All posts by dotte
北京市义务教育 入学服务平台
http://yjrx.bjedu.cn/
海淀幼儿园
清河街道幼儿园:hdqhschool
| 幼儿园 | 电话 | 学费 | 地点 | 距离 | 情况 |
| 锦顺幼儿园(公) | 62915702 | 锦顺园 | 0.95 | 9月1号后联系,希望不太大 | |
| 美和幼儿园(公) | 82170611-611 | 美和园 | 1 | 9月1号后联系,希望不太大 | |
| 汇佳上第摩码幼儿园 | 82759510-801 | 上第Moma | 1.1 | 无名额,放弃 | |
| 21世纪 | 82731360 | 3000多 | 上林溪 | 1.1 | 回来之后电话联系是否还有名额 |
| 中国音乐学院附属艺术幼儿园清上园 | 82728559 | 4800 | 清上园 | 1.4 | 无名额,9月1号后联系 |
| 北京市幼儿师范学校附属幼儿园 | 62951104 | 3200 | 阳光北里 | 1.8 | 无外教 |
| 总装备部后勤部小营幼儿园(公) | 毛纺里小区 | 1.5 | 9月1号后联系,希望不太大 | ||
| 明天幼稚集团第九幼儿园分院(公) | 62932393 | 安宁里9号 | 1.4 | ||
| 睿泽幼儿园 | 60606068-616 | 2350 | 安宁家园1号楼 | 2.1 | 有名额 |
| 芳草国际幼儿园 | 13716586011 | 1900 | 通夏花卉市场内 | 3.4 | 有名额 |
| 凯蒂幼儿园 | 58465556 | 领袖硅谷 | 打不通 |
| 1 | 明天九幼安宁里园 | 北京市市辖区海淀区清河街道清河安宁里小区9号楼 | 教育部门办 |
| 2 | 明天九幼锦顺园 | 北京市市辖区海淀区清河街道安宁庄西路锦顺佳园小区 | 教育部门办 |
| 3 | 北京市海淀区美和园幼儿园(智学苑分园) | 北京市市辖区海淀区清河街道西二旗智学苑小区 | 教育部门办 |
| 4 | 中国人民解放军空军装备研究院蓝天幼儿园 | 北京市市辖区海淀区清河街道安宁庄路11号院内 | 单位办 |
| 5 | 中国人民解放军火箭军机关幼儿园 | 北京市市辖区海淀区清河街道清河小营30号院 | 单位办 |
| 6 | 北京市幼儿师范学校附属幼儿园 | 北京市市辖区海淀区清河街道清河小营阳光北里1号 | 民办 |
| 7 | 北京市海淀区凯蒂幼儿园 | 北京市市辖区海淀区清河街道西二旗西路2号院86号楼 | 民办 |
| 8 | 中国人民解放军总装备部后勤部小营幼儿园 | 北京市市辖区海淀区清河街道清河安宁庄东路28号院5号楼 | 单位办 |
| 9 | 北京市海淀区领秀硅谷凯尔宝宝婴幼园 | 北京市市辖区海淀区清河街道西二旗中路6号院(领秀硅谷社区)A区6号楼 | 民办 |
| 10 | 北京市海淀区美和园幼儿园 | 北京市市辖区海淀区清河街道清河小营西路48号 | 教育部门办 |
| 11 | 北京市海淀区智合国学双语幼儿园 | 北京市市辖区海淀区清河街道清河镇清缘东里3号楼 | 民办 |
| 12 | 北京市海淀区上林溪二十一世纪实验幼儿园 | 北京市市辖区海淀区清河街道安宁庄路安宁华庭一区11号楼 | 民办 |
海淀其他 hdschool:
| 1 | 中国人民解放军后勤学院幼儿园 | 北京市市辖区海淀区万寿路街道北京市海淀区太平路23号西南角 | 单位办 |
| 2 | 住房和城乡建设部幼儿园 | 北京市市辖区海淀区甘家口街道三里河路9号院 | 单位办 |
| 3 | 核工业第二研究设计院幼儿园 | 北京市市辖区海淀区八里庄街道马神庙一号 | 单位办 |
| 4 | 明天一幼塔院 | 北京市市辖区海淀区花园路街道塔院小区迎春园甲7号 | 教育部门办 |
| 5 | 北京师范大学实验幼儿园世华龙樾分园 | 北京市市辖区海淀区东升地区文龙家园三里8号楼 | 单位办 |
| 6 | 首都师范大学附属幼儿园 | 北京市市辖区海淀区八里庄街道西三环北路105号 | 单位办 |
| 7 | 北京市海淀区北部新区苏家坨艺术幼儿园 | 北京市市辖区海淀区苏家坨镇北京市海淀区苏家坨镇柳林村河北三区62号 | 单位办 |
| 8 | 明天二幼双榆树园 | 北京市市辖区海淀区中关村街道双榆树东里36号 | 教育部门办 |
| 9 | 明天三幼志强园 | 北京市市辖区海淀区北太平庄街道新外大街志强园小区 | 教育部门办 |
| 10 | 明天三幼学院路园 | 北京市市辖区海淀区北太平庄街道蓟门里小区 | 教育部门办 |
| 11 | 明天四幼知春里园 | 北京市市辖区海淀区中关村街道海淀区双榆树北路63号 | 教育部门办 |
| 12 | 明天五幼万泉河园 | 北京市市辖区海淀区海淀街道稻香园小区 | 教育部门办 |
| 13 | 明天五幼东升园 | 北京市市辖区海淀区东升地区五道口东升园公寓5号楼 | 教育部门办 |
| 14 | 明天六幼金沟河园 | 北京市市辖区海淀区田村路街道金沟河路3号院 | 教育部门办 |
| 15 | 明天六幼小灵通园 | 北京市市辖区海淀区田村路街道采石路1号玉海园五里21号 | 教育部门办 |
| 16 | 明天七幼定西园 | 北京市市辖区海淀区八里庄街道定慧西里19号 | 教育部门办 |
| 17 | 明天七幼百合花园 | 北京市市辖区海淀区紫竹院街道车道沟南里小区 | 教育部门办 |
| 18 | 明天七幼沙沟园 | 北京市市辖区海淀区万寿路街道万寿路1号院 | 教育部门办 |
| 19 | 明天八幼上地园 | 北京市市辖区海淀区上地街道上地东里小区一区 | 教育部门办 |
| 20 | 明天八幼佳园园 | 北京市市辖区海淀区上地街道上地佳园22号楼 | 教育部门办 |
| 21 | 明天九幼永泰园 | 北京市市辖区海淀区西三旗街道永泰东里48号 | 教育部门办 |
| 22 | 明天九幼安宁里园 | 北京市市辖区海淀区清河街道清河安宁里小区9号楼 | 教育部门办 |
| 23 | 明天九幼锦顺园 | 北京市市辖区海淀区清河街道安宁庄西路锦顺佳园小区 | 教育部门办 |
| 24 | 明天十幼铁路园 | 北京市市辖区海淀区羊坊店街道双贝子坟3号 | 教育部门办 |
| 25 | 中国人民解放军93462部队幼儿园 | 北京市市辖区海淀区西三旗街道建材城西路85号院 | 单位办 |
| 26 | 北京市海淀区美和园幼儿园(智学苑分园) | 北京市市辖区海淀区清河街道西二旗智学苑小区 | 教育部门办 |
| 27 | 北京林业大学幼儿园 | 北京市市辖区海淀区学院路街道清华东路35号 | 单位办 |
| 28 | 北京市海淀区本真双语艺术幼稚园 | 北京市市辖区海淀区学院路街道学院路二里庄小区 | 民办 |
| 29 | 北京邮电大学幼儿教育中心 | 北京市市辖区海淀区北太平庄街道西土城路10号 | 单位办 |
| 30 | 北京市海淀区现代艺术幼儿园 | 北京市市辖区海淀区北太平庄街道知春路罗庄西里七号 | 民办 |
| 31 | 中国人民解放军空军装备研究院蓝天幼儿园 | 北京市市辖区海淀区清河街道安宁庄路11号院内 | 单位办 |
| 32 | 北京市海淀外国语学校附属幼儿园 | 北京市市辖区海淀区四季青镇杏石口路20号 | 民办 |
| 33 | 中国航空工业集团公司北京航空材料研究院幼儿园 | 北京市市辖区海淀区温泉镇环山村 | 单位办 |
| 34 | 北京育新实验幼儿园 | 北京市市辖区海淀区西三旗街道育新花园22号 | 单位办 |
| 35 | 北京市海淀区北太平庄街道蓟门里幼儿园 | 北京市市辖区海淀区北太平庄街道学院路蓟门里小区甲1号 | 单位办 |
| 36 | 中国人民解放军总参谋部军训部机关第二幼儿园 | 北京市市辖区海淀区万寿路街道复兴路24号院 | 单位办 |
| 37 | 中国科学院第七幼儿园 | 北京市市辖区海淀区马连洼街道天秀花园古月园内 | 单位办 |
| 38 | 北京市海淀区英才美丽园幼儿园 | 北京市市辖区海淀区八里庄街道五棵松路20号 | 民办 |
| 39 | 航天机关幼儿园 | 北京市市辖区海淀区甘家口街道阜成路8号 | 单位办 |
| 40 | 中国农业大学东校区幼儿园 | 北京市市辖区海淀区学院路街道清华东路17号185信箱 | 单位办 |
| 41 | 北京岭南幼儿园 | 北京市市辖区海淀区八里庄街道恩济庄小区定慧东里34号 | 民办 |
| 42 | 中国农业大学西校区幼儿园 | 北京市市辖区海淀区马连洼街道圆明园西路3号院 | 单位办 |
| 43 | 中国人民解放军63919部队幼儿园 | 北京市市辖区海淀区马连洼街道圆明园西路1号 | 单位办 |
| 44 | 北京市海淀区海淀镇青龙桥幼儿园 | 北京市市辖区海淀区青龙桥街道万寿山后身25号 | 单位办 |
| 45 | 北京市海淀区海淀乡中心幼儿园 | 北京市市辖区海淀区万柳地区北京市海淀区厢黄旗东路柳浪家园小区 | 单位办 |
| 46 | 北京语言大学幼儿园 | 北京市市辖区海淀区学院路街道学院路15号 | 单位办 |
| 47 | 北京市海淀区四季青镇巨山幼儿园 | 北京市市辖区海淀区四季青镇田村北路101号体育馆西侧A4栋 | 单位办 |
| 48 | 北京市海淀区长河湾汇佳幼儿园 | 北京市市辖区海淀区北下关街道高粱斜街59号 | 民办 |
| 49 | 中国人民解放军总后勤部五一幼儿园 | 北京市市辖区海淀区万寿路街道太平路31号 | 单位办 |
| 50 | 北京交通大学幼儿园 | 北京市市辖区海淀区北下关街道高粱桥斜街44号 | 单位办 |
| 51 | 中国人民武装警察部队总部机关幼儿园 | 北京市市辖区海淀区海淀街道万泉庄16号楼 | 单位办 |
| 52 | 北京市海淀区世纪新汇佳幼儿园 | 北京市市辖区海淀区曙光街道蓝靛厂西路3号 | 民办 |
| 53 | 中共中央办公厅警卫局万寿路幼儿园 | 北京市市辖区海淀区万寿路街道万寿路甲5号2号院 | 单位办 |
| 54 | 中国人民解放军国防大学第二幼儿园 | 北京市市辖区海淀区万寿路街道复兴路83号 | 单位办 |
| 55 | 北京市海淀区中科幼教中关村实验幼儿园 | 北京市市辖区海淀区中关村街道中国科学院东南小区西区甲932幢 | 民办 |
| 56 | 北京市六一幼儿院 | 北京市市辖区海淀区万柳地区青龙桥六间房一号 | 教育部门办 |
| 57 | 北京市六一幼儿院西山庭院院区 | 北京市市辖区海淀区马连洼街道肖家河桥天秀路西山庭院 | 教育部门办 |
| 58 | 北京市六一幼儿院西三旗院区 | 北京市市辖区海淀区西三旗街道建材城翡丽铂庭三区 | 教育部门办 |
| 59 | 北京市海淀区英才幼儿园 | 北京市市辖区海淀区学院路街道北四环中路志新村小区12号 | 民办 |
| 60 | 中国科学院第一幼儿园 | 北京市市辖区海淀区中关村街道中关村科源社区24号楼旁 | 单位办 |
| 61 | 中国科学院第一幼儿园北斗分园 | 北京市市辖区海淀区西北旺镇北清路22号 | 单位办 |
| 62 | 北京市海淀区北太平庄街道威凯幼儿园 | 北京市市辖区海淀区北太平庄街道红联南村3号 | 单位办 |
| 63 | 总参谋部测绘导航局幼儿园 | 北京市市辖区海淀区花园路街道北三环中路69号中四楼中五楼 | 单位办 |
| 64 | 北京市海淀区四季青镇北坞幼儿园 | 北京市市辖区海淀区四季青镇北坞嘉园南里37号楼 | 单位办 |
| 65 | 北京市海淀区恩济里幼儿园 | 北京市市辖区海淀区八里庄街道恩济里小区10号 | 教育部门办 |
| 66 | 北京市海淀区红缨幼儿园 | 北京市市辖区海淀区马连洼街道农大北路百旺家苑西区39号 | 民办 |
| 67 | 北京市海淀区万泉汇佳幼儿园 | 北京市市辖区海淀区海淀街道巴沟南路35号万泉新新家园13号楼 | 民办 |
| 68 | 中国科学院第三幼儿园 | 北京市市辖区海淀区中关村街道中关村南一街2号 | 单位办 |
| 69 | 中国科学院第三幼儿园杏林湾分园 | 北京市市辖区海淀区西北旺镇北清路永丰嘉园三区32号 | 单位办 |
| 70 | 中国科学院幼儿园 | 北京市市辖区海淀区中关村街道中关村北二条水清木华园小区七号楼 | 单位办 |
| 71 | 中国人民解放军总参谋部军训部机关第三幼儿园 | 北京市市辖区海淀区万寿路街道玉泉路68号院 | 单位办 |
| 72 | 北京师范大学实验幼儿园 | 北京市市辖区海淀区北太平庄街道新街口外大街19号 | 单位办 |
| 73 | 北京师范大学实验幼儿园牡丹分园 | 北京市市辖区海淀区花园路街道牡丹园东里18号 | 民办 |
| 74 | 中国音乐学院附属艺术幼儿园 | 北京市市辖区海淀区八里庄街道西八里庄北里15号 | 单位办 |
| 75 | 中国音乐学院附属艺术幼儿园健翔园分园 | 北京市市辖区海淀区学院路街道北四环中路209号健翔园 | 单位办 |
| 76 | 北京有色金属研究总院幼儿园 | 北京市市辖区海淀区北太平庄街道新街口外大街3号 | 单位办 |
| 77 | 北京市二十一世纪实验幼儿园 | 北京市市辖区海淀区八里庄街道恩济庄46号 | 民办 |
| 78 | 北京市海淀区人民政府机关幼儿园 | 北京市市辖区海淀区中关村街道知春东里14号 | 单位办 |
| 79 | 中国气象局幼儿园 | 北京市市辖区海淀区北下关街道北京市海淀区中关村南大街46号 | 单位办 |
| 80 | 北京市海淀区四季青香山幼儿园 | 北京市市辖区海淀区四季青镇香山普安店240号 | 单位办 |
| 81 | 北京市世纪阳光幼儿园 | 北京市市辖区海淀区曙光街道板井路73号 | 民办 |
| 82 | 中国人民解放军63921部队幼儿园 | 北京市市辖区海淀区西北旺镇北清路26号院 | 单位办 |
| 83 | 中国人民解放军火箭军机关幼儿园 | 北京市市辖区海淀区清河街道清河小营30号院 | 单位办 |
| 84 | 中国人民解放军总参谋部信息化部幼儿园 | 北京市市辖区海淀区万寿路街道复兴路20号 | 单位办 |
| 85 | 中国林业科学研究院幼儿园 | 北京市市辖区海淀区青龙桥街道颐和园后东小府1号 | 单位办 |
| 86 | 中国人民解放军63916部队幼儿园 | 北京市市辖区海淀区甘家口街道阜成路26号 | 单位办 |
| 87 | 北京市清华洁华幼儿园 | 北京市市辖区海淀区清华园街道清华大学院内 | 单位办 |
| 88 | 中国人民解放军国防大学第一幼儿园 | 北京市市辖区海淀区青龙桥街道红山口甲三号国防大学院内 | 单位办 |
| 89 | 空军95968部队幼儿园 | 北京市市辖区海淀区四季青镇昆明湖南路甲7号院内 | 单位办 |
| 90 | 中国人民解放军军事医学科学院幼儿园 | 北京市市辖区海淀区万寿路街道太平路27号 | 单位办 |
| 91 | 中国人民解放军总参谋部军训部机关第一幼儿园 | 北京市市辖区海淀区万寿路街道复兴路26号院 | 单位办 |
| 92 | 空军指挥学院蓝天幼儿园 | 北京市市辖区海淀区曙光街道北四环西路88号院 | 单位办 |
| 93 | 中国人民解放军61886部队幼儿园 | 北京市市辖区海淀区上地街道上地信息路33号院 | 单位办 |
| 94 | 北京航空航天大学幼儿园 | 北京市市辖区海淀区花园路街道学院路37号 | 单位办 |
| 95 | 北京大学医学部幼儿园 | 北京市市辖区海淀区花园路街道学院路38号 | 单位办 |
| 96 | 北京市海淀区小汉顿幼儿园 | 北京市市辖区海淀区海淀街道苏州街3号大河庄苑8号楼 | 民办 |
| 97 | 北京市幼儿师范学校附属幼儿园 | 北京市市辖区海淀区清河街道清河小营阳光北里1号 | 民办 |
| 98 | 北京市海淀区布朗幼儿园 | 北京市市辖区海淀区紫竹院街道魏公村街1号韦伯豪家园10号楼 | 民办 |
| 99 | 北京市海淀区美华彩苑外国语幼儿园 | 北京市市辖区海淀区四季青镇北坞村路23号 | 民办 |
| 100 | 北京市海淀区凯蒂幼儿园 | 北京市市辖区海淀区清河街道西二旗西路2号院86号楼 | 民办 |
| 101 | 北京市海淀区锦绣明天莲宝幼儿园 | 北京市市辖区海淀区羊坊店街道吴家村路10号院甲1号楼 | 民办 |
| 102 | 北京市海淀区上庄科技园区幼儿园 | 北京市市辖区海淀区上庄镇沙阳路临6号 | 教育部门办 |
| 103 | 北京市海淀区立新幼儿园 | 北京市市辖区海淀区田村路街道田村砂石厂路柳明家园西区 | 教育部门办 |
| 104 | 北京市海淀区立新幼儿园(环保园) | 北京市市辖区海淀区温泉镇阅西山家园小区 | 教育部门办 |
| 105 | 北京市海淀区启明华清幼儿园 | 北京市市辖区海淀区中关村街道五道口华清嘉园11号 | 民办 |
| 106 | 钢铁研究总院幼儿园 | 北京市市辖区海淀区北下关街道学院南路76号 | 单位办 |
| 107 | 北京馨星幼儿园 | 北京市市辖区海淀区四季青镇香山南路 | 单位办 |
| 108 | 中国农业科学院幼儿园 | 北京市市辖区海淀区北下关街道中关村南大街12号 | 单位办 |
| 109 | 中国铁道科学研究院幼儿园 | 北京市市辖区海淀区北下关街道海淀区西直门外大柳树路2号 | 单位办 |
| 110 | 海军机关幼儿园 | 北京市市辖区海淀区羊坊店街道西三环中路19号海军大院西门南侧 | 单位办 |
| 111 | 北京市海淀区太阳幼儿园 | 北京市市辖区海淀区中关村街道大钟寺太阳园7号楼 | 民办 |
| 112 | 北京五色土实验婴幼园 | 北京市市辖区海淀区甘家口街道三里河路5号 | 单位办 |
| 113 | 中国兵器工业机关服务中心幼儿园 | 北京市市辖区海淀区紫竹院街道车道沟十号院 | 单位办 |
| 114 | 中国人民大学幼儿园 | 北京市市辖区海淀区曙光街道蓝靛厂中路19号 | 单位办 |
| 115 | 中国人民解放军61195部队前哨幼儿园 | 北京市市辖区海淀区青龙桥街道厢红旗一号院 | 单位办 |
| 116 | 北京理工后勤集团幼教中心 | 北京市市辖区海淀区紫竹院街道中关村南大街5号院 | 单位办 |
| 117 | 北京市银河之星幼儿园 | 北京市市辖区海淀区八里庄街道万寿路八宝庄252号 | 单位办 |
| 118 | 北京市海淀区亿城蓝天幼儿园 | 北京市市辖区海淀区马连洼街道亿城西山华府小区(马连洼竹园住宅小区) | 民办 |
| 119 | 国家机关事务管理局花园村幼儿园 | 北京市市辖区海淀区甘家口街道增光路51号 | 单位办 |
| 120 | 海军总医院幼儿园 | 北京市市辖区海淀区甘家口街道阜成路6号 | 单位办 |
| 121 | 北京实验学校(海淀)幼儿园(北京市立新学校幼儿园) | 北京市市辖区海淀区甘家口街道阜成路甲3号 | 教育部门办 |
| 122 | 中央民族大学幼儿园 | 北京市市辖区海淀区紫竹院街道法华寺原址1号 | 单位办 |
| 123 | 北京市海淀区紫竹院街道第二幼儿园 | 北京市市辖区海淀区紫竹院街道魏公村小区 | 单位办 |
| 124 | 中国石油集团科学技术研究院幼儿园 | 北京市市辖区海淀区学院路街道学院路20号 | 单位办 |
| 125 | 北京科技大学幼儿教育中心 | 北京市市辖区海淀区西三旗街道清河宝盛西里26号 | 单位办 |
| 126 | 北京市育龙幼儿园 | 北京市市辖区海淀区学院路街道清华东路东王庄小区七号 | 民办 |
| 127 | 北京市未来之星实验幼儿园 | 北京市市辖区海淀区学院路街道学院路14号新区 | 民办 |
| 128 | 北京市海淀区学院路街道展春园幼儿园 | 北京市市辖区海淀区学院路街道展春园小区20号 | 单位办 |
| 129 | 北京市海淀区海淀街道厂洼幼儿园 | 北京市市辖区海淀区紫竹院街道厂洼小区5号西侧 | 单位办 |
| 130 | 中国人民解放军61046部队幼儿园 | 北京市市辖区海淀区青龙桥街道遗光寺8号院 | 单位办 |
| 131 | 北京大学附属幼儿园 | 北京市市辖区海淀区燕园街道北京大学燕东园26号 | 单位办 |
| 132 | 中国人民解放军北京军区炮兵幼儿园 | 北京市市辖区海淀区香山街道香山南路红旗村4号 | 单位办 |
| 133 | 中国人民解放军总装备部后勤部小营幼儿园 | 北京市市辖区海淀区清河街道清河安宁庄东路28号院5号楼 | 单位办 |
| 134 | 北京市海淀区领秀硅谷凯尔宝宝婴幼园 | 北京市市辖区海淀区清河街道西二旗中路6号院(领秀硅谷社区)A区6号楼 | 民办 |
| 135 | 北京阳光儿童早期教育实验中心 | 北京市市辖区海淀区万寿路街道翠微北里10号 | 民办 |
| 136 | 北京市海淀区凯尔宝宝婴幼园 | 北京市市辖区海淀区西三旗街道西三旗花园二里11号楼 | 民办 |
| 137 | 北京市海淀区温泉镇白家疃中心幼儿园 | 北京市市辖区海淀区温泉镇白家疃小学院内 | 单位办 |
| 138 | 北京市海淀区四季青镇常青幼儿园 | 北京市市辖区海淀区四季青镇东冉村443号 | 单位办 |
| 139 | 北京市海淀区四季青南平庄幼儿园 | 北京市市辖区海淀区四季青镇四季青南平庄122号 | 单位办 |
| 140 | 北京市海淀区世纪汇佳幼儿园 | 北京市市辖区海淀区曙光街道远大路世纪城六区甲2号 | 民办 |
| 141 | 北京市海淀区上庄中心小学附属艺鸣实验幼儿园 | 北京市市辖区海淀区上庄镇上庄家园33号 | 教育部门办 |
| 142 | 北京市海淀区四季青育红幼儿园 | 北京市市辖区海淀区田村路街道田村路162号 | 单位办 |
| 143 | 北京市海淀区二十一世纪实验幼儿园 | 北京市市辖区海淀区曙光街道曙光花园望河园8号 | 民办 |
| 144 | 北京市海淀区小星星双语艺术幼儿园 | 北京市市辖区海淀区马连洼街道梅园小区1号 | 单位办 |
| 145 | 北京市海淀区西北旺屯佃村幼儿园 | 北京市市辖区海淀区西北旺镇屯佃村 | 单位办 |
| 146 | 北京市海淀区翠湖幼儿园 | 北京市市辖区海淀区上庄镇上庄镇临27号 | 单位办 |
| 147 | 北京市海淀区苏家坨镇中心幼儿园 | 北京市市辖区海淀区苏家坨镇北安河村 | 单位办 |
| 148 | 北京市海淀区北部新区实验幼儿园 | 北京市市辖区海淀区温泉镇白家疃西口 | 教育部门办 |
| 149 | 北京市海淀区北部新区实验幼儿园凯盛分园 | 北京市市辖区海淀区温泉镇温泉凯盛家园二区 | 教育部门办 |
| 150 | 中国人民解放军军乐团幼儿园 | 北京市市辖区海淀区紫竹院街道车道沟100号院 | 单位办 |
| 151 | 中国人民解放军空军航空医学研究所附属医院幼儿园 | 北京市市辖区海淀区紫竹院街道昌运宫15号 | 单位办 |
| 152 | 中国人民解放军总医院第一附属医院幼儿园 | 北京市市辖区海淀区八里庄街道阜城路51号院 | 单位办 |
| 153 | 中央军委机关事务管理总局北极寺老干部服务管理局幼儿园 | 北京市市辖区海淀区花园路街道花园东路8号院 | 单位办 |
| 154 | 北京市海淀区富力桃园幼儿园 | 北京市市辖区海淀区西三旗街道西三旗建材城东里富力桃园小区 | 教育部门办 |
| 155 | 北京市海淀区颐慧佳园幼儿园 | 北京市市辖区海淀区八里庄街道颐慧佳园17号楼 | 教育部门办 |
| 156 | 北京市海淀区美和园幼儿园 | 北京市市辖区海淀区清河街道清河小营西路48号 | 教育部门办 |
| 157 | 北京市海淀区苏家坨镇幼儿园 | 北京市市辖区海淀区苏家坨镇A地块经济适用住房A3地块 | 教育部门办 |
| 158 | 中国人民解放军总医院幼儿园 | 北京市市辖区海淀区万寿路街道复兴路28号 | 单位办 |
| 159 | 空军直属机关蓝天幼儿园 | 北京市市辖区海淀区羊坊店街道复兴路14号 | 单位办 |
| 160 | 中国人民解放军66400部队政治部幼儿园 | 北京市市辖区海淀区八里庄街道阜成路50号 | 单位办 |
| 161 | 北京市农林科学院幼儿园 | 北京市市辖区海淀区曙光街道曙光花园中路9号北京市农林科学院 | 单位办 |
| 162 | 北京公交鸿运承幼教中心第三幼儿园 | 北京市市辖区海淀区北太平庄街道小西天电车公司宿舍内 | 单位办 |
| 163 | 北京市海淀区红黄蓝多元智能实验幼儿园 | 北京市市辖区海淀区花园路街道花园北路35号 | 民办 |
| 164 | 中国人民解放军61672部队幼儿园 | 北京市市辖区海淀区马连洼街道圆明园西路5号 | 单位办 |
| 165 | 北京市海淀新区恩济幼儿园 | 北京市市辖区海淀区苏家坨镇C02地块 | 教育部门办 |
| 166 | 北京市海淀区大有双语幼儿园 | 北京市市辖区海淀区青龙桥街道北京市海淀区大有庄北上坡9号 | 民办 |
| 167 | 中央军委机关事务管理总局幼儿园 | 北京市市辖区海淀区北太平庄街道新街口外大街23号院内 | 单位办 |
| 168 | 北京应用物理与计算数学研究所九一幼儿园 | 北京市市辖区海淀区花园路街道花园路 | 单位办 |
| 169 | 北京市海淀区智合国学双语幼儿园 | 北京市市辖区海淀区清河街道清河镇清缘东里3号楼 | 民办 |
| 170 | 北京市海淀区宜宝双语幼儿园 | 北京市市辖区海淀区西三旗街道永泰园新地标小区甲17号 | 民办 |
| 171 | 北京市海淀区唐家岭新城幼儿园 | 北京市市辖区海淀区西北旺镇唐家岭新城T05 | 教育部门办 |
| 172 | 北京市海淀区乐融幼儿园 | 北京市市辖区海淀区四季青镇西四环北路通汇路18号 | 民办 |
| 173 | 北京市海淀区北京大学附属小学实验幼儿园 | 北京市市辖区海淀区马连洼街道西北旺新村德惠路一号院29楼 | 民办 |
| 174 | 北京市海淀区乐全时艺术实验幼儿园 | 北京市市辖区海淀区北太平庄街道文慧园北路9号今典花园小区 西北角 | 民办 |
| 175 | 北京市海淀区上林溪二十一世纪实验幼儿园 | 北京市市辖区海淀区清河街道安宁庄路安宁华庭一区11号楼 | 民办 |
| 176 | 北京市海淀区龙岗路幼儿园 | 北京市市辖区海淀区西三旗街道清河龙岗路甲25号 | 单位办 |
| 177 | 北京市海淀区为明实验幼儿园 | 北京市市辖区海淀区四季青镇巨山路燕西台嘉苑小区甲21号 | 民办 |
| 178 | 北京市海淀区蓝宝特幼儿园 | 北京市市辖区海淀区北下关街道四道口1号8号楼 | 民办 |
| 179 | 北京市海淀区培杰幼儿园 | 北京市市辖区海淀区东升地区东马房新村一期北区B34号 | 民办 |
| 180 | 北京市海淀区苏家坨镇温馨幼儿园 | 北京市市辖区海淀区苏家坨镇聂各庄村正街38号 | 单位办 |
| 181 | 北京市海淀区太阳幼儿园(太月园) | 北京市市辖区海淀区北太平庄街道知春路太月园小区5号楼 | 民办 |
| 182 | 北京市海淀区立新幼儿园分园航天之星幼儿园 | 北京市市辖区海淀区永定路街道北京市海淀区永定路正大南路6号 | 单位办 |
| 183 | 北京市海淀区民族园幼儿园 | 北京市市辖区海淀区花园路街道马甸玉兰园2号楼 | 教育部门办 |
| 184 | 北京市水务局幼儿园 | 北京市市辖区海淀区羊坊店街道玉渊潭公园内 | 单位办 |
| 185 | 北京大学附属幼儿园蔚秀园分园 | 北京市市辖区海淀区燕园街道北京大学蔚秀园 | 单位办 |
| 186 | 北京市海淀区恩济里幼儿园(分园) | 北京市市辖区海淀区八里庄街道北京市海淀区八宝庄甲26号 | 教育部门办 |
| 187 | 北京市海淀区小酷星幼儿园 | 北京市市辖区海淀区四季青镇四季青闵庄南路9号 | 民办 |
| 188 | 北京市海淀区富力桃园幼儿园枫丹分园 | 北京市市辖区海淀区西三旗街道北京市海淀区西三旗建材城枫丹丽舍小区 | 教育部门办 |
数据来源:http://58.118.0.15/login
La disfunción eréctil puede causar un impacto significativo en la calidad de vida de una persona, afectando no solo su salud física, sino también su bienestar emocional y relaciones interpersonales. Sorprendentemente, muchos hombres no buscan ayuda debido a la vergüenza o el estigma asociado. Sin embargo, es importante destacar que hay tratamientos disponibles y que algunas opciones, como los medicamentos, pueden ser perjudiciales si no se utilizan adecuadamente. Por ejemplo, algunas personas consideran alternativas como el uso de ciertos antidepresivos, entre ellos el tofranil, que a menudo puede estar disponible para aquellos que deciden “. Este enfoque puede ofrecer resultados positivos, aunque siempre es recomendable consultar a un médico antes de comenzar cualquier tratamiento. La concienciación y la educación sobre este tema son cruciales para ayudar a quienes lo padecen a buscar las soluciones adecuadas.
La disfunción eréctil es un problema que afecta a millones de hombres en todo el mundo, y su prevalencia aumenta con la edad. De hecho, se estima que alrededor del 50% de los hombres mayores de 40 años experimentan algún grado de este problema. Es interesante señalar que factores como el estrés, la ansiedad y problemas de salud subyacentes, como enfermedades cardiovasculares, pueden contribuir significativamente a esta condición. Muchos hombres buscan soluciones, y algunos consideran la opción de medicamentos para ayudar en esta situación. Por ejemplo, hay quienes investigan sobre cómo ” para abordar problemas relacionados con la salud prostática, que a menudo están interconectados con la disfunción eréctil. Sin embargo, siempre es recomendable consultar a un médico antes de iniciar cualquier tratamiento.
Un dato interesante es que muchos hombres pueden experimentar problemas de erección en algún momento de su vida, lo cual puede ser influenciado por factores físicos y emocionales. En algunos casos, se ha observado que medicamentos como el tofranil pueden tener un impacto en la función sexual, por lo que es importante consultar a un médico antes de decidir “. La salud del corazón, el estrés y otros problemas emocionales también pueden contribuir a este tipo de condición.
数据抓取代码:https://github.com/dotte/data_spider/tree/master/hdschool
一年百万级别直接个人账户转账是否会引起洗钱调查?
Where to buy 🚀 aged domains and backlinks 🔥 from Best-SEO-Domains | 0083-0608
作者:匿名用户
链接:https://www.zhihu.com/question/23299896/answer/24159558
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这笔交易一定会上报到人行反洗钱中心,但是否有后续调查不能确定(简单理解为看RP好了 -_-# )。
其实题主就是想搞明白什么样的交易会被监控到,是这样滴,央行有个部门叫反洗钱监测分析中心,金融机构每天会上报两类的关联交易:大额交易和可疑交易。
大额交易主要指:
- 对个人每日≥¥20万的各种交易,≥$1万的跨境交易;对企业每日≥¥200万或≥$20万的款项划转;个人和企业之间每日≥¥50万或≥$10万的各种款项划转
可疑交易很复杂,是银行根据自己长期的业务经验所汇总出的若干条判定规则,典型的有:
- 短期内资金分散转入集中转出或者集中转入分散转出、提前偿还贷款、收款后迅速转到境外、相同收付款频繁收付且交易金额接近大额交易标准、用于境外投资的购汇为现金、进行本外币间的掉期业务、经常存入境外开立的旅行支票或者外币汇票存款,资金的来源和用途可疑、与客户身份、财务状况、经营业务明显不符,与其经营业务明显无关的汇款、证券交易、保险赔付或者退保等;长期闲置的账户原因不明地突然启用或者平常资金流量小的账户突然有异常资金流入,短期内出现大量资金收付,频繁进行现金收付或者一次性大额存取现金且情形可疑;频繁收到、订购、兑现外汇、开具旅行支票、汇票等等等等
所以按题主所说的情况,无论你用什么方式,只要通过银行等金融机构,反洗钱系统是一定能检测到这笔交易,并会将其上报。但是上报给人行并不是说就会发起题主所担心的“反洗钱调查”。每天银行上报的数据成千上万,其中大部分交易都是正常的,真正涉嫌洗钱的只是极少数。人行会汇总全国的无数数据进行再次的分析,最终得出需高度关注的资金链,再做后续处理。
总而言之,现在的银行(及人行)反洗钱系统处理能力是很强大的,计算模型越来越完善,抓点蛛丝马迹那是小菜一碟。至于抓到马脚后怎么处理,呃,这是另一个很复杂的话题……
高房价背后的高级犯罪
关于房价的话题一直非常火爆,朋友圈里很多朋友每天都在转发各种分析类的文章。似乎,聊房价的人就是时尚时尚最时尚的人。
呵呵,房产也好,股票也罢,搞这些事情的人里面,有一部分,是绝对意义上的犯罪分子。
虽然这些犯罪分子并不是造就今天高房价的根本原因,但是这些犯罪分子绝对是高房价的助推剂。
今天,本文就要透过大量的泡沫,带大家看一看,与房产相关的各种犯罪活动。
洗钱
今年5月曾经有一条很轰动的新闻,不知道大家有没有看到过:

啧啧啧,什么留学生能掏得起1.1亿元做首付买房?
是的,要聊与房产相关的犯罪,首先要聊洗钱。
不管是电信诈骗、贩毒、走私、赌博、非法集资、地下钱庄、受贿还是贪污,只要是犯罪得来的钱,一定是黑钱。既然是黑钱,就一定要洗白。
怎么洗钱呢?
比如说你是美剧《绝命毒师》中的男主角老白,一个因为患了癌症想要去贩毒的高中化学老师。

一开始呢,势头不错,老白一个月靠贩毒就能赚5万美元。
但是这么多钱,很明显不是老白这样一个高中老师能赚到的。
于是他和老婆一起开了个鸡肉店。

如果你到这家鸡肉店里去看看,你会发现,除了两个伙计和零星的几个客人,这里非常冷清。
但是如果你看这家鸡肉店的账面,你会发现,一天至少有500人来这里吃鸡肉。
于是,靠贩毒赚来的钱就变成了卖鸡肉赚来的合法收入了。
再后来,老白一个月靠贩毒能赚10万美元了。怎么办呢,于是他又开了一家洗车店。
如果你仔细去看这个洗车店的账面,你发现,这家美国小镇的普通洗车店,一天居然能洗500辆车,而且这500辆车的车主还都花钱买了成箱的矿泉水、买了大量的玻璃水,买了大量的汽车零配件。
再后来,不得了了,老白一个月能赚500万美元了。
好吧,这样就麻烦了,这么多钱,根本来不及洗嘛。做什么正经生意能一个月赚500万美元啊,怎么洗啊?
最后老白只能选择找个偏僻无人的仓库,把钱藏起来。
而在现实的生活当中,上世纪70年代哥伦比亚著名的大毒枭巴勃罗.埃斯科瓦尔,一年靠贩毒能赚200亿美金,这么多钱在哥伦比亚这样的国家根本不可能被洗干净。
于是他是这样做的:

是的,挖个坑埋了。
据说巴勃罗一年光用来捆钱的皮筋就需要花费3万元,一年被老鼠啃坏的钞票就有10亿。
啧啧啧,可惜了,巴勃罗要是生活在今天中国的北上广深,他一定知道怎么洗钱。
随便拎出一套房子,500万,地段估计还是贫民窟。
价值一亿的豪宅遍地都是。
虽然限购,但是一个身份证在北京能买一套,在深圳还能买一套,在上海又能买一套。。。。
至于所谓的实名制呢,根本就是名存实亡。对于犯罪分子来说,搞什么多个户口,搞什么人户分离,简直就是玩儿一样。
最最最重要的一点就是,买房是可以用现金的!用现金!
卖房了以后钱是可以直接进银行的,银行!
而且更重要的一点来了:原本洗钱这个事情,一般来说都是要花费不少成本的。
比如你开一家洗车店,房租、洗衣店装修、设备、人工、财务、税收。。。。好不容易挣来一百万,洗完了变成80万。
但是通过房地产洗钱,不但不亏,还能升值。
有这么多有利条件,利用房产来洗钱,就成为了一种非常有利的选择。
于是问题来了,怎么靠房子来洗钱呢?
比如你有500万现金,你可以拿着这些钱去任意一家房地产公司的销售部门,然后你告诉漂亮的销售小姐:我要全款买房。
你猜销售小姐第一句说什么?
你猜销售小姐会不会问你:先生,您怎么来的500万现金啊,是不是合法收入啊?
哪个销售小姐脑子坏掉了。
是的,就是这么简单。成立一家皮包公司,但是注册的这个公司的法人呢肯定不是你。
然后用犯罪得来的钱,以公司名义买一套房。
买房的时候你有两个选择:洗钱手法差的,用500万全款买一套房。
洗钱手法高明的,可以用500万做首付,买一套价值2000万的房,然后继续用黑钱来还贷。
总之,没有任何一家中介公司或者房产公司有闲心去管这些钱是不是黑钱。
买到房子以后,过了半年,卖掉。
于是你神奇的发现,黑钱变成合法收入了。
什么?这位大哥太有钱了,嫌房子一套一套买太烦了是吗?
别着急,咱们直接成立房地产公司,咱们大规模的洗钱。
是的,今天的中国,有一部分人就是依靠这种手段来洗钱。房价疯涨的背后,有这些人的很大功劳。具体的功劳到底是推波助澜还是锦上添花,那就不晓得了。
行贿
关注财经的朋友肯定都知道有个著名的教授,叫做郎咸平。
多年前,这位郎先生就喊出过一句著名的话,叫做:民营企业是有原罪的。
与之相对应的,是我们的国民公公。
我们的国民公公恰好经营了一家民营企业,并且还是搞房地产起家的,这家公司呢,叫做万达。
国民公公说过一句非常著名的话,请注意,这句话不是“小目标一个亿”。
是那句:“万达从来不行贿。”
因为王先生的这句话,一个段子广为流传。这个段子是这样写的:
- 当王健林面对媒体的采访,非常淡定的说出“万达从来不行贿”的时候,恒大的爱马仕哥哥许家印正在喝恒大冰泉,听到这句话以后,一口喷在了马云的脸上;万科的登山家王石先生刚刚爬到半山腰,听到这句话后喊了句“我X”,差点引发珠穆拉玛峰的雪崩。
王健林喊出这句话的时间,据考证是在2012年,多年来,这句话成为万达引以为豪的企业文化。
4年后,王董事长终于被啪啪打脸,大家请查一下9月28日的新闻,先给大家做个截图:

王董事长被啪啪打脸,不过这还不是最要命的。
要命的是这个金程只是一个大连市的市委常委,只是一个小角色,受贿的日期还是08年和09年。
背后的大角色是谁呢?我们的王董事长和他的宝贝儿子未来命运会如何?
啧啧啧,真是让人期待。我们的王董事长前不久刚刚为中国的高房价泡沫奔走疾呼,结果就出来了这样一条新闻。
貌似最近风向又变了?
呵呵,刚才举的这个例子呢,只是热身,接下来我们聊一下怎么通过房子来行贿。
说到行贿呢,非常简单,就是企业送钱给贪官。
这个钱怎么送呢?怎么送才能不被中纪委查到,又或者即使查到了也可以抵赖掉呢?很简单,请看如下案例:
某官员家中有一套价值500万的房产,然后一个房地产开发商想要对这名官员进行行贿。
于是开发商派出了手底下一个小马仔,让这个小马仔去买官员的这套房产。
先签订买房合同,缴纳了200万订金。
购房合同里明文写明:已缴纳200万订金,如果购买方违约放弃购买,赔偿双倍违约金。
然后呢?
自然就违约了,这位马仔掏了400万违约金赔给这位官员,这位官员房子还在,白拿400万,并且完全是合法收入。
请注意,订房后,合同里写明赔偿双倍违约金是一种非常普遍的行为,丝毫不值得怀疑。
于是,这位官员顺理成章的获得了400万行贿款,请问,这样的情况检察院怎么来定罪?
唉,可惜了我万达的王健林董事长,你的手下在08年的时候,行贿的手法居然这么愚蠢,竟然能够被查出来。
可惜,可惜。
骗贷
在中国,中小企业向银行申请贷款,其难度之高,不亚于向犹太人白要钱。
就算好不容易借来了银行贷款,也要支付大概百分之10甚至15的利息。
如果从银行没法借到钱,就要使用民间借贷。
一般利息是百分之20以上。
但是你会神奇的发现,一个普通的老百姓,只要有正当工作,并且缴纳住房公积金,银行就可以闭着眼睛把几百万的钱贷给老百姓买房。
并且首套房的基准率只有大概百分之4.5。
啧啧啧,请问,这个时候,如果你是一个中小企业的经营者,面临资金链断裂的风险,并且你手里恰好还有一套价值1000万的房产,你会怎么做?
把价值1000万的房子卖了?
把价值1000万的房子抵押给银行然后贷款?
好吧,我来告诉你:
第一步,找一个绝对牢靠的亲戚,比如自己的亲妹妹,亲妈等等,总之,只要不在一个户口本上就行。
第二步:找一个中介,把自己的房子标价1200万。
第三部:给这个亲戚400万,让他用这400万做首付,再从银行贷出800万。
第三步:房子过户到亲戚名下,自己一分钱没花,400万还是自己的,800万贷款又到手了,房子也依然是自己的。
并且请注意,原价值1000万的房产,标价的是1200万。
这多出来的200万,原本是为了多从银行骗点贷款。
但是一套房子涨价了百分之二十这种消息传出去以后,效果是啥?
如果说上面说的只是一套房子的骗贷手段,那么200套房子呢?
比如某公司开发的一个新楼盘竣工了,竣工以后,大概有200套房子亟待销售。
但是此时,恰遇房地产业低迷阶段,售卖速度十分缓慢。
而就是在这个时候,这个公司的资金链也快要断了,如果不能迅速卖掉这200套房子收回资金,这个公司就要和大家说再见了。
于是这个公司的老板决定赌一把。
老板找到了200个年轻人,弄到了他们的身份证,然后填写了200份购房申请材料。
然后神奇的从银行手中,弄来了200套房子的贷款。
是的,房子就这样卖出去了,贷款骗到手了,资金链断裂的危急解除了,银行也提前完成了今年的贷款考核指标。
真是皆大欢喜,当然,房价又涨了。
很多房地产企业,依靠这种骗贷方式,渡过了房地产的冬天。
只要迎来春天,房价上涨,企业的危机也就渡过去了。
但是少数企业没有挺到房价疯涨的那天,资金链断了。
于是企业法人坐监狱了,房子被银行收走了。
刚才水母举的这个例子,简直就是房地产业内的超级潜规则。
比如2006年和2007年,是中国房地产业的超级冬天。
那几年,N多家房地产公司,没有等来2009年春天的4万亿,于是纷纷死掉了,比如下图这家公司,在2000年骗贷,在2006年资金链彻底断裂,在2009年法人被判无期徒刑。

啧啧啧,就差那么一点点,就那么一点点,这家房企就能迎来2009年的4万亿。
可惜啊,没有挺过去,这家公司的老板只能坐在了监狱里,看着挺过去的同行们翻着倍的赚钱。
非常明确的告诉大家,国内所有的房地产公司,都欠银行巨额的贷款。
玩儿房地产的人,就是在玩儿金融,而且是极高杠杆的金融。
而对于这种现象,银行都是睁一只眼,闭一只眼。
对于银行来说,只要你资金链不断,能够按时还我的利息,你就是合法贷款。
哪天你资金链断了,自然就是骗贷,自然就要坐牢,房子么我也收回。
房企赌的,是自己能够顺利过渡到下一个房产周期。
银行赌的,是一百家房企里头,只有一家房企会资金链断裂,只要整个房地产市场不崩盘,银行收回的房子就能以高价重新卖出去,银行的资金链自然也不会断裂。
除非有一天,所有的房地产企业的资金链同时断裂,银行收回一堆再也无法回本的砖头。
然后银行的资金链也断了,金融危机,不,是金融地震就此发生。
泡沫
说了那么多涉及房产的高级犯罪形式,大家最想知道的并不是这些,而是房价到底还会不会涨。
好吧,对于这个问题,斗胆来讨论一番:
很多人讨论房价,首先讨论一个问题:房子是刚需,所以房子永远要涨价。
“刚需”这个词汇,很有意思。
什么是刚需?女式挎包算不算刚需?
对于所有的女人来说,一个好看的包包永远是刚需。
大学没毕业的女孩,可以去西直门动批买假LV,电视台的知名主持人,可以去新光天地买真LV,甚至爱马仕。
房子也是这个道理。
谁都需要房子,但是房子分好房子坏房子。
在北京,房子分为二环内的房子以及6环外的房子。
在全国,房子分为北京的房子和甘肃的房子。
当然,还分为租来的房子和买来的房子。
对于一个普通家庭的大学女生来说,她手上即使有1万块钱,也可能选择用来交学费,甚至被电信诈骗骗走,但是她绝对不会去买真LV。
对于一个刚到北京打工的农民工兄弟来说,他可能这辈子都不会在北京买房。
所以,你看到了,所谓的在北京买房的那群人,理论上永远是那些买得起的人,买不起的人,再怎么刚需,也不会买。
所以在这种情况下,房子的价格,会在一个平衡的状态下逐渐缓慢合理增长。
那么今天北京市区内平均6万一平的房价合理吗?
价格是合理的,但是到达这个价格所花费的时间不合理。
如果北京的房价,每年以平均百分之10的速度增长,到了2020年的时候,涨到了6万一平,这叫做合理增长。
但是,今天的北京房价,是在短短10个月的时间里,直接翻倍,涨到了6万一平。
任何东西的价格,用这种速度来增长,一定运用了大量的杠杆,因此,也一定存在泡沫。
2015年,中国A股,仅仅用了半年多的时间,就从2100点疯涨到了5000点,涨了一倍多。
唉,后头的事情大家也都知道了。
多年来,我国的历任证监会主席,都希望把A股引导到一条所谓“慢牛”的道路上来。
因为慢牛是健康的,疯牛的结局注定是惨不忍睹。
再告诉大家一个数据:
在2009年中国楼市疯涨的那个年代,我国的资金,呈现净流入的数据,海外的热钱源源不断的涌入中国。
那个时候,中国政府出台了各种政策,围堵各种海外热钱,防止出现恶性通货膨胀。
在今天,2016年,中国楼市再次疯涨。但是目前,我国的资金,正在净流出。
中国的金融监管部门,最近最为忙碌的事情,就是围追堵截这些资金,不让他们流出中国。
于是你要问了,同样是楼市疯涨,为什么09年净流入,16年净流出呢?
是因为中国加入了SDR?是因为美国预计在年底加息?
好吧,我也不知道。但个人觉得,这个数据很不正常,很不吉利。
人人皆谈房地产,但估计很少有人清楚一个问题,那就是中国大地上到底有多少房子?
相关阅读:2012年北京市公安局曾经有一个数据,大体是北京有380多万住户联系不到,当时被市场解读为北京空置380多万套房子,尽管有关部门对此进行否认,但究竟真正有多少房子,仍然成谜。
“北京空置房高达381.2万户,什么概念?假设一户平均住2人,就能装下700多万人口,如是三口之家,就能容下1000万人。”
这是全国首次官方公布的摸底调查,空置率过高,说明我国的住宅市场确实不健康。
这估计要等不动产登记结束,才能有个大概的数据。之所以说是大概,误差是其次,登记是为了征税,想来不少房产会钻漏洞,当然还有各种违章建筑,以及永不停止的“拆出一个新中国”。
那么,为什么说现在是“该搞清楚中国究竟有多少房子了”?中国楼市空置率统计到底有多“难”?关于中国楼市空置率,相对“靠谱”的数据是怎样的?
中国城市楼市空置率(相对靠谱数据):
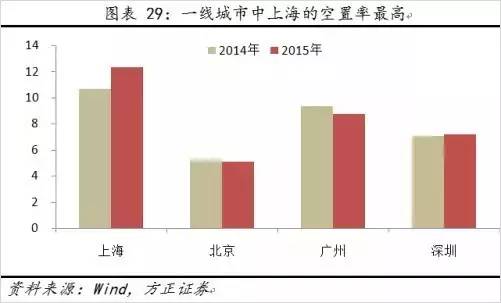
具体到城市而言,一线城市中上海的空置率最高,在10%以上,2015年更是比2014年上涨了1.7个百分点。而北京的空置率较低,仅有5%,且2015年稍有下降。
二线城市中,东北地区城市空置率明显要高于其他地区。沈阳的空置率超过18%,远远超过其他二线城市,青岛的空置率也处于较高位置。东北地区空置率较高反映了东北经济近年来整体滑坡和人口外流的情况。

马光远:该搞清楚中国究竟有多少房子了
10月前半月,热点城市在限购限贷政策的影响下,不仅成交量明显下降,房价涨幅也得到了遏制。但中国房地产发展到今天,规模已经足够庞大,靠零打碎敲的政策,是无法从根本上解决当下房价“暴涨”的难题的。
对此,独立经济学家马光远认为现在更迫切的任务是——搞清楚中国究竟有多少房子。他表示:
为什么在去库存的周期下,房价却迎来了大涨甚至疯涨的预期?为什么大量的新增贷款进入到房地产领域,除了今年货币政策超预期宽松,以及全球的资产荒之外,笔者认为,最根本的原因是大家一直认为中国仍然缺房子,特别是大城市的房子。从数据的透明度而言,中国的房地产市场就是一个真正的“柠檬市场”,无论是房子的基础数据,房价的统计指标,土地供应,城市规划,住房需求等等,都基本是一笔糊涂账。
就拿房子的基础数据来说,从1998年房地产市场化以来,中国究竟有多少房子,每个城市住房的存量究竟有多少,迄今没有任何部门做过统计。笔者在研究中国房地产问题时,最头痛的就是根本没有多少可靠的数据能够应用。比如北京,北京现在究竟有多少房子,每年需要多少房子,未来10年北京新增人口究竟需要多少住房,住建部门没有任何权威的数据。
记得有一年北京市公安局曾经有一个数据,大体是北京有380多万住户联系不到,当时被市场解读为北京空置380多万套房子,尽管有关部门对此进行否认,但究竟真正有多少房子,仍然成谜。
基于此,笔者多年来一直呼吁中国进行一次真正的住房普查,搞清楚中国究竟有多少房子,搞清楚每个城市究竟有多少房子。这个问题只要清楚透明了,房价怎么走,其实老百姓都会自己判断。
这个问题如果一直是一笔糊涂账,成为一个秘密,房子的稀缺就会成为炒作的工作,房价的暴涨就会成为常态,房地产的健康发展就会成为一句空话。房子多少搞清楚了,也才能为未来的房产税提供基础数据,才能为房地产政策提供最基本的决策依据。
稳定房价说难很难,说简单也很简单,只要做到房子供需数据的完全透明,只要做到土地供应不搞饥饿营销,只要把住房保障和住房市场厘清边界,房价自会回归理性。在房子基础数据残缺不全的情况下,就会出现人为制造短缺的各种恐慌,从而导致房价非理性上涨。
中国楼市空置率统计之“难”
事实上,不仅是“中国有多少房子”的问题,作为经常被用来评价楼市“健康程度”的一个重要指标,住房空置率一直备受关注。近些年来,中国楼市空置率高企的话题屡被提及其中数据的出处不一。从“数灯法”到大数据估算,引用者各有理由,但很难获得社会普遍认可,关键问题是数据缺乏权威性。
那么,统计究竟难在何处?
“国际上的住房空置率是以所有的房屋数量为分母,以出租租不掉、想卖卖不出的房屋数量为分子,得出的数据。”中国房地产协会秘书长顾云昌表示,但具体到中国,要推算出准确的中国住房空置率有几个难点。
他解释,首先,统计口径不清楚。从1986年房屋普查到2014年,将近30年的时间里,住宅数量有了巨大的改变,包括扩大、拆迁等,房屋总量这一基数很难统计清楚,“和国外相比,中国的基础资料不全,人口变化和城镇发展又太快,统计数据很难跟上现实的步伐”。
其次,数据来源不清楚。“各种住房空置率统计的办法都难以尽善尽美。即使是挨家挨户的调查也不一定能拿到完全准确的数据。一方面,调查难以覆盖全国所有的城镇情况;另一方面,住户给出的信息也有‘水分’掺杂其中。”顾云昌说,再者,有的机构将待售商品房面积等同于住房空置面积,“但实际上,两者并不等同”。
2015年5月,《新华每日电讯》的一篇文章援引国家统计局相关人士的观点称:
“从短期和表面上看,主要是空置的状态和时间很难给出标准,要清楚计算出来难度较大。从深层来看,主要是我们还没有征信制度支撑,调查缺乏客观科学的依据。未来寄望于不动产登记制度的实施。”
中国楼市空置率究竟有多高?
空置率是指某一时刻空置房屋面积占房屋总面积的比率。按照国际通行惯例,商品房空置率在5%至10%之间为合理区,商品房供求平衡,有利于国民经济的健康发展;空置率在10%至20%之间为空置危险区,要采取一定措施,加大商品房销售的力度,以保证房地产市场的正常发展和国民经济的正常运行;空置率在20%以上为商品房严重积压区。
中国地产市场中空置率具体是什么水平,目前没有太权威的数据。但有一些零散的研究统计结果,还是值得参考的,比如:
第一,中国家庭金融调查与研究中心在2014年6月10日发布的“城镇住房空置率及住房市场发展趋势”调研报告表明,2013年全国城镇家庭住房空置率高达22.4%,其中六大城市重庆、上海、成都、武汉、天津、北京的空置率分别为25.6%、18.5%、24.7%、23.5%、22.5%、19.5%。从区域差异看,三线城市住房空置率最高,为23.2%;一、二线城市分别为21.2%与21.8%。此外,中国的住房空置率已高于美国、日本、欧盟等国家和地区。
空置住房占用的银行贷款属于资本闲置,降低了金融市场的效率。截至2013年8月,空置住房占据了4.2万亿的住房贷款余额。空置住房的资产价值在有空置住房家庭总资产中的比重为34.4%,在城镇所有家庭总资产中的比重为11.8%,是社会资源的巨大浪费。
第二,国际货币基金组织(IMF)副总裁朱民曾2015年春会期间表示,中国楼市的首要问题是空置率太高,空置面积高达10亿平方米。
第三,腾讯与中国房地产报等机构联合发布的《2015年5月全国城市住房市场调查报告》显示,中国主要城市的住房空置率整体水平在22%至26%之间。中国房地产报针对“一二级地产开发公司、代理行、营销机构、二手房中介、房产电商等”房地产行业内人士的定向调查则显示,目前一线城市空置率22%,二线城市24%。

高空置率:一线城市上海最高,二线城市沈阳、青岛
从空置率数据中,可以得到两点结论:一是中国的空置率比较高,整体接近或达到了严重积压的警戒线;二是二三线城市的空置率问题要更严重,一线城市相对好些。
从住宅看,中小城市空置率更高可能是因为过度建设。大城市的空置率可能跟过度投机有关。
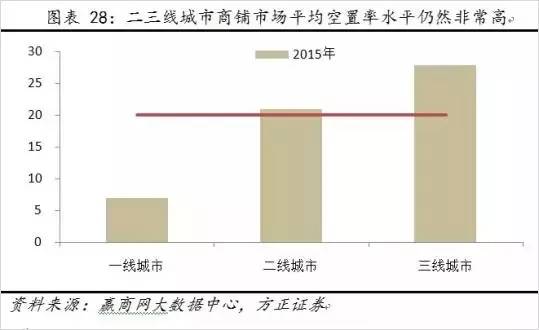
从商铺看,一线空置率较低,三四线较高。大城市的商业要比中小城市发达很多,一线城市商铺的空置率非常低,普遍在10%以下。从赢商网大数据中心得到的数据显示,2015年中国二三线城市商铺市场平均空置率水平仍然非常高,但一线城市的商铺空置率很低。
具体到城市而言,一线城市中上海的空置率最高,在10%以上,2015年更是比2014年上涨了1.7个百分点。而北京的空置率较低,仅有5%,且2015年稍有下降。
二线城市中,东北地区城市空置率明显要高于其他地区。沈阳的空置率超过18%,远远超过其他二线城市,青岛的空置率也处于较高位置。东北地区空置率较高反映了东北经济近年来整体滑坡和人口外流的情况。
