前段时间写过一篇文章是推荐信用卡的《推荐几个海外虚拟信用卡服务商,可注册ChatGPT Plus、notionAI等》,发现有很多网友有注册NodePay的需求,那就写一篇教程来指引一下新手吧。
应用场景
- 海淘采购包括亚马逊、沃尔玛、阿里巴巴等;
- 店铺月租以及验证包括Etsy、煤炉等;
- 付费开发者包括Google、Apples等,付费服务包括Paypal、Remitly等;
- 广告付费电商网站包括Amazon、eBay、Shopify、SHOPLAZZA、AliExpress、Shopee、Wish、Etsy、Lazada等;
- 广告平台包括Facebook Ads、Google Ads、Twitter Ads、AdSpy、Pinterest、Instagram等;
- 应用开发包括Apple、Alibaba Cloud、Google Cloud等;
- 付费订阅包括App Store、Netflix等;
- 物流服务包括Newegg、Logistics等;
- 海淘购物包括FootLocker、Yeezy Supply、Supreme、NIKE、Stockx等。
过程
官方地址:nobepay.com/
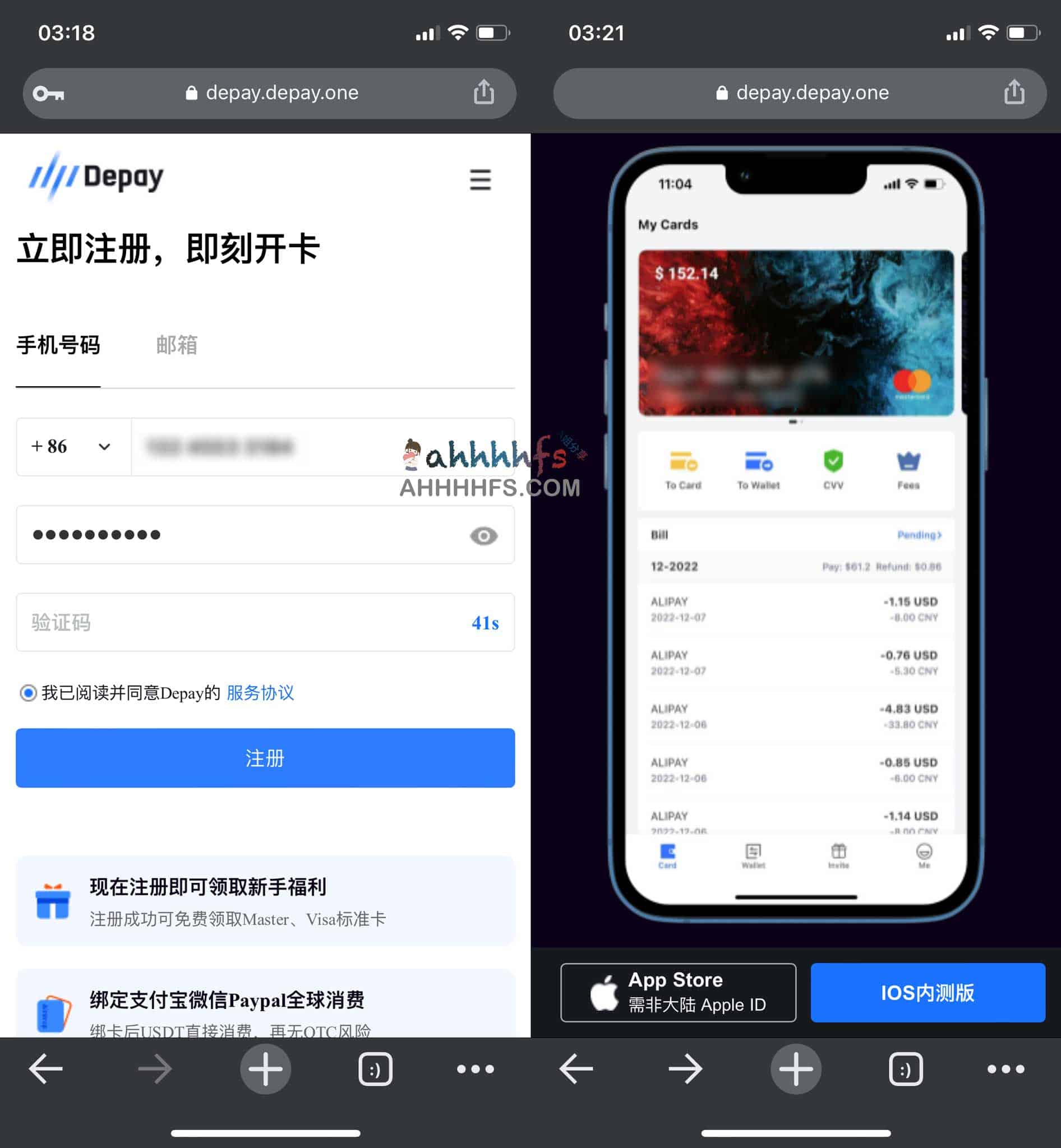
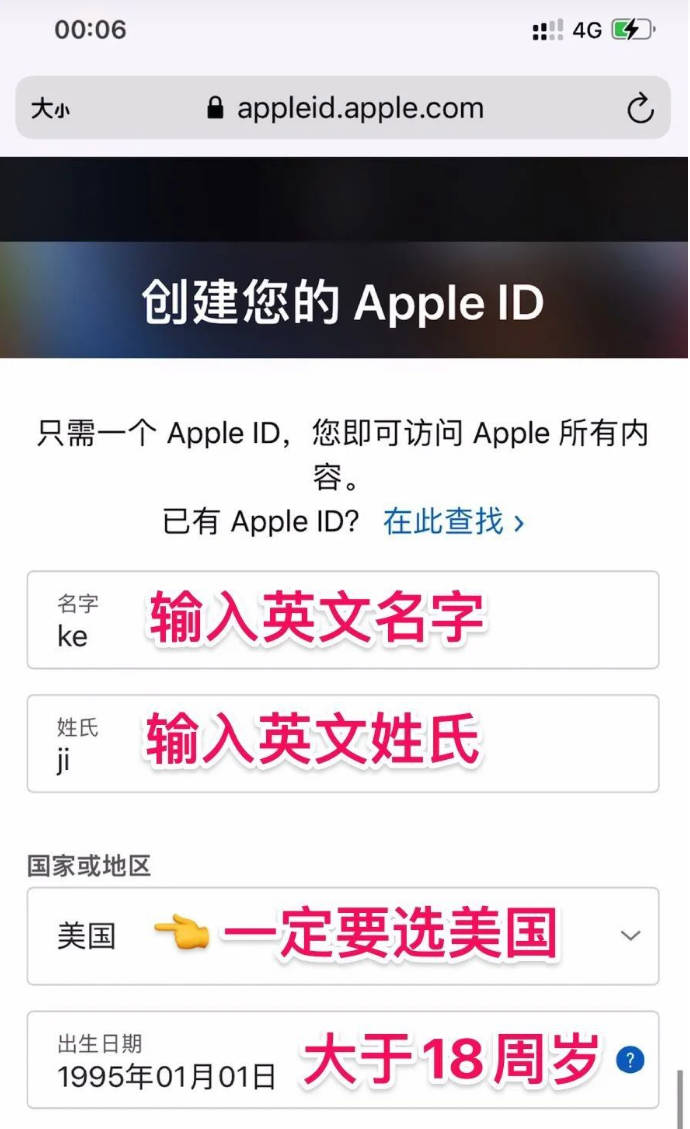
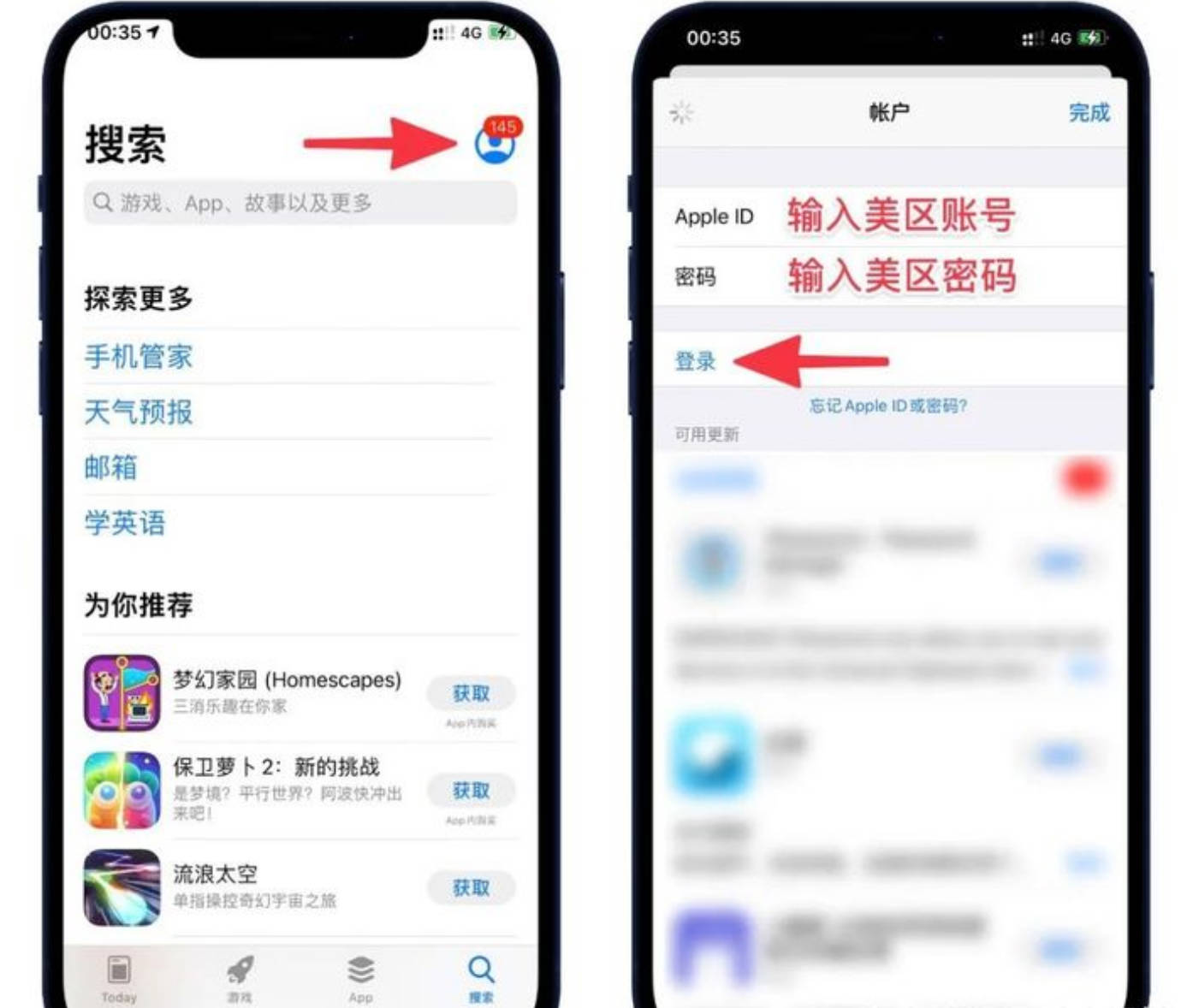
第一步,打开官方地址,切换成中文
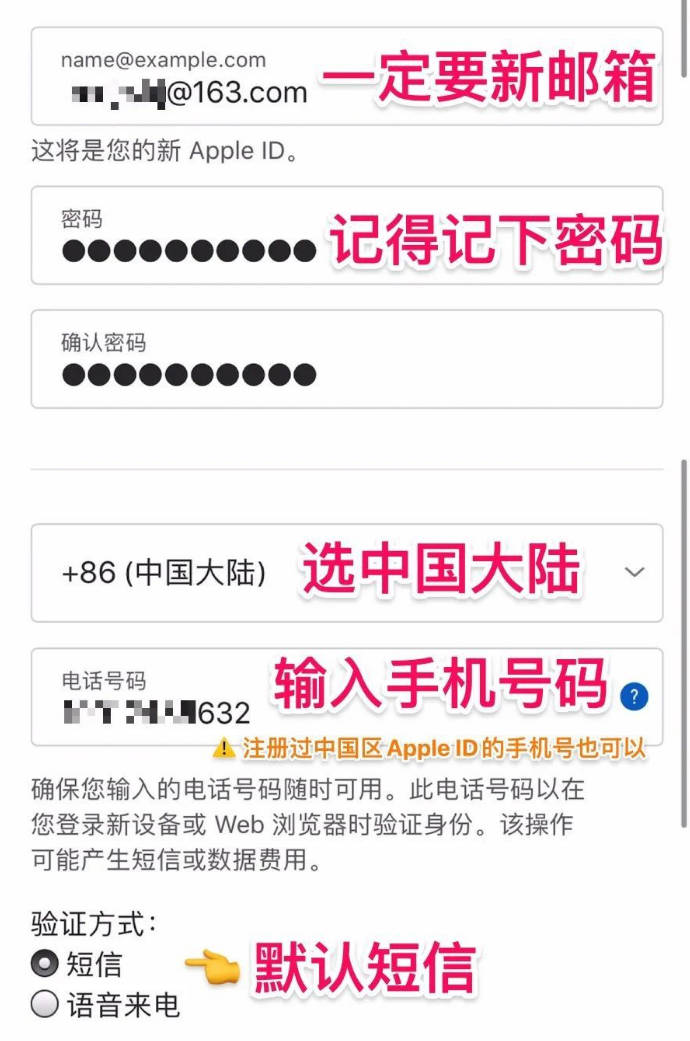
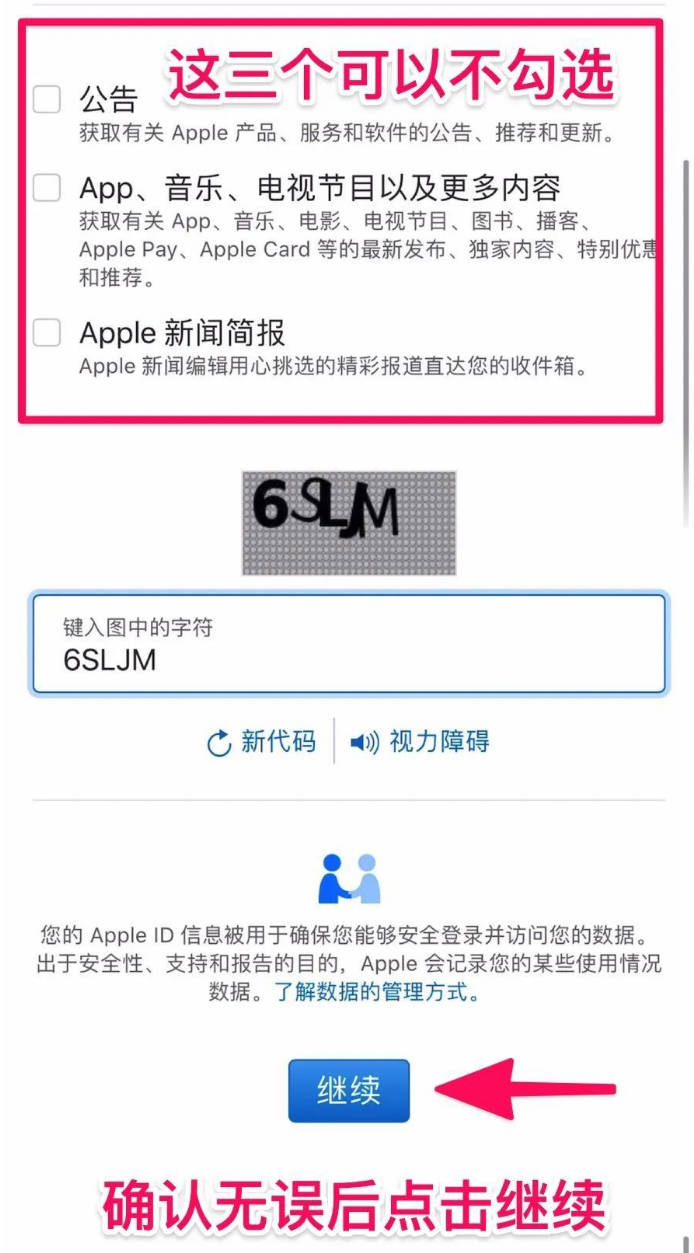
第二步,注册
注册填写已实名的微信号,验证手机就可以,第一次使用,用币圈小伙子的激请码,如果现在注册可以填我的邀请码:XXX,谢谢!
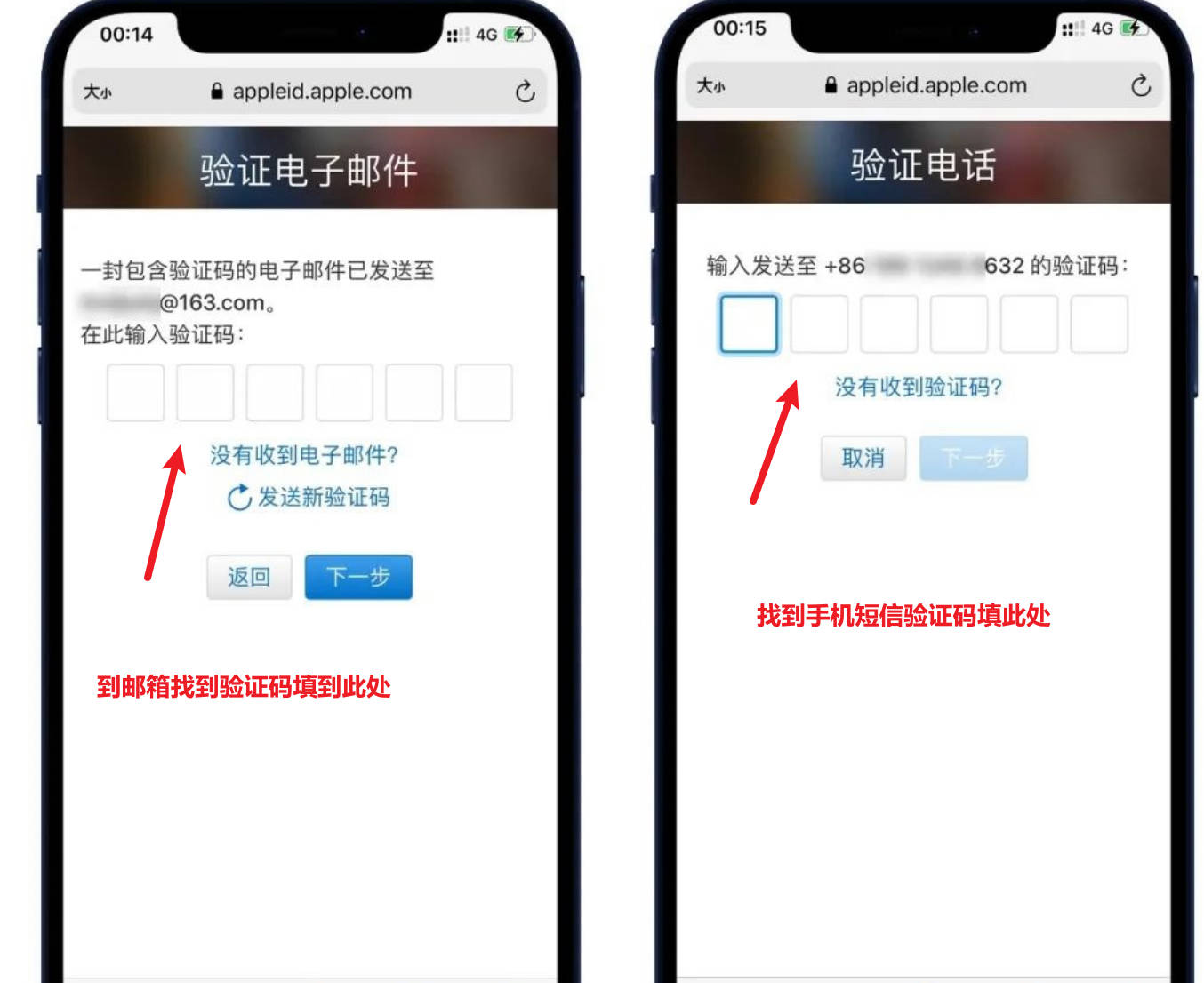
第三步,登录
如果第一次登录提示这个,换到手机快捷登录,验证完手机就能登录了
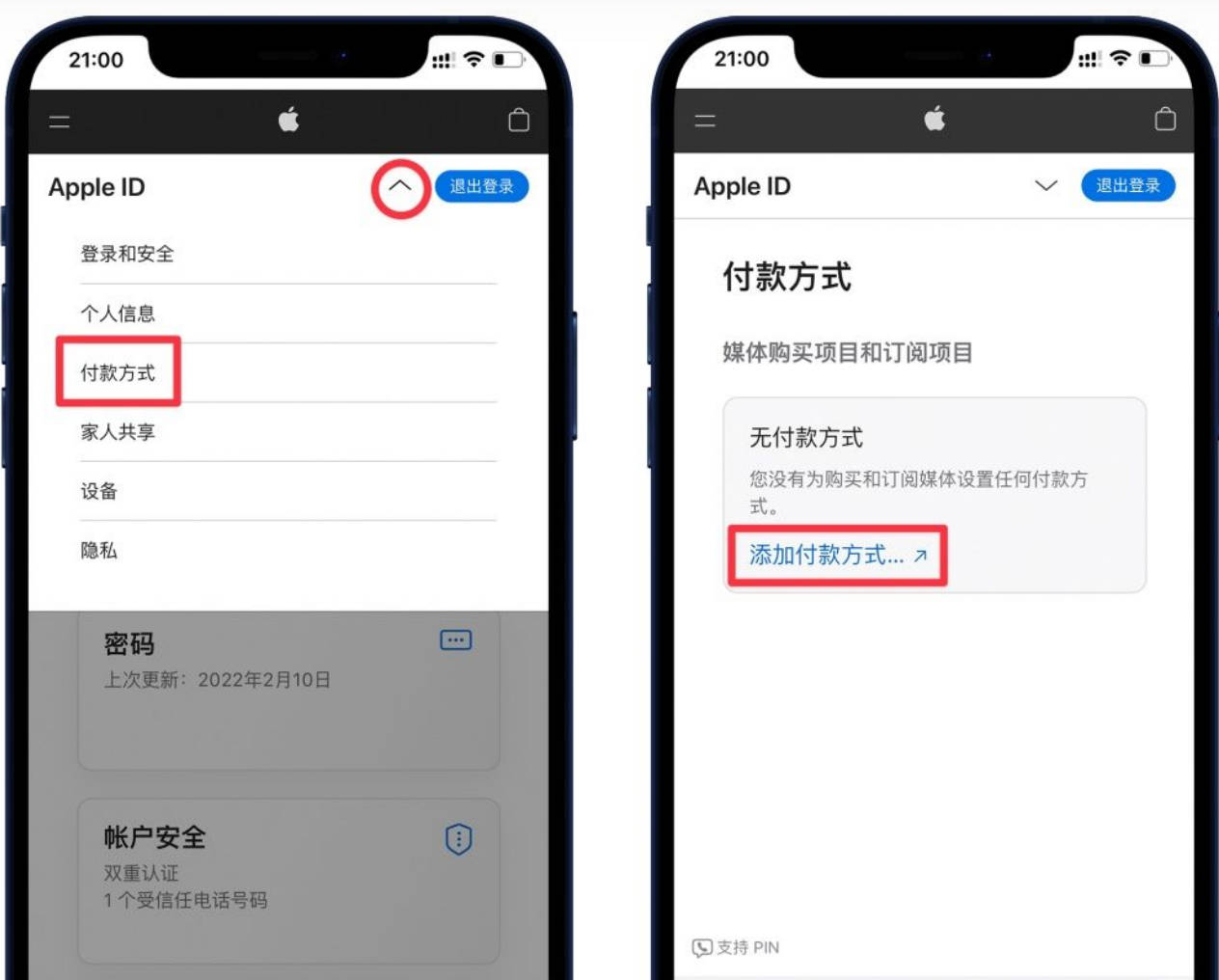
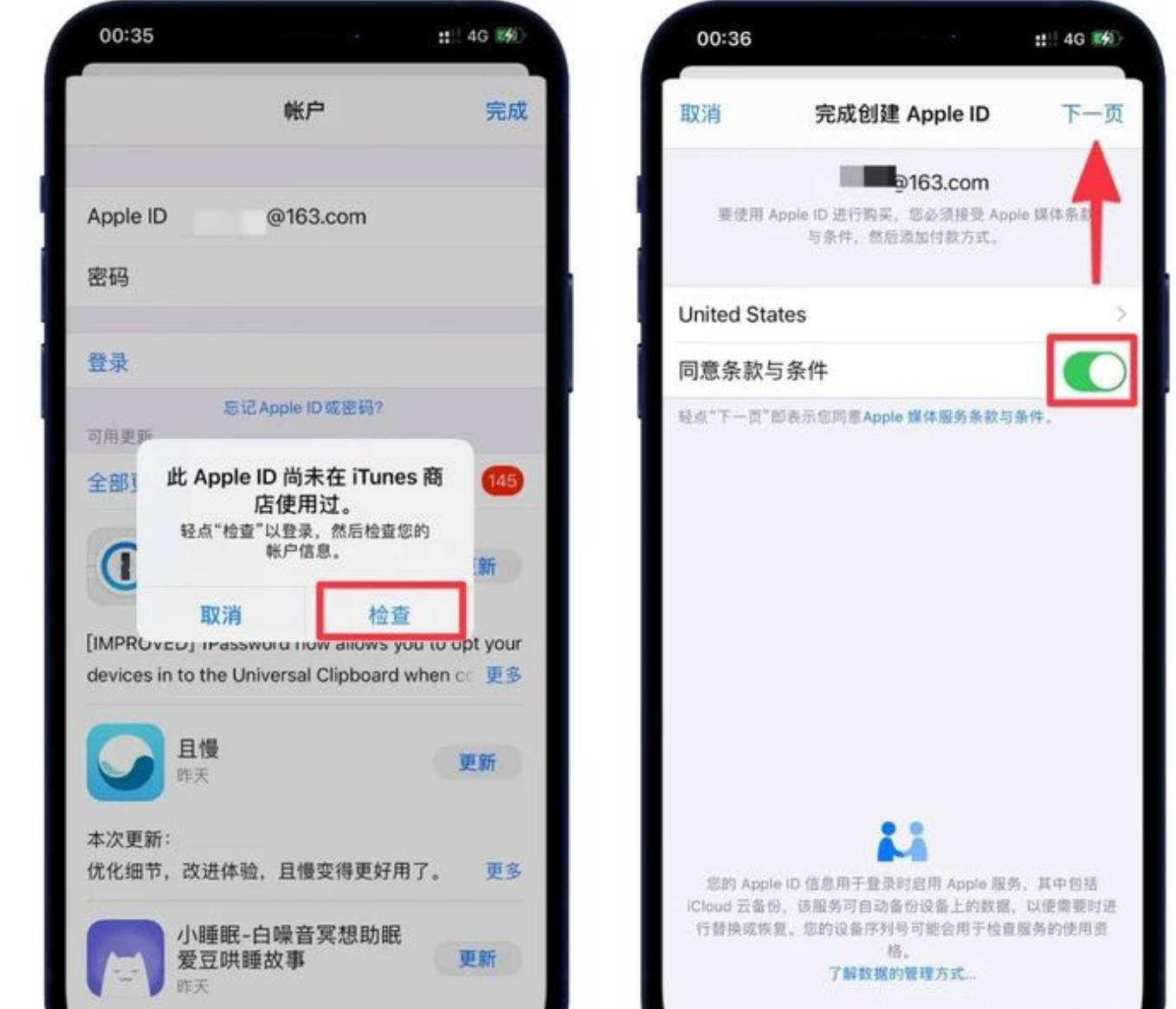
第四步,认证
关注公众号,填写问卷,KYC认证
填写这里就要用到一开始登记的微信了
微信扫码完成KYC认证就可以了。
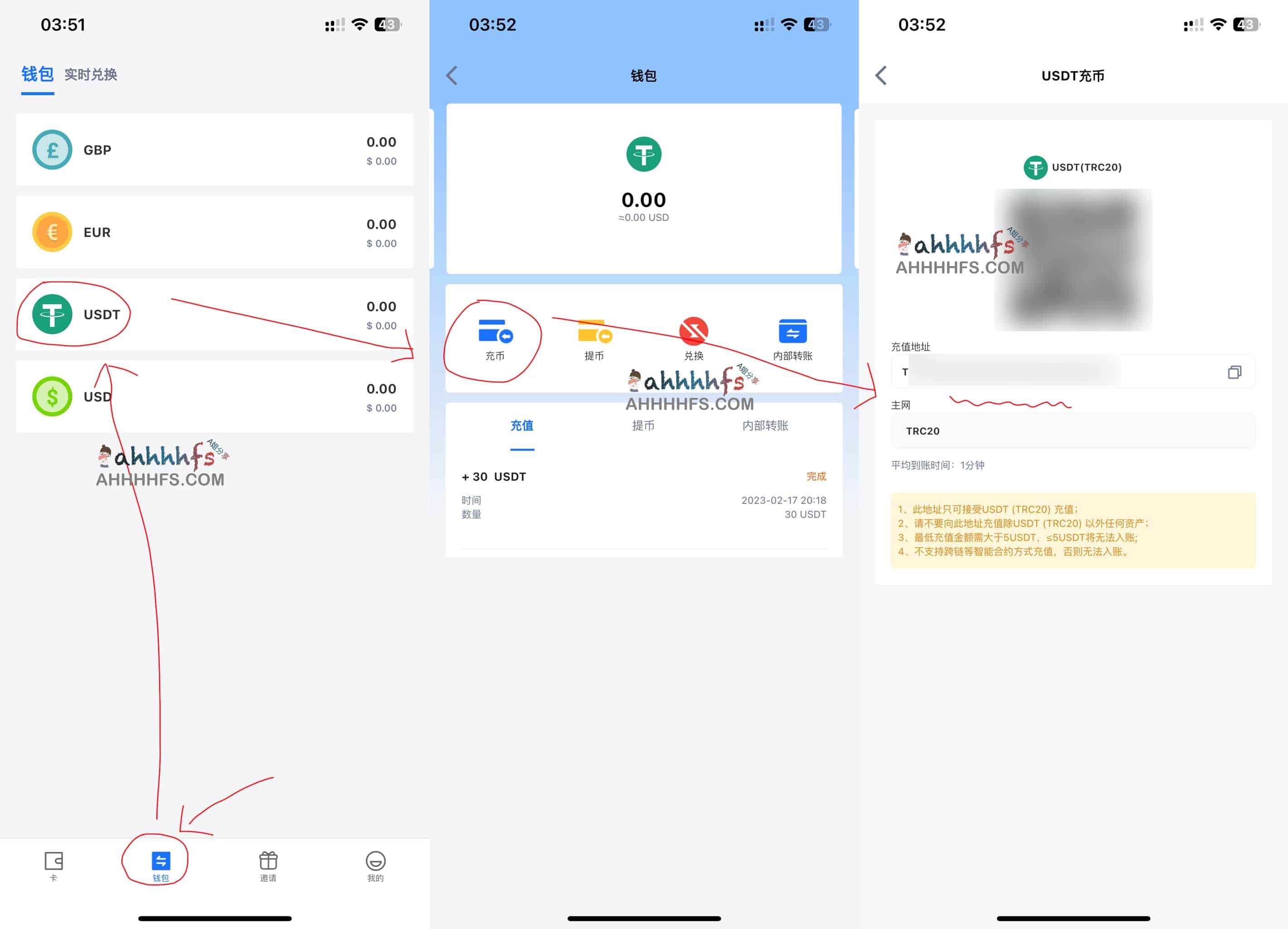
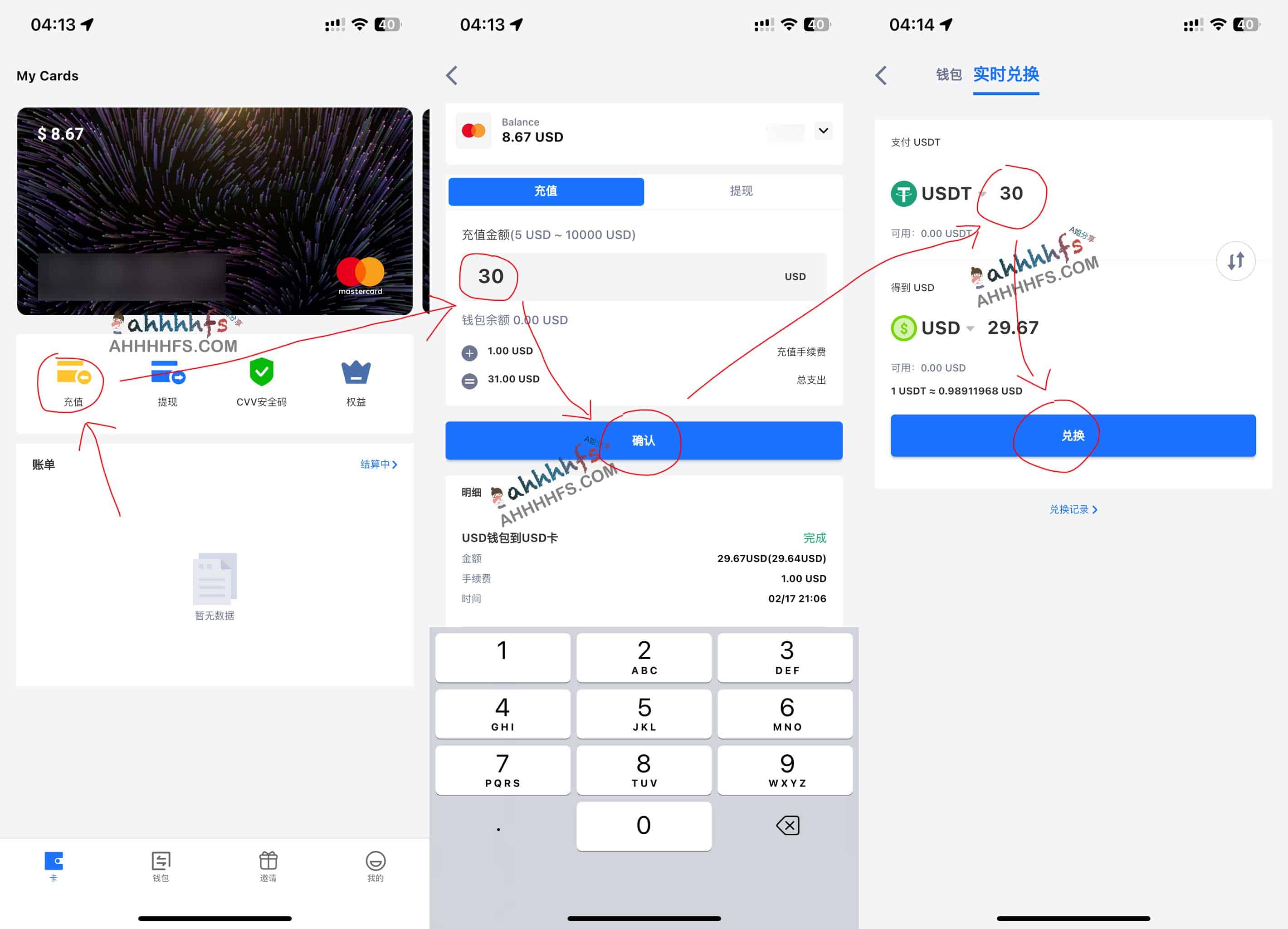
第五步,充值
点“用户头像”——快速充值
充值方式:
- 人民币充值
- USDT
- 美金
以前只有人民币充值的时候,起充金额要500元,现在开通USDT了,只要充值够开卡条件就行了。这里以USDT为例。
点击“USDT充值”
如何获得USDT,可以参考我另一文《Depay虚拟信用卡多种方式获得USDT,解决开卡激活问题,可代充》
先充33USDT试试。
至此:账户名下已经有余额了。
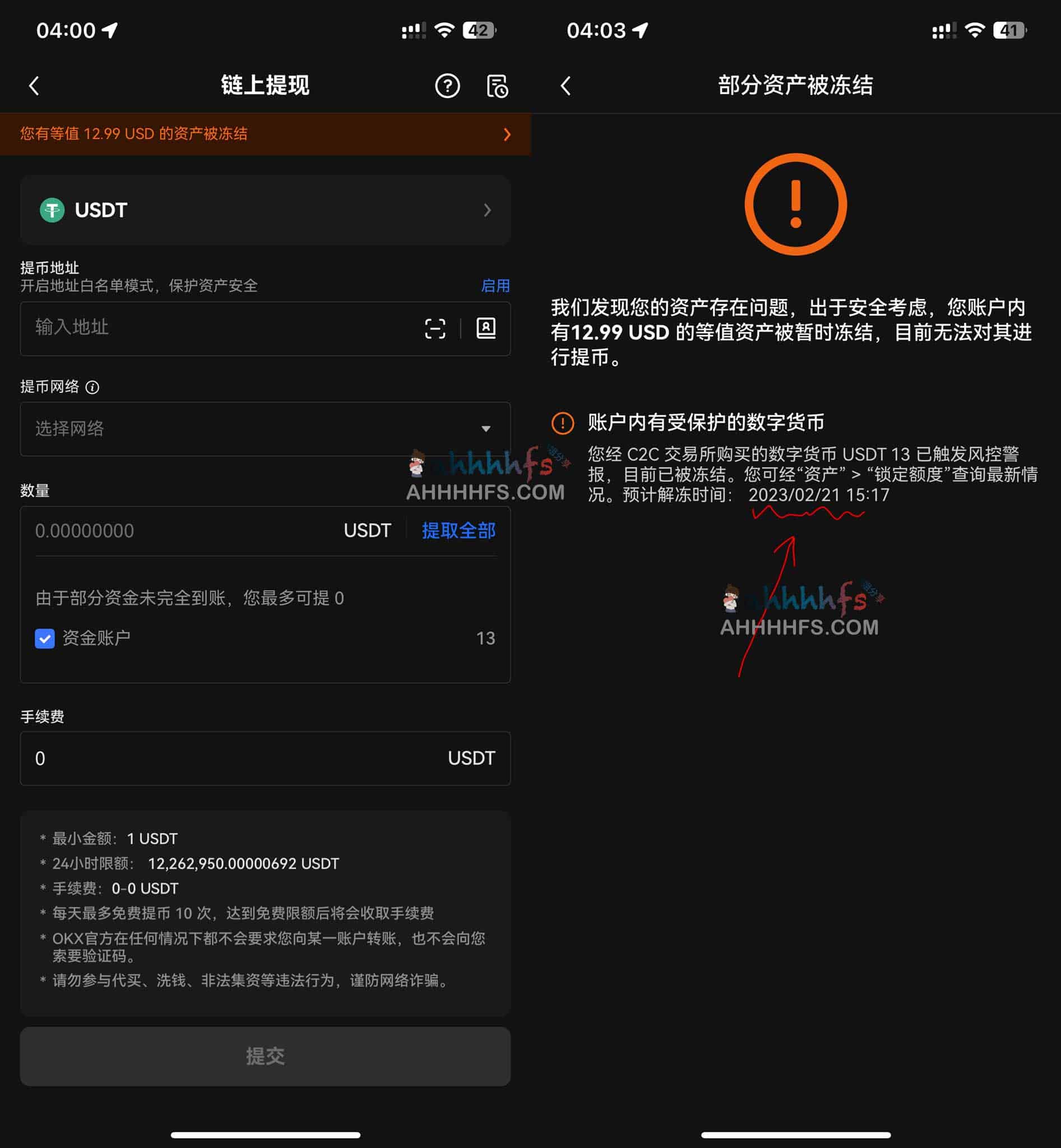
需要注意:
- USDT只能充进去消费,不能提现,也就是不能转账的形式取回USDT,所以根据需要来充值
- 充值也要扣2%的手续费
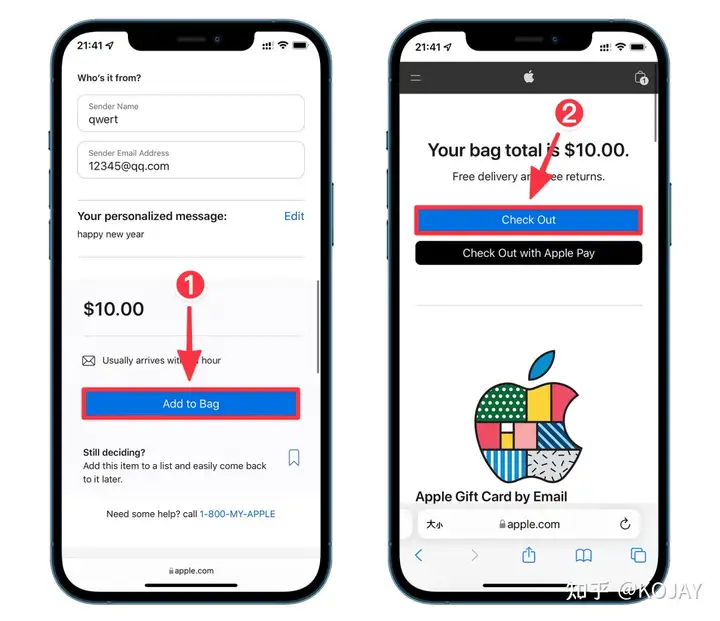
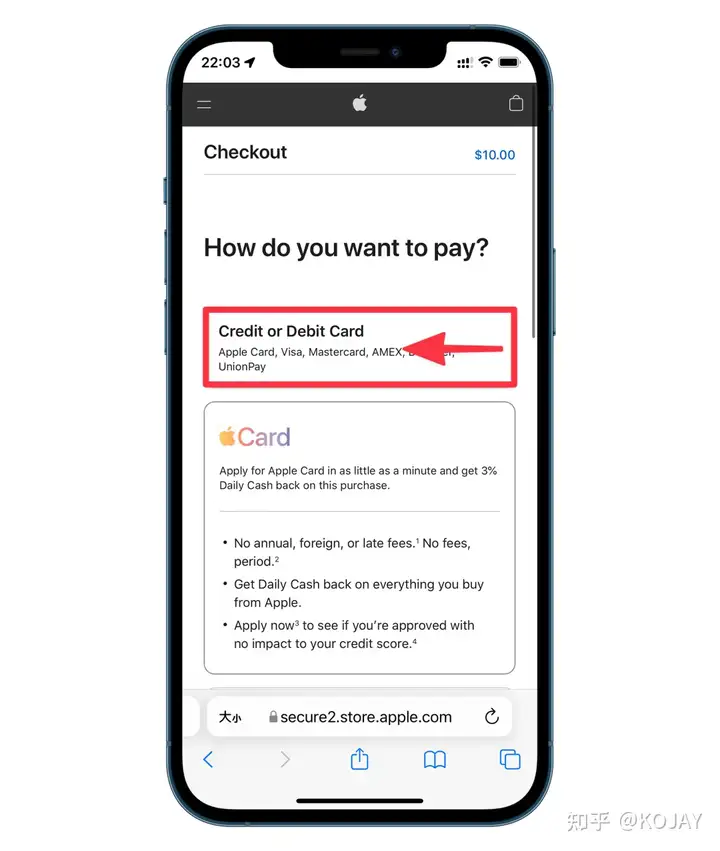
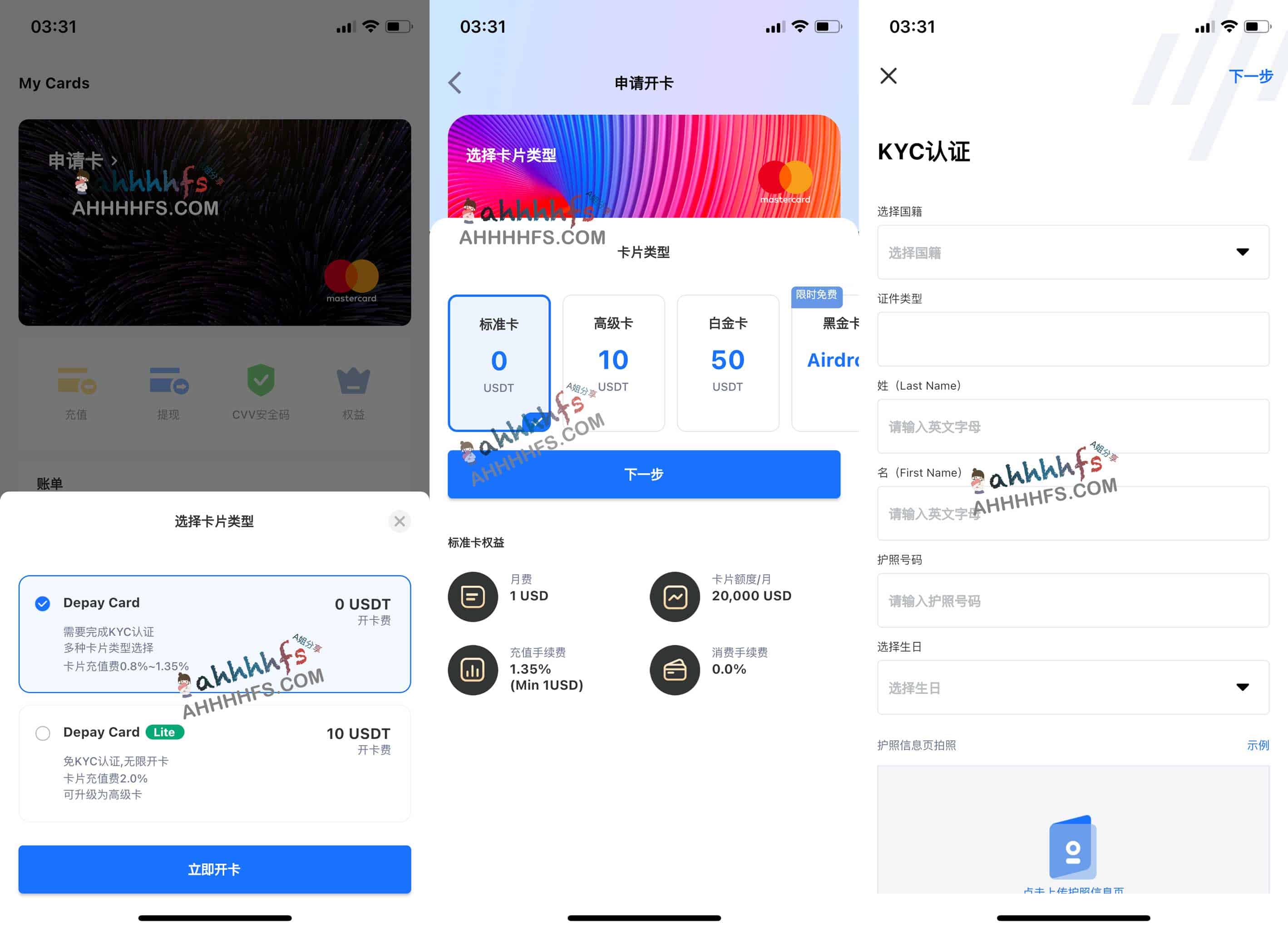
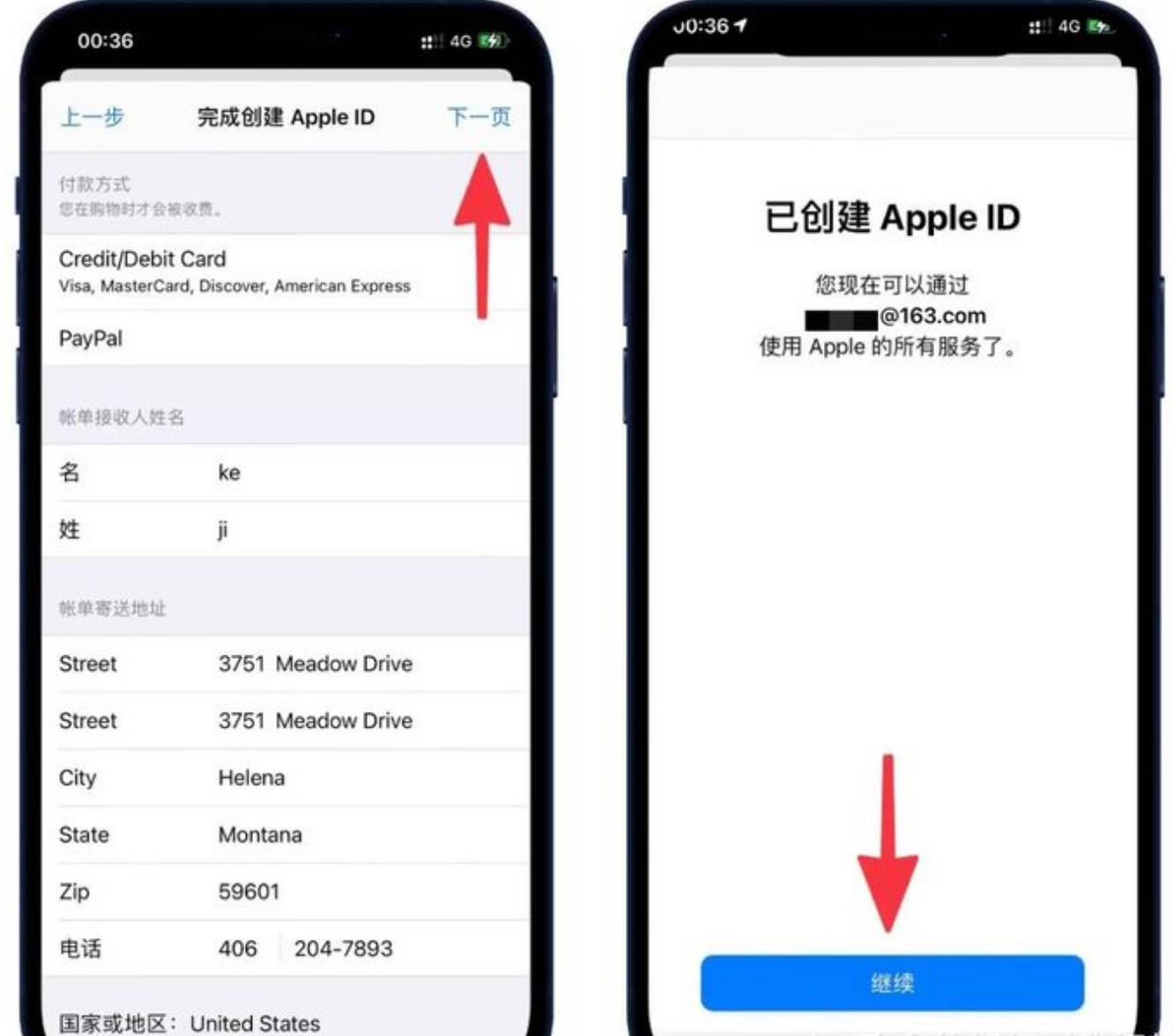
第六步,开卡
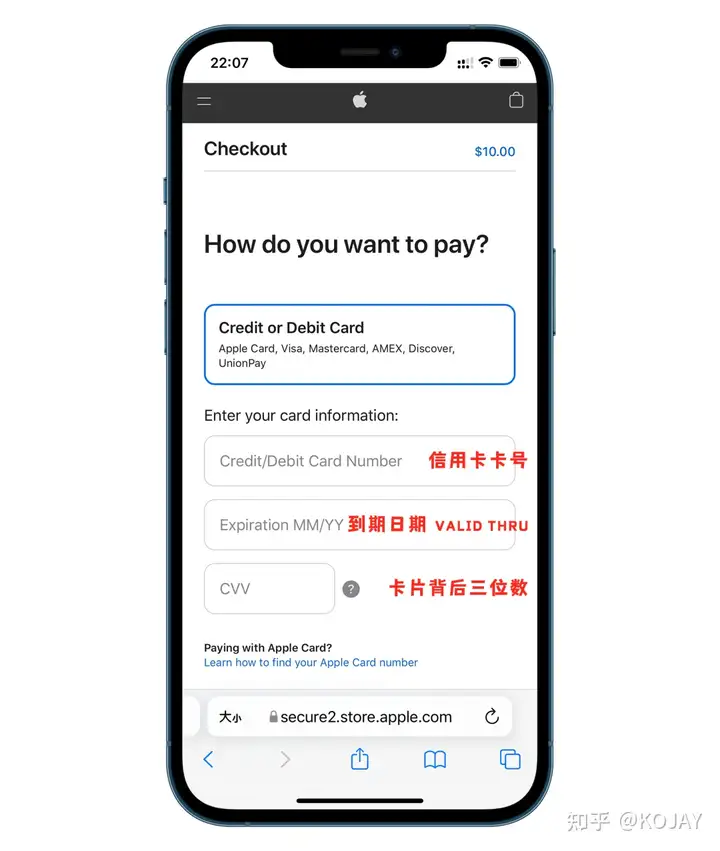
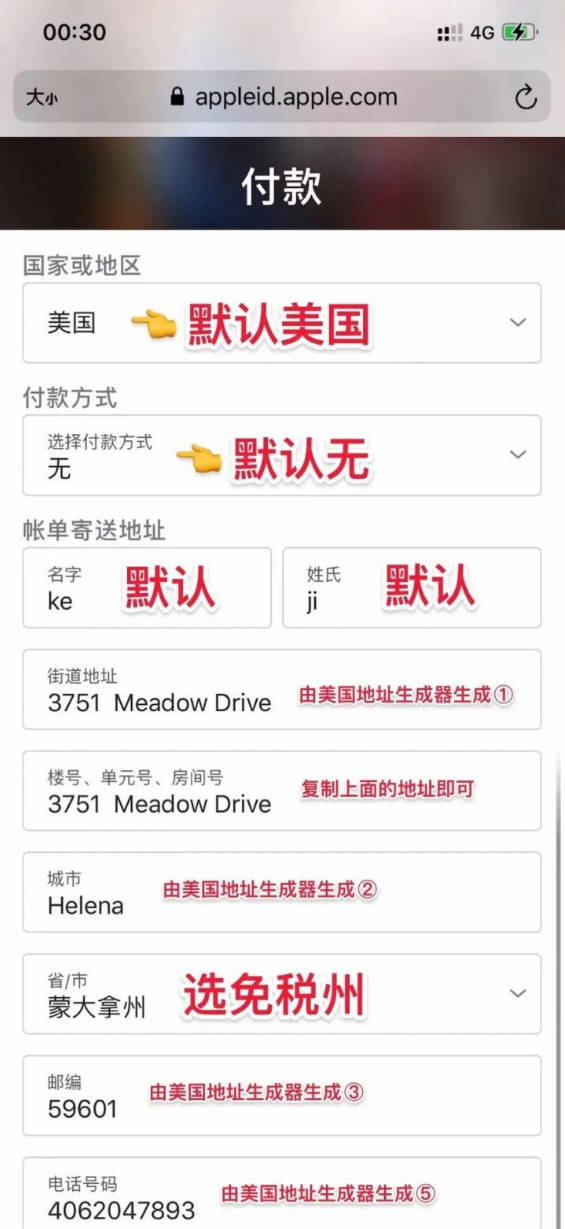
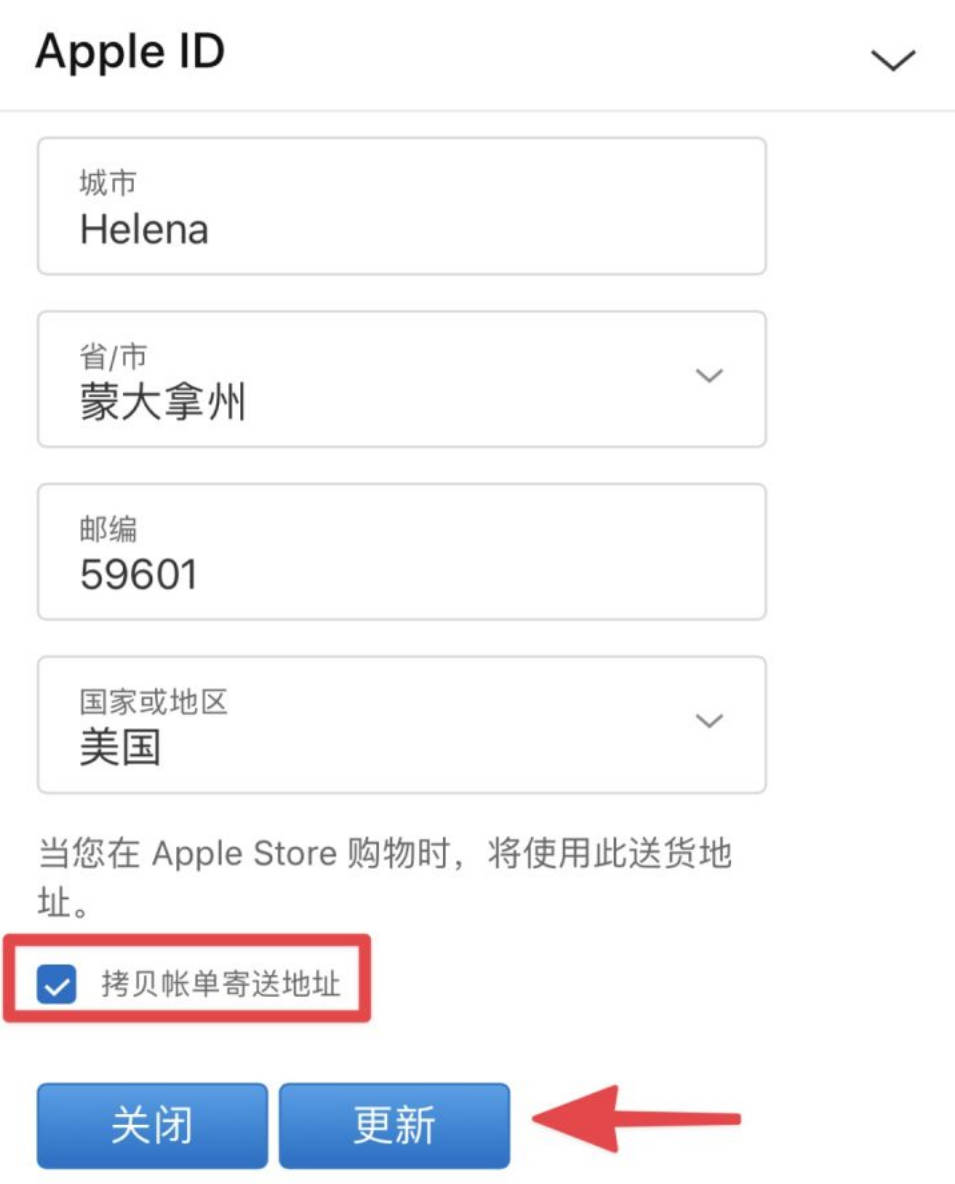
点左边菜单栏——我的卡片——快速开卡——选择556766——填写完信息——开卡
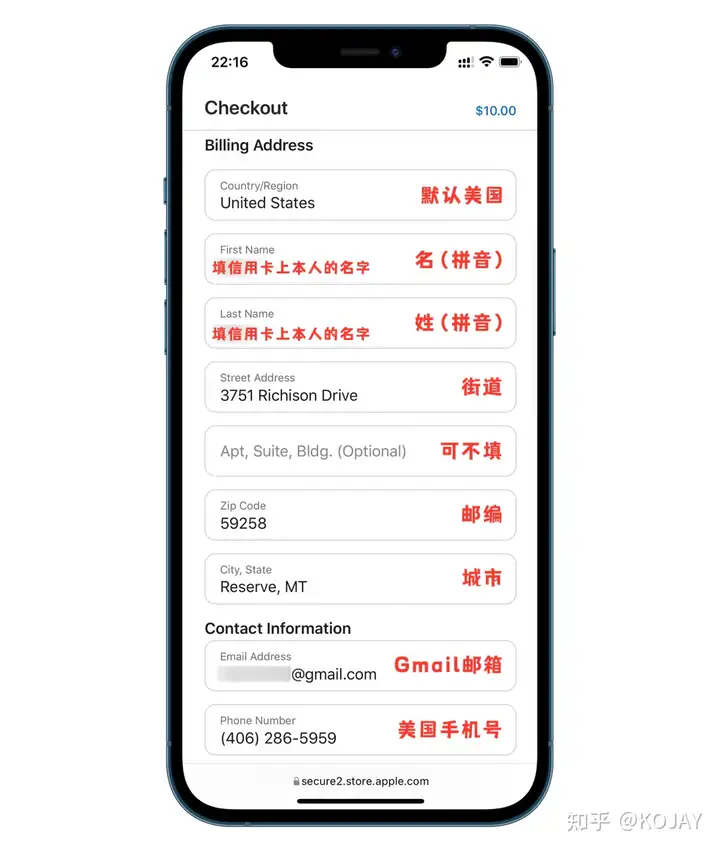
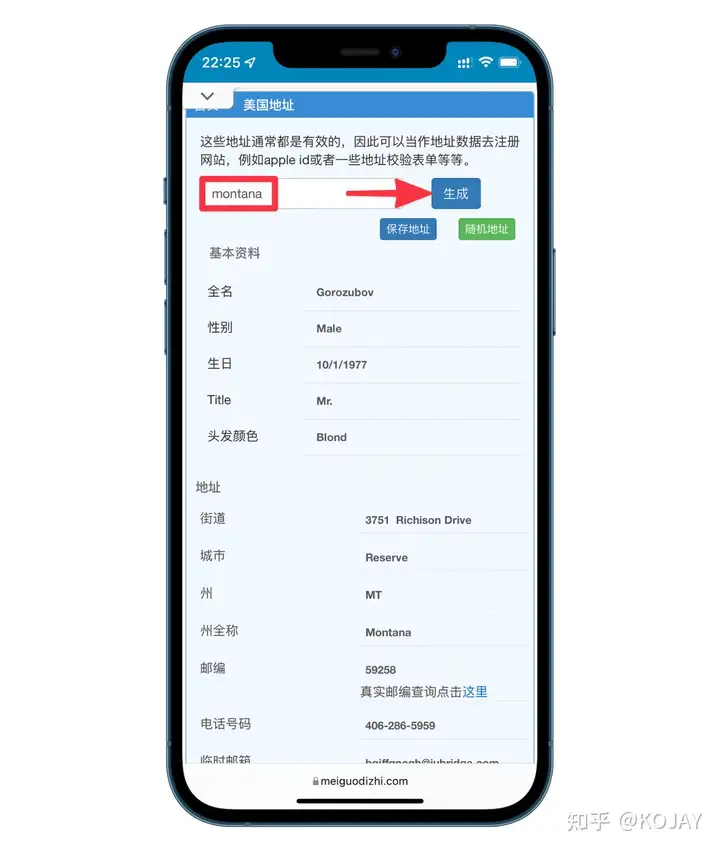
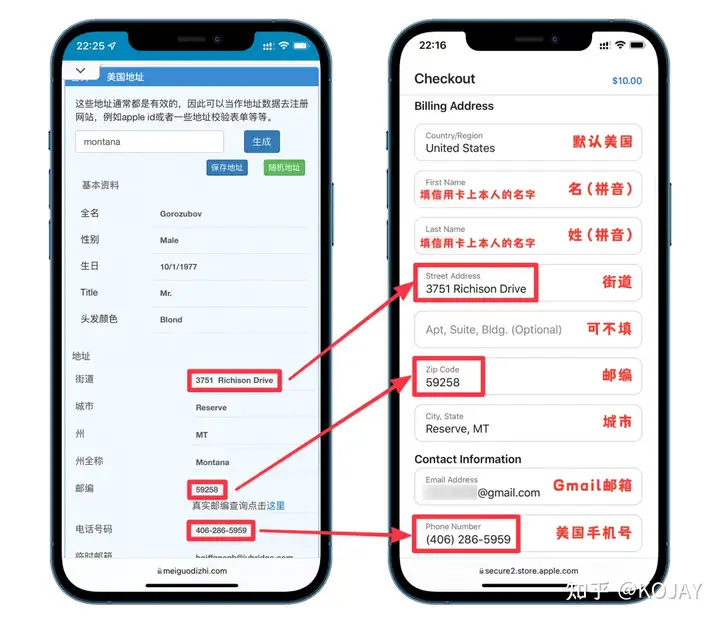
填写信息
如果你不知道什么填写,可以用旁边的“随机地址”
最好是换成自己的姓名,最好是换成自己的姓名。
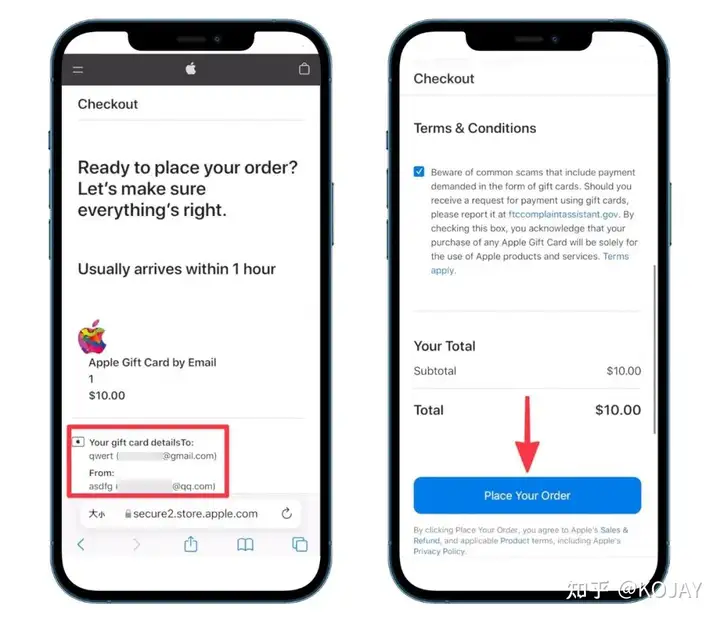
至此:你的卡片就开好了。
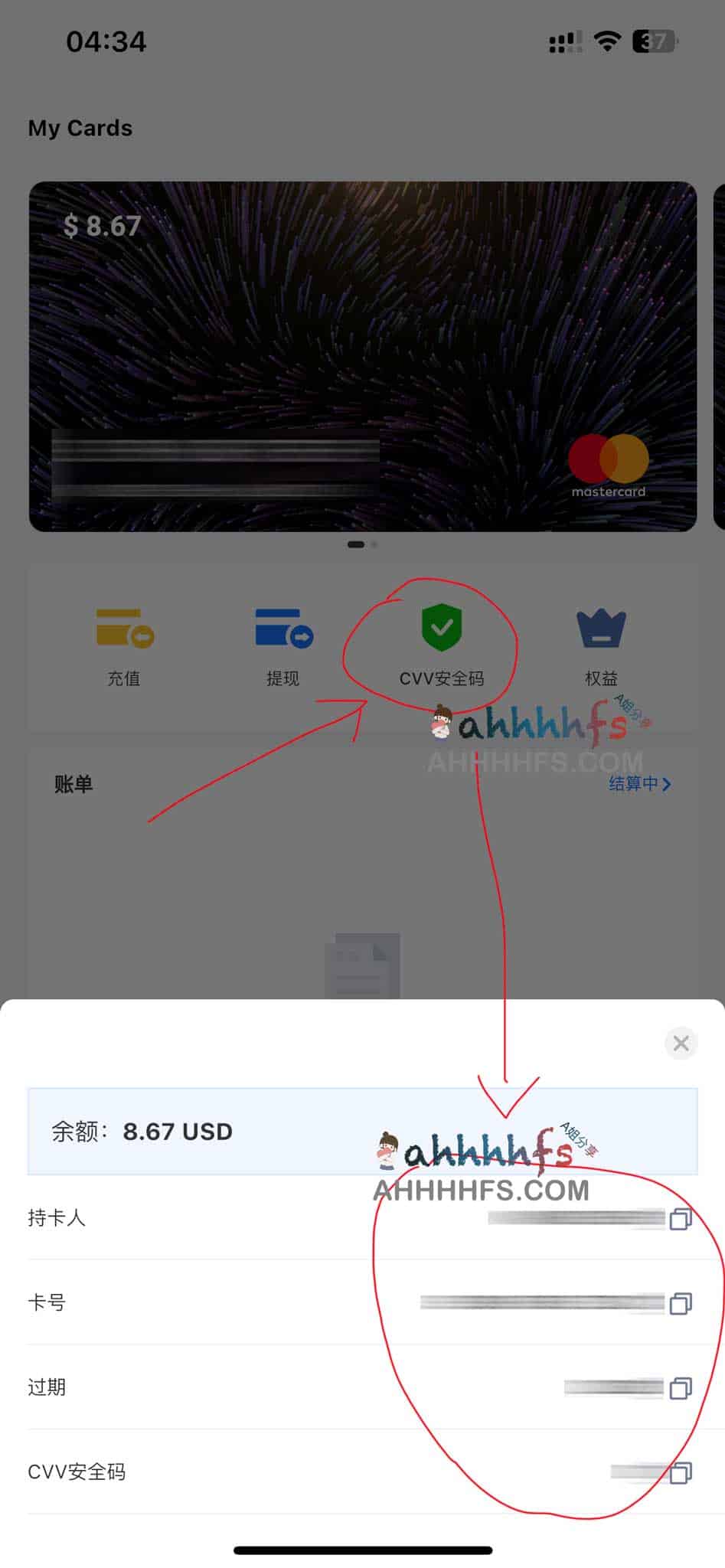
第七步,查看卡片信息
在左边菜单,我的卡片——卡片列表——管理
卡号+Expres+CVV就可以愉快的使用了。
费用明细:
开卡费: 1.00+充值:1.00 + 充值: 30.00 + 服务费: $30.00 * 3.00%
开卡,如果你是用来注册ChatGPT,尽量使用556766卡号段,起充30美金,531847的起充金太多,太多人使用,担心会被拒。
对比
与DePay对比,它每个开卡都要费用,但不用月费,新用户低至1美金,手续费3%,Depay标准卡每个月还是1刀的月费。标准卡充值最少要1刀。
总结
这个场所仅限于进入,禁止出去,且只能用于消费。由于办理你所需要的业务有失败的代价,且代价有点较高,请在尝试前仔细考虑并做好充分准备。建议在此基础上进行深入的思考再决定是否要使用。要么你有USDT,要么充500CNY
链接:https://juejin.cn/post/7214635327406293051
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。