is now in its final form: RFC 8446. As adoption increases, the new protocol will make the internet both faster and more secure.
In this blog post I will focus on the two main advantages TLS 1.3 has over previous versions: security and performance.
Trimming the hedges

Creative Commons Attribution-Share Alike 3.0
In the last two decades, we as a society have learned a lot about how to write secure cryptographic protocols. The parade of cleverly-named attacks from POODLE to Lucky13 to SLOTH to LogJam showed that even TLS 1.2 contains antiquated ideas from the early days of cryptographic design. One of the design goals of TLS 1.3 was to correct previous mistakes by removing potentially dangerous design elements.
Fixing key exchange
TLS is a so-called “hybrid” cryptosystem. This means it uses both symmetric key cryptography (encryption and decryption keys are the same) and public key cryptography (encryption and decryption keys are different). Hybrid schemes are the predominant form of encryption used on the Internet and are used in SSH, IPsec, Signal, WireGuard and other protocols. In hybrid cryptosystems, public key cryptography is used to establish a shared secret between both parties, and the shared secret is used to create symmetric keys that can be used to encrypt the data exchanged.
As a general rule, public key crypto is slow and expensive (microseconds to milliseconds per operation) and symmetric key crypto is fast and cheap (nanoseconds per operation). Hybrid encryption schemes let you send a lot of encrypted data with very little overhead by only doing the expensive part once. Much of the work in TLS 1.3 has been about improving the part of the handshake, where public keys are used to establish symmetric keys.
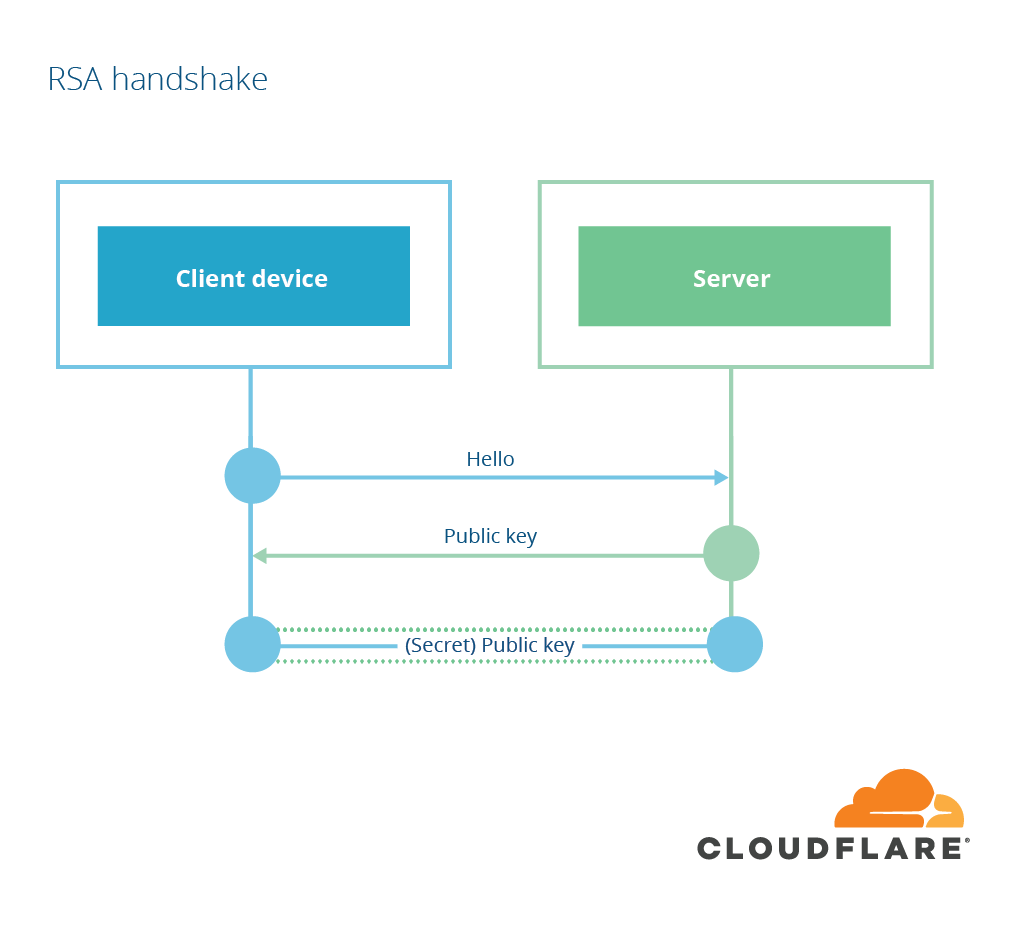
RSA key exchange
The public key portion of TLS is about establishing a shared secret. There are two main ways of doing this with public key cryptography. The simpler way is with public-key encryption: one party encrypts the shared secret with the other party’s public key and sends it along. The other party then uses its private key to decrypt the shared secret and … voila! They both share the same secret. This technique was discovered in 1977 by Rivest, Shamir and Adelman and is called RSA key exchange. In TLS’s RSA key exchange, the shared secret is decided by the client, who then encrypts it to the server’s public key (extracted from the certificate) and sends it to the server.
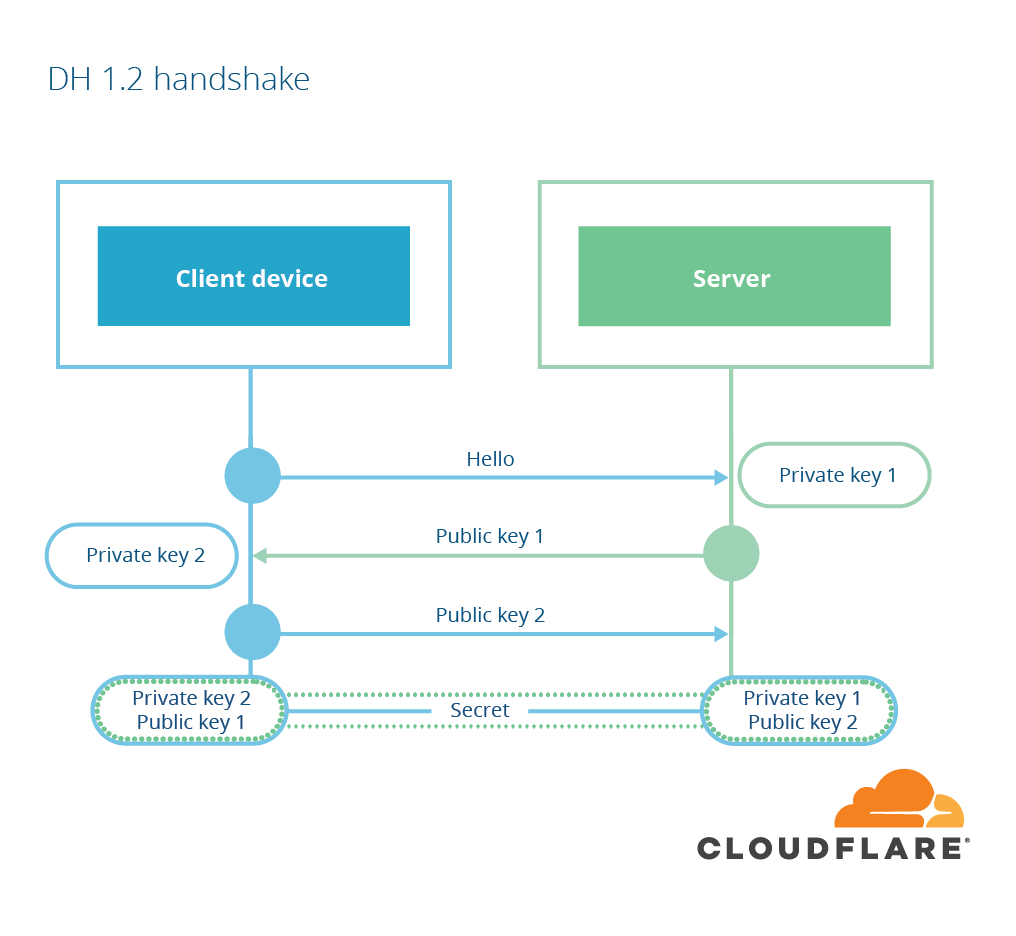
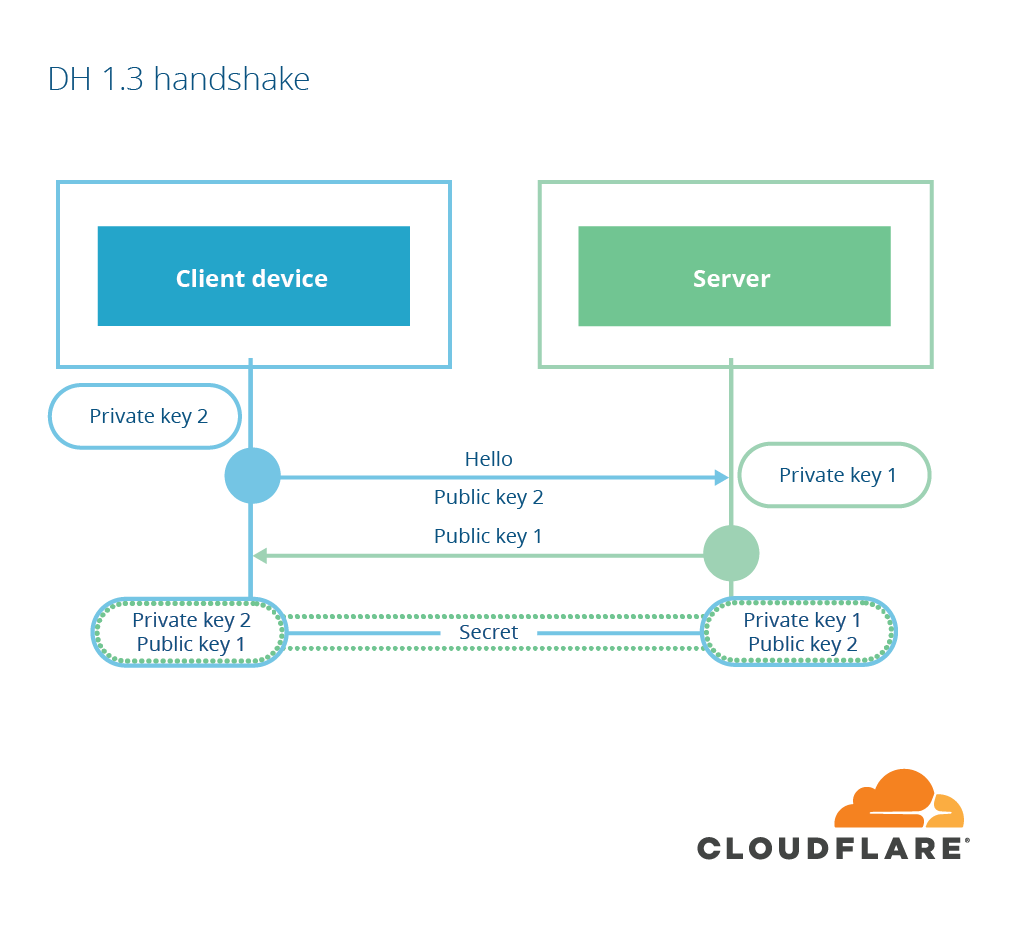
The other form of key exchange available in TLS is based on another form of public-key cryptography, invented by Diffie and Hellman in 1976, so-called Diffie-Hellman key agreement. In Diffie-Hellman, the client and server both start by creating a public-private key pair. They then send the public portion of their key share to the other party. When each party receives the public key share of the other, they combine it with their own private key and end up with the same value: the pre-main secret. The server then uses a digital signature to ensure the exchange hasn’t been tampered with. This key exchange is called “ephemeral” if the client and server both choose a new key pair for every exchange.
Both modes result in the client and server having a shared secret, but RSA mode has a serious downside: it’s not forward secret. That means that if someone records the encrypted conversation and then gets ahold of the RSA private key of the server, they can decrypt the conversation. This even applies if the conversation was recorded and the key is obtained some time well into the future. In a world where national governments are recording encrypted conversations and using exploits like Heartbleed to steal private keys, this is a realistic threat.
RSA key exchange has been problematic for some time, and not just because it’s not forward-secret. It’s also notoriously difficult to do correctly. In 1998, Daniel Bleichenbacher discovered a vulnerability in the way RSA encryption was done in SSL and created what’s called the “million-message attack,” which allows an attacker to perform an RSA private key operation with a server’s private key by sending a million or so well-crafted messages and looking for differences in the error codes returned. The attack has been refined over the years and in some cases only requires thousands of messages, making it feasible to do from a laptop. It was recently discovered that major websites (including facebook.com) were also vulnerable to a variant of Bleichenbacher’s attack called the ROBOT attack as recently as 2017.
To reduce the risks caused by non-forward secret connections and million-message attacks, RSA encryption was removed from TLS 1.3, leaving ephemeral Diffie-Hellman as the only key exchange mechanism. Removing RSA key exchange brings other advantages, as we will discuss in the performance section below.
Diffie-Hellman named groups
When it comes to cryptography, giving too many options leads to the wrong option being chosen. This principle is most evident when it comes to choosing Diffie-Hellman parameters. In previous versions of TLS, the choice of the Diffie-Hellman parameters was up to the participants. This resulted in some implementations choosing incorrectly, resulting in vulnerable implementations being deployed. TLS 1.3 takes this choice away.
Diffie-Hellman is a powerful tool, but not all Diffie-Hellman parameters are “safe” to use. The security of Diffie-Hellman depends on the difficulty of a specific mathematical problem called the discrete logarithm problem. If you can solve the discrete logarithm problem for a set of parameters, you can extract the private key and break the security of the protocol. Generally speaking, the bigger the numbers used, the harder it is to solve the discrete logarithm problem. So if you choose small DH parameters, you’re in trouble.
The LogJam and WeakDH attacks of 2015 showed that many TLS servers could be tricked into using small numbers for Diffie-Hellman, allowing an attacker to break the security of the protocol and decrypt conversations.
Diffie-Hellman also requires the parameters to have certain other mathematical properties. In 2016, Antonio Sanso found an issue in OpenSSL where parameters were chosen that lacked the right mathematical properties, resulting in another vulnerability.
TLS 1.3 takes the opinionated route, restricting the Diffie-Hellman parameters to ones that are known to be secure. However, it still leaves several options; permitting only one option makes it difficult to update TLS in case these parameters are found to be insecure some time in the future.
Fixing ciphers
The other half of a hybrid crypto scheme is the actual encryption of data. This is done by combining an authentication code and a symmetric cipher for which each party knows the key. As I’ll describe, there are many ways to encrypt data, most of which are wrong.
CBC mode ciphers
In the last section we described TLS as a hybrid encryption scheme, with a public key part and a symmetric key part. The public key part is not the only one that has caused trouble over the years. The symmetric key portion has also had its fair share of issues. In any secure communication scheme, you need both encryption (to keep things private) and integrity (to make sure people don’t modify, add, or delete pieces of the conversation). Symmetric key encryption is used to provide both encryption and integrity, but in TLS 1.2 and earlier, these two pieces were combined in the wrong way, leading to security vulnerabilities.
An algorithm that performs symmetric encryption and decryption is called a symmetric cipher. Symmetric ciphers usually come in two main forms: block ciphers and stream ciphers.
A stream cipher takes a fixed-size key and uses it to create a stream of pseudo-random data of arbitrary length, called a key stream. To encrypt with a stream cipher, you take your message and combine it with the key stream by XORing each bit of the key stream with the corresponding bit of your message.. To decrypt, you take the encrypted message and XOR it with the key stream. Examples of pure stream ciphers are RC4 and ChaCha20. Stream ciphers are popular because they’re simple to implement and fast in software.
A block cipher is different than a stream cipher because it only encrypts fixed-sized messages. If you want to encrypt a message that is shorter or longer than the block size, you have to do a bit of work. For shorter messages, you have to add some extra data to the end of the message. For longer messages, you can either split your message up into blocks the cipher can encrypt and then use a block cipher mode to combine the pieces together somehow. Alternatively, you can turn your block cipher into a stream cipher by encrypting a sequence of counters with a block cipher and using that as the stream. This is called “counter mode”. One popular way of encrypting arbitrary length data with a block cipher is a mode called cipher block chaining (CBC).
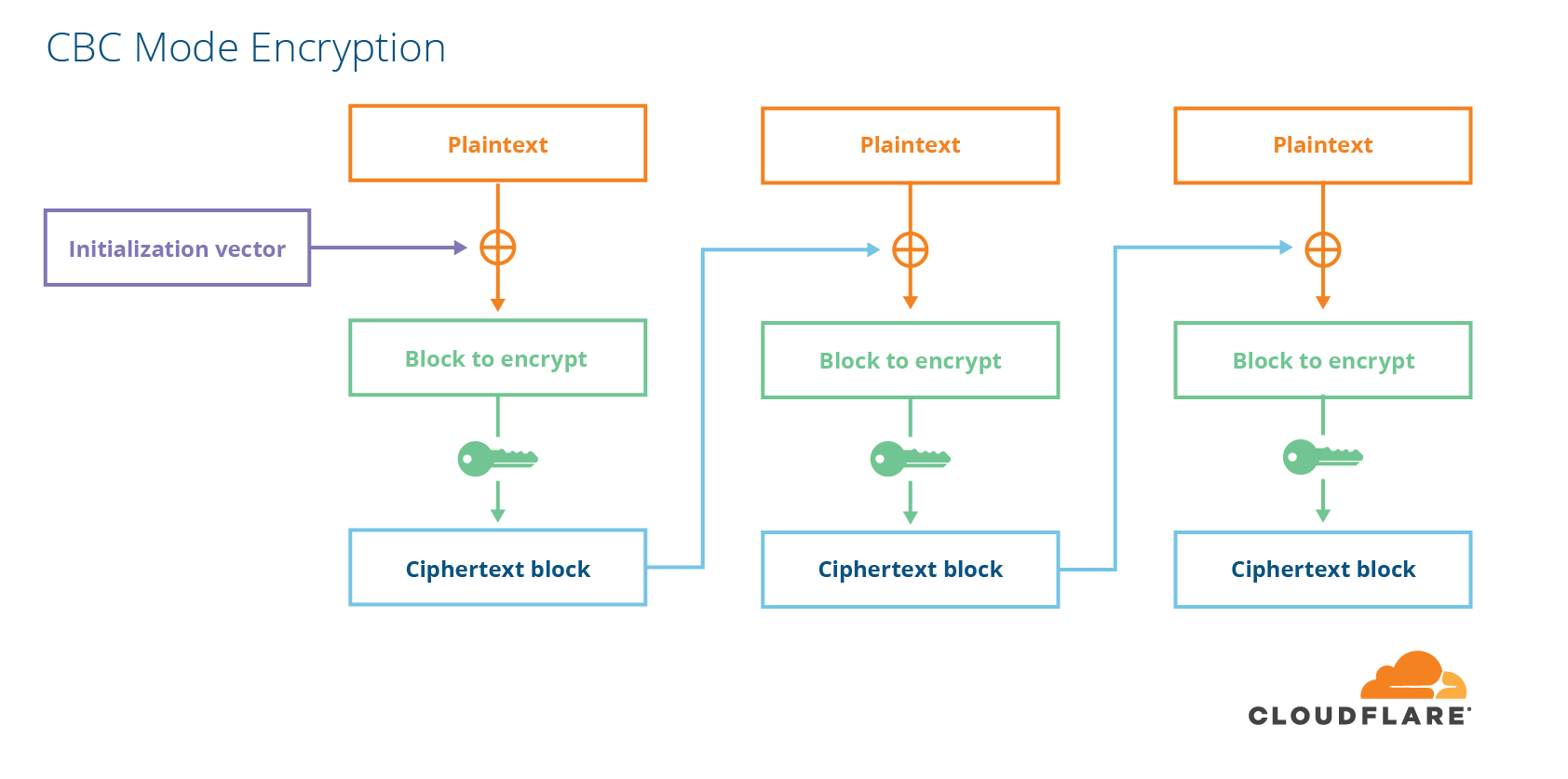
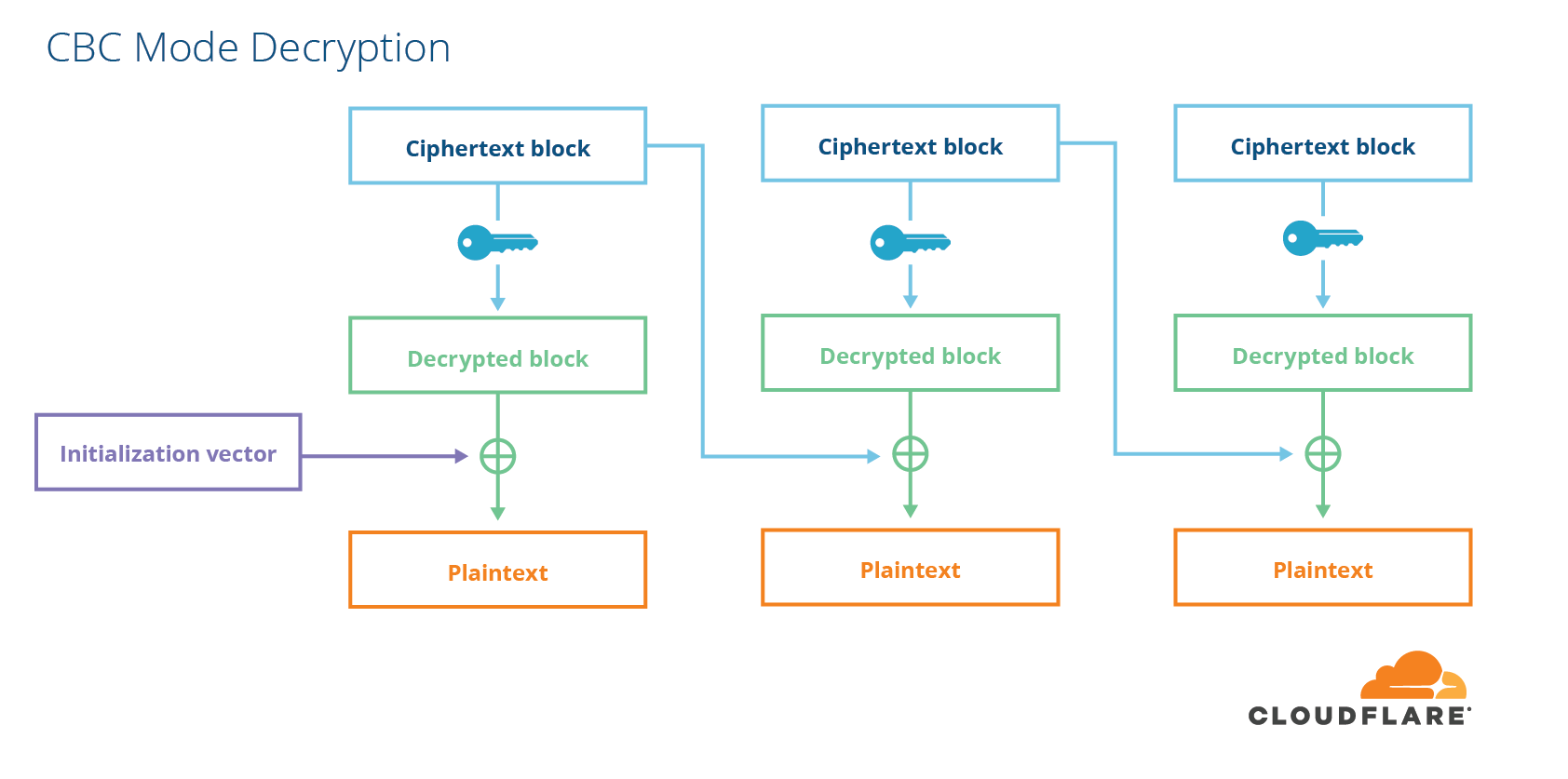
In order to prevent people from tampering with data, encryption is not enough. Data also needs to be integrity-protected. For CBC-mode ciphers, this is done using something called a message-authentication code (MAC), which is like a fancy checksum with a key. Cryptographically strong MACs have the property that finding a MAC value that matches an input is practically impossible unless you know the secret key. There are two ways to combine MACs and CBC-mode ciphers. Either you encrypt first and then MAC the ciphertext, or you MAC the plaintext first and then encrypt the whole thing. In TLS, they chose the latter, MAC-then-Encrypt, which turned out to be the wrong choice.
You can blame this choice for BEAST, as well as a slew of padding oracle vulnerabilities such as Lucky 13 and Lucky Microseconds. Read my previous post on the subject for a comprehensive explanation of these flaws. The interaction between CBC mode and padding was also the cause of the widely publicized POODLE vulnerability in SSLv3 and some implementations of TLS.
RC4 is a classic stream cipher designed by Ron Rivest (the “R” of RSA) that was broadly supported since the early days of TLS. In 2013, it was found to have measurable biases that could be leveraged to allow attackers to decrypt messages.
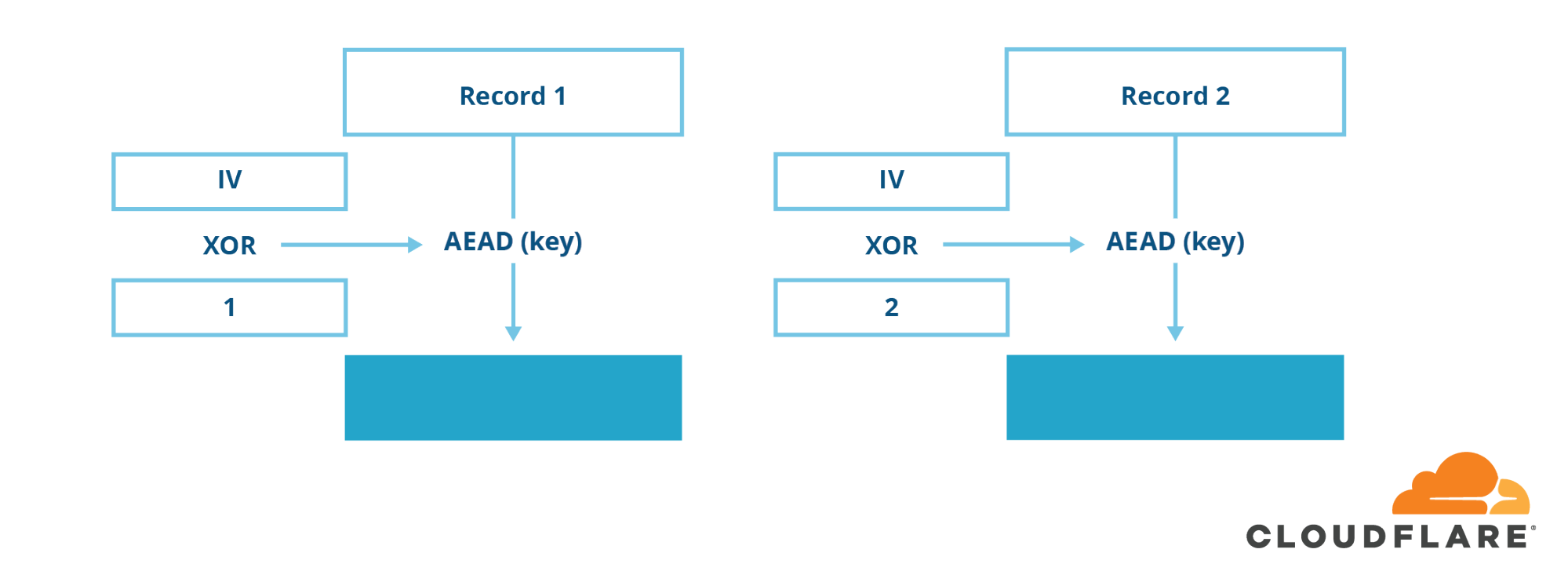
AEAD Mode
In TLS 1.3, all the troublesome ciphers and cipher modes have been removed. You can no longer use CBC-mode ciphers or insecure stream ciphers such as RC4. The only type of symmetric crypto allowed in TLS 1.3 is a new construction called AEAD (authenticated encryption with additional data), which combines encryption and integrity into one seamless operation.
Fixing digital signatures
Another important part of TLS is authentication. In every connection, the server authenticates itself to the client using a digital certificate, which has a public key. In RSA-encryption mode, the server proves its ownership of the private key by decrypting the pre-main secret and computing a MAC over the transcript of the conversation. In Diffie-Hellman mode, the server proves ownership of the private key using a digital signature. If you’ve been following this blog post so far, it should be easy to guess that this was done incorrectly too.
PKCS#1v1.5
Daniel Bleichenbacher has made a living identifying problems with RSA in TLS. In 2006, he devised a pen-and-paper attack against RSA signatures as used in TLS. It was later discovered that major TLS implemenations including those of NSS and OpenSSL were vulnerable to this attack. This issue again had to do with how difficult it is to implement padding correctly, in this case, the PKCS#1 v1.5 padding used in RSA signatures. In TLS 1.3, PKCS#1 v1.5 is removed in favor of the newer design RSA-PSS.
Signing the entire transcript
We described earlier how the server uses a digital signature to prove that the key exchange hasn’t been tampered with. In TLS 1.2 and earlier, the server’s signature only covers part of the handshake. The other parts of the handshake, specifically the parts that are used to negotiate which symmetric cipher to use, are not signed by the private key. Instead, a symmetric MAC is used to ensure that the handshake was not tampered with. This oversight resulted in a number of high-profile vulnerabilities (FREAK, LogJam, etc.). In TLS 1.3 these are prevented because the server signs the entire handshake transcript.
The FREAK, LogJam and CurveSwap attacks took advantage of two things:
- the fact that intentionally weak ciphers from the 1990s (called export ciphers) were still supported in many browsers and servers, and
- the fact that the part of the handshake used to negotiate which cipher was used was not digitally signed.
The on-path attacker can swap out the supported ciphers (or supported groups, or supported curves) from the client with an easily crackable choice that the server supports. They then break the key and forge two finished messages to make both parties think they’ve agreed on a transcript.
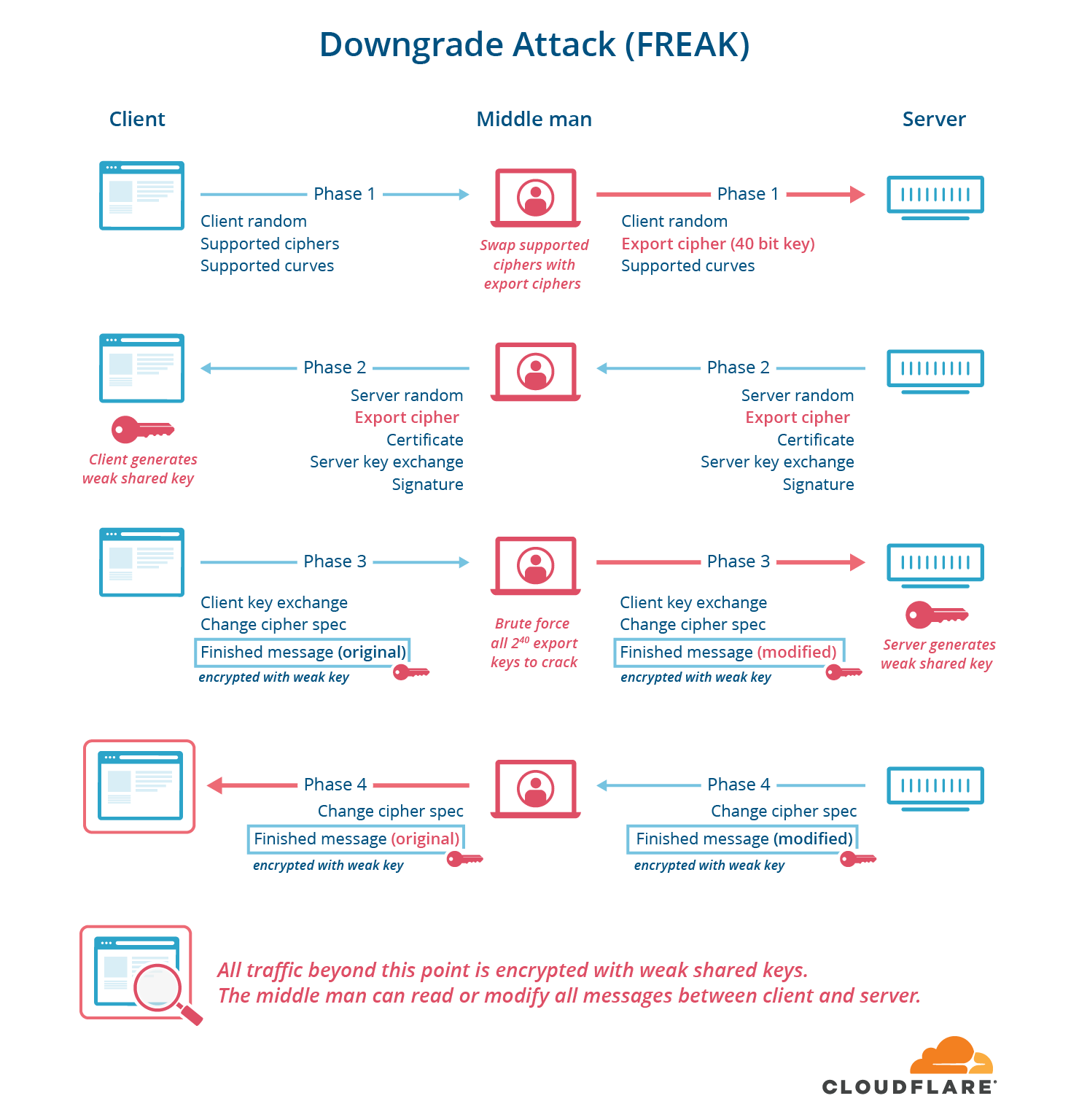
These attacks are called downgrade attacks, and they allow attackers to force two participants to use the weakest cipher supported by both parties, even if more secure ciphers are supported. In this style of attack, the perpetrator sits in the middle of the handshake and changes the list of supported ciphers advertised from the client to the server to only include weak export ciphers. The server then chooses one of the weak ciphers, and the attacker figures out the key with a brute-force attack, allowing the attacker to forge the MACs on the handshake. In TLS 1.3, this type of downgrade attack is impossible because the server now signs the entire handshake, including the cipher negotiation.
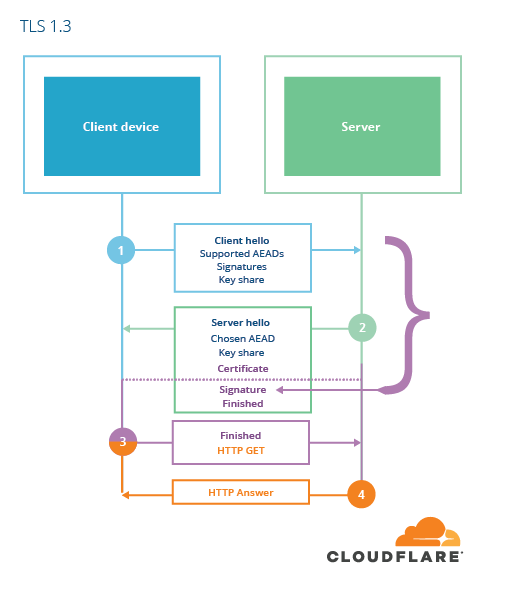
Better living through simplification
TLS 1.3 is a much more elegant and secure protocol with the removal of the insecure features listed above. This hedge-trimming allowed the protocol to be simplified in ways that make it easier to understand, and faster.
No more take-out menu
In previous versions of TLS, the main negotiation mechanism was the ciphersuite. A ciphersuite encompassed almost everything that could be negotiated about a connection:
- type of certificates supported
- hash function used for deriving keys (e.g., SHA1, SHA256, …)
- MAC function (e.g., HMAC with SHA1, SHA256, …)
- key exchange algorithm (e.g., RSA, ECDHE, …)
- cipher (e.g., AES, RC4, …)
- cipher mode, if applicable (e.g., CBC)
Ciphersuites in previous versions of TLS had grown into monstrously large alphabet soups. Examples of commonly used cipher suites are: DHE-RC4-MD5 or ECDHE-ECDSA-AES-GCM-SHA256. Each ciphersuite was represented by a code point in a table maintained by an organization called the Internet Assigned Numbers Authority (IANA). Every time a new cipher was introduced, a new set of combinations needed to be added to the list. This resulted in a combinatorial explosion of code points representing every valid choice of these parameters. It had become a bit of a mess.


TLS 1.3 removes many of these legacy features, allowing for a clean split between three orthogonal negotiations:
- Cipher + HKDF Hash
- Key Exchange
- Signature Algorithm

This simplified cipher suite negotiation and radically reduced set of negotiation parameters opens up a new possibility. This possibility enables the TLS 1.3 handshake latency to drop from two round-trips to only one round-trip, providing the performance boost that will ensure that TLS 1.3 will be popular and widely adopted.
Performance
When establishing a new connection to a server that you haven’t seen before, it takes two round-trips before data can be sent on the connection. This is not particularly noticeable in locations where the server and client are geographically close to each other, but it can make a big difference on mobile networks where latency can be as high as 200ms, an amount that is noticeable for humans.
1-RTT mode
TLS 1.3 now has a radically simpler cipher negotiation model and a reduced set of key agreement options (no RSA, no user-defined DH parameters). This means that every connection will use a DH-based key agreement and the parameters supported by the server are likely easy to guess (ECDHE with X25519 or P-256). Because of this limited set of choices, the client can simply choose to send DH key shares in the first message instead of waiting until the server has confirmed which key shares it is willing to support. That way, the server can learn the shared secret and send encrypted data one round trip earlier. Chrome’s implementation of TLS 1.3, for example, sends an X25519 keyshare in the first message to the server.
In the rare situation that the server does not support one of the key shares sent by the client, the server can send a new message, the HelloRetryRequest, to let the client know which groups it supports. Because the list has been trimmed down so much, this is not expected to be a common occurrence.
0-RTT resumption
A further optimization was inspired by the QUIC protocol. It lets clients send encrypted data in their first message to the server, resulting in no additional latency cost compared to unencrypted HTTP. This is a big deal, and once TLS 1.3 is widely deployed, the encrypted web is sure to feel much snappier than before.
In TLS 1.2, there are two ways to resume a connection, session ids and session tickets. In TLS 1.3 these are combined to form a new mode called PSK (pre-shared key) resumption. The idea is that after a session is established, the client and server can derive a shared secret called the “resumption main secret”. This can either be stored on the server with an id (session id style) or encrypted by a key known only to the server (session ticket style). This session ticket is sent to the client and redeemed when resuming a connection.
For resumed connections, both parties share a resumption main secret so key exchange is not necessary except for providing forward secrecy. The next time the client connects to the server, it can take the secret from the previous session and use it to encrypt application data to send to the server, along with the session ticket. Something as amazing as sending encrypted data on the first flight does come with its downfalls.
Replayability
There is no interactivity in 0-RTT data. It’s sent by the client, and consumed by the server without any interactions. This is great for performance, but comes at a cost: replayability. If an attacker captures a 0-RTT packet that was sent to server, they can replay it and there’s a chance that the server will accept it as valid. This can have interesting negative consequences.
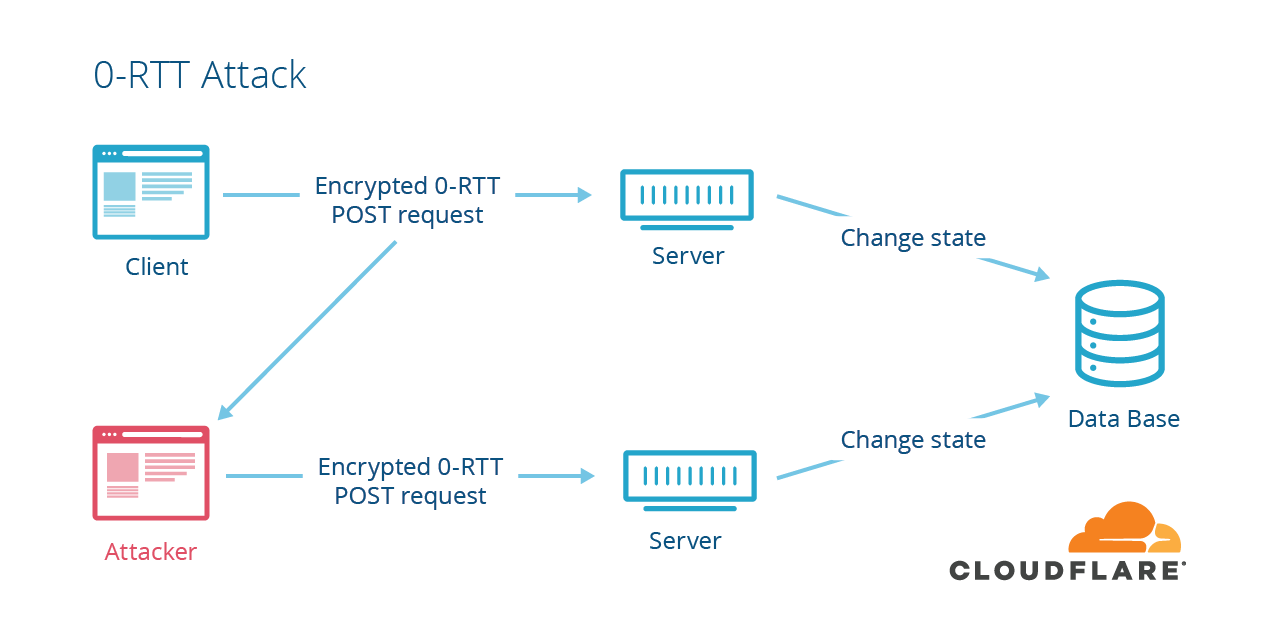
An example of dangerous replayed data is anything that changes state on the server. If you increment a counter, perform a database transaction, or do anything that has a permanent effect, it’s risky to put it in 0-RTT data.
As a client, you can try to protect against this by only putting “safe” requests into the 0-RTT data. In this context, “safe” means that the request won’t change server state. In HTTP, different methods are supposed to have different semantics. HTTP GET requests are supposed to be safe, so a browser can usually protect HTTPS servers against replay attacks by only sending GET requests in 0-RTT. Since most page loads start with a GET of “/” this results in faster page load time.
Problems start to happen when data sent in 0-RTT are used for state-changing requests. To help prevent against this failure case, TLS 1.3 also includes the time elapsed value in the session ticket. If this diverges too much, the client is either approaching the speed of light, or the value has been replayed. In either case, it’s prudent for the server to reject the 0-RTT data.
For more details about 0-RTT, and the improvements to session resumption in TLS 1.3, check out this previous blog post.
Deployability
TLS 1.3 was a radical departure from TLS 1.2 and earlier, but in order to be deployed widely, it has to be backwards compatible with existing software. One of the reasons TLS 1.3 has taken so long to go from draft to final publication was the fact that some existing software (namely middleboxes) wasn’t playing nicely with the new changes. Even minor changes to the TLS 1.3 protocol that were visible on the wire (such as eliminating the redundant ChangeCipherSpec message, bumping the version from 0x0303 to 0x0304) ended up causing connection issues for some people.
Despite the fact that future flexibility was built into the TLS spec, some implementations made incorrect assumptions about how to handle future TLS versions. The phenomenon responsible for this change is called ossification and I explore it more fully in the context of TLS in my previous post about why TLS 1.3 isn’t deployed yet. To accommodate these changes, TLS 1.3 was modified to look a lot like TLS 1.2 session resumption (at least on the wire). This resulted in a much more functional, but less aesthetically pleasing protocol. This is the price you pay for upgrading one of the most widely deployed protocols online.
Conclusions
TLS 1.3 is a modern security protocol built with modern tools like formal analysis that retains its backwards compatibility. It has been tested widely and iterated upon using real world deployment data. It’s a cleaner, faster, and more secure protocol ready to become the de facto two-party encryption protocol online. Draft 28 of TLS 1.3 is enabled by default for all Cloudflare customers, and we will be rolling out the final version soon.
Publishing TLS 1.3 is a huge accomplishment. It is one the best recent examples of how it is possible to take 20 years of deployed legacy code and change it on the fly, resulting in a better internet for everyone. TLS 1.3 has been debated and analyzed for the last three years and it’s now ready for prime time. Welcome, RFC 8446.
from:https://blog.cloudflare.com/rfc-8446-aka-tls-1-3/