Where to buy 🚀 aged domains and backlinks 🔥 from Best-SEO-Domains | 0083-0608
Where to buy 🚀 aged domains and backlinks 🔥 from Best-SEO-Domains | 0083-0608
作者:万金油
链接:https://www.zhihu.com/question/61926374/answer/193032834
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
余额宝的规模越来越大,意味着活期存款乃至定期存款加速向货币基金转移,银行揽储越来越困难,导致银行贷款额度逐渐减少,利率逐渐升高,贷款难的现象越来越普遍。
这个问题其实之前我早已答过,还得了一千六百多赞,说明大家还是比较认可的,可以参考一下。那个回答很短,赶时间的看那个就可以了。https://www.zhihu.com/question/59596175/answer/168438730
但是,那个回答的评论区里,居然有不少人说看不懂!而我自己觉得已经讲得很通俗易懂了。好吧,那我试着说得再浅显一些。
这就不得不写得很长很长了。因为金融专业既然是大学里分数最高的专业之一,那它还是有些门槛的,不是金融经济相关专业出身,又没有专门去学习相关知识,的确不容易搞懂。
我尽量不用术语,不跳步骤,这样一来,答案就没办法简洁了。但是,如果大家看完了,就能顺便补上一些经济金融基础课,所以坚持看完还是有意义的。
言归正传,开始回答问题。
近两年是我国历史上利率最低的时期,没有之一!请看下图。利率是一个体系,市场上有很多很多利率。美国的利率是市场化的,以一年期国债利率为基准。
我国的利率没有实现完全市场化,基准利率是中国人民银行“规定”出来的,以央行存贷款基准利率为代表,基准利率里又以一年期存贷款基准利率为核心。
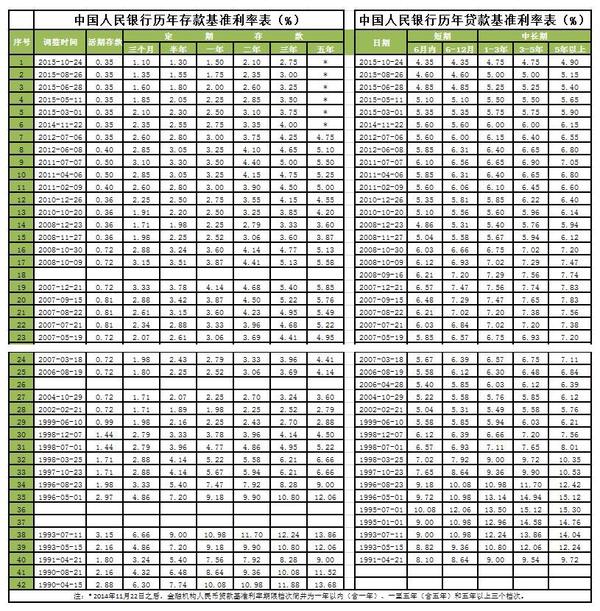
为什么近几年利率如此之低呢?那要从2008年金融危机说起。大家从图表里也可以看出,2007年末,是近十年来利率的最高点,是央行加息降息的分水岭。
金融危机以前,我国经济在高速增长。企业要扩大生产、老百姓要买房买车,钱不够了就向银行去借。股市和债市也能融资,这叫直接融资。但只有小部分大企业才可以,所以主要还是看银行,这叫间接融资。
银行的自有资金很少,绝大部分资金是从老百姓那里借来的,也就是大家说的存款。银行一手从老百姓和企业吸储,一手向企业和老百姓放贷。其实就是资金的中介,所以才叫“间接融资”。贷款多了,存款就不够用了。
这时候怎么办呢?当然是开源节流啊。开源就是增加存款,怎么增加呢?大家都见过,银行以前经常送点米面油、送点小礼品什么的,这样做有点用处,但用处不大,主要还是靠提高存款利率,利率高了,老百姓自然愿意多存款。
节流就是减少贷款。可贷款少了利润也少了。所以银行就提高贷款利率,这样即使贷款少了,利润也不会少很多,甚至还能增加。因为经济在增长,即使贷款利率提高了,企业还是有的赚,利率高一点无所谓。
所以,我们看到08年之前,存贷款利率一直在上升。但是,08年后金融危机来了,事情就不一样了。这是为什么呢?
改革开放后的三十年,我国经济在高速发展。经济学认为,GDP是由消费、投资和净出口(出口减去进口)三个部分组成的。
但是,我国这么快的经济发展,很大程度上,是靠出口和投资带动起来的,而不是像欧美发达国家一样,靠消费带动起来。
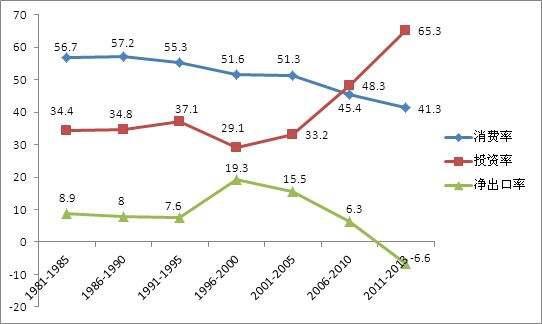
金融危机一来,欧美发达国家经济受到重创,老百姓收入减少了,自然就会减少消费。而欧美发达国家的消费,对应着我国的净出口。
所以,金融危机以后,我国的净出口快速下跌,严重影响了GDP增速。国家的应对措施有两种,一种是扩大消费,一种是扩大投资。我国主要采取了后一种措施。
要扩大消费和投资,降低利率是一种办法。
降低了存款利率,一些老百姓和企业就会觉得把钱存在银行里不划算,不如自己花掉。
降低了借款利率,一些老百姓和企业就会觉得从银行借钱更便宜了,老百姓才会借钱买买买,企业才会借钱买原材料和设备。
于是我们看到08年后,利率在下降。“四万亿”出台后,投资猛增,占比几乎翻倍。而这么多投资,大部分都是银行贷款支撑起来的,到期是要还本付息的。
但是,我们也看到了,很多投资变成了形象工程、变成了各地的鬼城、变成了过剩产能,不能产生效益和利润。也就是说,这些贷款到期以后不仅还不起利息,连本金也还不起,把真金白银打了水漂。
那么该怎么处理呢?如果是民营企业,那就到期不再续贷,要想续贷就得增加抵押或找其他企业担保。
于是,我们看到很多地方,尤其是浙江等民营企业发达的地方,一个企业破产,拖倒了担保链上的几十家健康企业。银行的坏账越来越多。
如果是国企,那地方会想方设法要求银行继续提供贷款。因为一旦企业还不起贷款破产倒闭,那么麻烦就大了。
首先,国企倒闭,GDP就少了,而GDP是官员考核的最关键因素。
其次,国企倒闭,税收就少了,而税收是财政收入的重要组成部分,这也是官员考核的重要因素。
再次,国企倒闭,失业工人很可能会闹事,YX、SW乃至进京SF,导致官员在考核时被一票否决。
所以,地方GY会竭尽所能,请求、诱导、要求、迫使银行继续贷款给国企。
如果是地方ZF,那银行就更不敢得罪了。几年前地方ZF自己、或者其下属的各种城投企业从银行贷了很多款,利率也不低,因为最低也不能低过贷款基准利率。
但是,几年后贷款到期时地方ZF还不起贷款了,中央ZF没办法,要求银行把贷款置换为地方债。也就是说,银行以高利率放出的贷款变成了利率不到3%的债券,其中的差额都是损失。
于是,这几年我们看到,银行的利润增速从百分之几十到现在的接近零点,坏账越来越多。
但是,借新还旧不能解决问题,其实是把雪球滚得越来越大,让问题越来越难以解决。这些钱究竟最后怎么还呢?中央ZF的办法是用放水来稀释债务。
老百姓以为放水就是印钞票,其实不是。因为在货币供应里,印钞票只占极小部分。现钞在金融学的叫M0,只是冰山一角,而这座大冰山,专业的说法叫M2。
下面是中国的M2与几个发达国家的对比。大家可以看到,中国的M2在08年之前就很多,08年之后更是飞速增长。
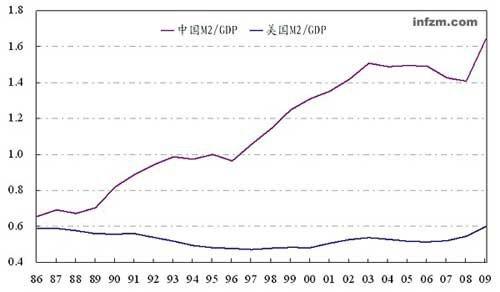
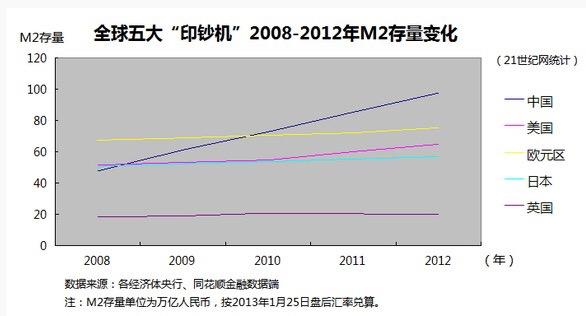
说白了,货币与经济是水和面的关系,经济发展了就得多发货币,好比面多了就得加水。如果经济没怎么发展,却大规模放水,那么面就稀了。
面稀了,对内就是通货膨胀,老百姓存进银行一碗面,拿回来时只剩半碗面半碗汤了。这就相当于,企业和政府欠的债,有一大块不用还了,这块损失,让存款的老百姓承担了。
面稀了,对外就是货币贬值。之前,中国为了促进出口,认为压低人民币汇率。所以美国经常指责中国操纵人民币汇率不正当竞争。
经过几年的暗中贬值,不但之前人为压低的那部分没有了,还让人民币汇率高估了。再加上美国央行不再大规模放水,反而打算开始从市场上抽水,使得美元汇率升高。
这一里一外,让大家对人民币的实际购买力越来越没有信心,认为人民币汇率早晚会下跌很多,所以越来越多地把人民币换成外汇,使得外汇储备越来越少。
中国的外汇储备在2014年中达到最高点3.99万亿美元,一年半后就跌到接近3万亿。要知道,中国一年的顺差就有三千几百亿美元呢。
这三年来,不仅存量少了1万亿美元,三年的进出口顺差也有1万亿美元,也就是说,实际上,三年来外汇储备就少了四成。这还是最近两年来,ZF想方设法、围追堵截才达到的,不然外汇流失会更多。
外汇储备的大量流失让央行不能继续大规模放水了,否则外汇储备就撑不住了。于是,我们看到,最近几个月的M2增速越来越低,从08年的27%,到现在的个位数。
M2少了,就意味着银行不能像以前一样,从央行那里借到便宜的钱了。从老百姓那里吸储也不容易,因为利率那么低,老百姓也不是傻子,不愿意挨宰,更愿意把钱拿出来买房子来抵消通货膨胀。
于是银行只能跟同业去借钱,同业市场的利率不受央行控制,很快就升高了。在同业市场,银行们主要是借款的一方,那贷款的一方是谁呢?正是货币基金,也就是老百姓常说的各种“宝宝”们。
货币基金给银行的贷款利率越来越高,利润越来越多,自然能支付起越来越高的利息给老百姓,所以大家都越来越愿意把钱放在余额宝里,使得余额宝的规模越来越大。
这其中的关键就是,央行不去管制同业利率,而去管制基准利率。那为什么央行不去管制同业利率呢?如果把同业利率降低到基准利率的水平,那货币基金就没有什么收益,自然不能吸引老百姓的存款了。
这是因为同业市场是金融机构之间调剂余缺的地方,如果把同业利率强行降低,那么资金富裕的金融机构就不愿意把钱借给资金紧张的金融机构了。
老百姓自己资金周转不过来时得去借钱,金融机构也一样啊,万一真的周转不过来那是会引发违约、挤兑乃至倒闭的,所以央行不敢这么做。
那央行能不能把基准利率提高到同业利率的水平呢,那这样货币基金对银行存款就没什么优势了。
这样也不行。因为那么已经借了很多钱的企业和政府ZF会受不了。因为他们中的很多,不仅还不起本金,连利息也快还不起了。
不仅是企业,近几年全民炒房,很多个人身上也背着贷款,一旦利率快速上升,那么很可能还不上月供。
有些人可能说,我就一套房子,利息翻一倍也还的上。但是,架不住有很多人手里有多套房子啊,一旦利率快速上升,他们很难还得起,必然要卖房还贷。
这样的人不需要很多,一个小区里有几个快速卖房的业主,那么整个小区的价格都会被这几套房的交易价格拉下来。房价下跌后,总有人会恐慌性卖房,把房价拉得更低。
即使没有恐慌性卖房,房价下跌一定程度后,银行也会要求贷款客户尽快增加抵押和担保,拿不出足够的抵押和担保就得卖房。所以最近各大城市都开始“限售”,就是害怕出现连锁反应和踩踏事件。
所以个人、企业、ZF,都害怕利率升高。之前还能借新还旧、勉强维持,一旦提高基准利率,那利息都还不起了,很快就会违约。银行的坏账一下子就会爆发。
金融是经济的中枢,银行是金融的中枢,一旦银行坏账大规模爆发,那么整个经济都要出大乱子,难以收拾。
但是,不加息提高利率是不大可能的,因为外汇储备是命根子,必须得保住。极端情况下,如果外汇储备低到了一定水平,宁可加息刺破泡沫也要保住外汇储备。为什么说外汇储备如此重要,一定要保住呢?
因为我国是大国中外贸依存度最高的国家,高达60%,世所罕见,庞大的进口规模需要足够的外汇储备。没有外汇储备就不能进口。
老百姓没有日本纸尿裤、法国化妆品、不去美国旅游、不去澳洲留学,依然能好好过日子,但粮食、石油、芯片这三大类是一定要有的。
2014年中国的粮食自给率是87%,农产品自给率是70%,乍看不低,但这是用极高的粮食收购价格给农民补贴得到的。2014年我国四种谷物价格平均高于国际市场一半。也就是说,我国是靠花大价钱来保证粮食供应的。
有人说,就算是花了大价钱,但我国的粮食还是能基本维持自给的。但是,不要忘了吃肉。公认的肉粮比是六比一以上,也就是说,肉价得高过粮价六倍以上才行。我国的粮食产量只能保证老百姓吃粮,近几年来,肉类进口规模越来越大。
根据JCI统计数据显示,受肉类总产量下降影响,2016年我国肉品实际进口总量首次超过450万吨,同比增幅超过68.7%,而2010年到2016年肉品进口总量年平均增速为19.7%。除去进口肉品外,活猪/禽类冻品/冷冻猪、牛肉等走私产品,“明目张胆”的越过海关、边检等进入中国市场。按照业内的保守估计,走私肉品的数量保守估计应是正规进口数量的2~3倍,而实际走私肉品数量可能更多。
中国两大油田2016年大量减产,国内石油对外依存度升至65%,天然气对外依存度升至34.9%。石油是工业的血液,没了石油后果不堪设想。况且中国的农业已经是石油农业,没了石油,化肥农药也产不出来。
我国的机电行业出口是最大一块,但是其中离不开芯片进口,而我国的芯片进口率已经超过90%。其他的问题,忍忍就过去了,外汇储备如果耗竭,危及粮食、石油、芯片进口,那中国经济真要崩溃了。
所以中国要保外汇储备,不得不停止大规模放水,怕利率升高刺破经济泡沫,又不敢快速加息,让基准利率跟上同业利率这个中国最真实的利率。
这其中的不对称,让银行最难受。银行也不愿意做亏本生意啊。存款基准利率太低,储蓄上不来,银行就加大理财产品的发售力度。因为理财产品的利率不受央行管控。
但是,近几年来,银监会对理财产品的发行和投向有了越来越越严格的规定,特别是今年以来。
存款不够,贷款就不好做,银行只能收紧贷款额度,提高贷款利率。银行对企业的贷款利率早就提高了,只是老百姓不知道而已,因为这个利率不是统一的,而是每家企业都不一样。
最近几个月,老百姓发现个人住房贷款很难办,利率也提高了,这才意识到贷款利率真的提高了。
银行对企业对个人的贷款都难做,但是又要考核利润。只能从其他地方想办法。于是就借助证券公司、信托公司、基金子公司等资产管理公司作为通道,把资金包装成千奇百怪的产品发售出去。
这样做有很多好处。
首先,银行贷款受到的监管是最严格的,把贷款包装成其他产品,就能够逃避银监会的严格管制,把款放给不能放贷的企业。
其次,银行发放贷款是要消耗资本金的,资本金不够了,存款再多也不能拿出去放贷。包装以后,就能“出表”,不受严格监管了。
再次,银行发放贷款是有风险的,企业还不上贷款银行也难受。银行借助其他金融机构做通道,一方面给了通道机构服务费,另一方面也让这些通道机构承担了相应的风险。一旦出事,倒霉的是通道机构,银行不受影响。
于是,各家银行都开始拼命做“包装”业务,银行包装一次不够,通道机构就继续包装。本来只有银行到企业一个环节,现在却层层嵌套,七八个环节也不稀奇。于是就出现了所谓的“资金空转”。
即使这样,银行还是不能弥补利率不对称给自己带来的损失,怎么办呢?大家都找银行借钱放杠杆,银行自己也可以啊!
本来一项业务只有1%的利润,不值得做,但是,加上十倍的杠杆,就有10%的利润了,如果还不够,那就再加杠杆,这样别说是1%利润率的业务了,0.1%的业务也能做。
这样一来,一边是环节越来越多,一边是杠杆越来越大,积累的风险就越来越不可控。一旦有一个点出了问题,很快就会层层传染,层层放大,最终殃及整个金融体系。
所以今年四月份以来,银监会开始了史上最严格的监管,因为,金融体系里的黑洞越来越大,再不管的话,以后就无法收拾了。
不过,这样做不能解决根本的问题。银行是要盈利的,不给银行开正门,银行就得走后门。加强监管只是扬汤止沸,不是釜底抽薪。根子还是在基准利率上。
美国已经开始加息缩表,并将继续加息缩表。中国要想维持外汇储备和人民币汇率,就得跟上美国的步伐,不仅提高银行间市场的利率,还要提高基准利率。
如果美国走得慢,中国就能慢慢加息,老百姓、企业、ZF就还有慢慢适应的余地。如果美国走得快,中国就麻烦了。一旦出麻烦,谁也不想背黑锅。
ZXC先生明年就要退休了,这半年他肯定不想给自己找麻烦,何况还有秋天的那场重大会议,更不能出乱子,所以只能慢慢来。
但是,现在越慢以后问题越难解决。现在我们只能,一方面加强外汇管制,阻止资本外逃,另一方面,祈祷美国人慢点走,给中国留出充裕的时间来。
