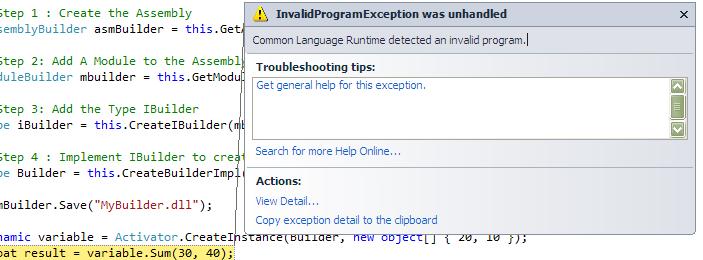
Q 1 What Is CLR?
CLR is a runtime environment. Code that we develop with language compiler that targets the runtime is called managed code. Programmers write code in any .Net language, compile their programs into IL in a portable executable file that can then be managed and executed by CLR. The cross-language integration is possible because language compilers and tools that target the runtime use a common type system defined by the runtime, and they follow the runtime’s rules for defining new types, as well as for creating, using, persisting, and binding to types.
Q 2 What is CLR HOST?
Basically, the CLR acts as a library that can be loaded and “hosted” by a process. You can develop an app that loads and hosts the CLR if you wish; that would allow your app to contain a whole CLR virtual machine, load assemblies and run .NET managed code all within it.
SQL Server 2008, for example, can do this. You can write .NET code that is stored in a SQL Server database and run from within the SQL Server database engine. SQL Server is hosting the CLR to achieve that.
Q 3 What is CTS?
The common type system defines how types are declared, used, and managed in the common language runtime, and is also an important part of the runtime’s support for cross-language integration. The common type system performs the following functions:
Establishes a framework that helps enable cross-language integration, type safety, and high-performance code execution.
Provides an object-oriented model that supports the complete implementation of many programming languages.
Defines rules that languages must follow, which helps ensure that objects written in different languages can interact with each other.
Provides a library that contains the primitive data types (such as Boolean, Byte, Char, Int32, and UInt64) used in application development. All types in the .NET Framework are either value types or reference types.
Value types are data types whose objects are represented by the object’s actual value. If an instance of a value type is assigned to a variable, that variable is given a fresh copy of the value.
Reference types are data types whose objects are represented by a reference (similar to a pointer) to the object’s actual value. If a reference type is assigned to a variable, that variable references (points to) the original value. No copy is made.Classes,Structures,Enumerations,Interfaces,Delegates .
Q 4 What is CLS?
.Net framework uses CLS to fully interact with others objects written in other languages. It is set of guidelines for languages to follow so that it can communicate with other .NET languages in seamless manner.
This is a subset of CTS which all .Net languages are expected to support.
Q 5 What is an Intermediate Language?
MSIL is the CPU independent set of instructions which contains instructions of loading, storing, initializing and calling functions. By using Metadata and CTS, MSIL allows true cross language integration. CIL is an object-oriented assembly language, and is entirely stack-based. Its byte code is translated into native code or — most commonly — executed by a virtual machine.
Q 6 What is Just In Time Compiler?
JIT compiler converts MSIL to native code on demand at application runtime, When the contents of an assembly are loaded and executed. Because CLR supplies a JIT compiler for each supported CPU architecture, Developers can build a set of MSIL assemblies that can be JIT compiled and run on different machine architecture.
Q 7 What is Portable executable (PE)?
Metadata is stored in one section of a .NET Framework portable executable (PE) file, while Microsoft intermediate language (MSIL) is stored in another section of the PE file. The metadata portion of the file contains a series of table and heap data structures. The MSIL portion contains MSIL and metadata tokens that reference the metadata portion of the PE file.
Q 8 What is Managed Code?
In .NET Framework Managed Code runs within the .Net Framework’s CLR and benefits from the services provided by the CLR. When we compile the managed code, the code gets compiled to an intermediate language (MSIL) and an executable is created. When a user runs the executable the Just In Time Compiler of CLR compiles the intermediate language into native code specific to the underlying architecture. Since this translation happens by the managed execution environment (CLR), the managed execution environment can make guarantees about what the code is going to do, because it can actually reason about it. It can insert traps and sort of protection around, if it’s running in a sandboxed environment, it can insert all the appropriate garbage collection hooks, exception handling, type safety, array bounce, index checking and so forth.
Q 9 What is Unmanaged Code?
“Code that is directly executed by the Operating System is known as un-managed code. Typically applications written in VB 6.0, C++, C, etc are all examples of unmanaged code. Unmanaged code typically targets the processor architecture and is always dependent on the computer architecture. Unmanaged code is always compiled to target a specific architecture and will only run on the intended platform. This means that if you want to run the same code on different architecture then you will have to recompile the code using that particular architecture. Unmanaged code is always compiled to the native code which is architecture specific. When we compile unmanaged code it gets compiled into a binary X86 image. And this image always depends on the platform on which the code was compiled and cannot be executed on the other platforms that are different that the one on which the code was compiled. Unmanaged code does not get any services from the managed execution environment.
In unmanaged code the memory allocation, type safety, security, etc needs to be taken care of by the developer. This makes unmanaged code prone to memory leaks like buffer overruns and pointer overrides and so forth.
Unmanaged executable files are basically a binary image, x86 code, loaded into memory. The program counter gets put there and that’s the last the Operating System knows. There are protections in place around memory management and port I/O and so forth, but the system doesn’t actually know what the application is doing.”
Unmanaged Code example like C++, Win32, and COM which compiled into native so they not managed by .net runtime.but as you spend alot of time and money to build them .Net provide Unmanaged Interoperability.
so you can use them into your application and here the word Managed are came into the picture ie the runtime allow to use them but it said i will not managed them its your job to manage them one service that runtime provide to managed code is Garbage Collector its know how to control the lifetime of .net object and memory but it did not know how to clear resource allocated by unmanaged code. so this called unmanaged code and this your responsibility to clear the resource allocated by unmanaged code via implementing IDisposable interface for example.
Q 10 What is Garbage Collector?
The garbage collector manages the allocation and release of memory for your application.
Each time you create a object, the CLR allocates memory for the object from the managed heap.
The garbage collector’s optimizing engine determines the best time to perform a collection, based upon the allocations being made.. When the garbage collector performs a collection, it checks for objects in the managed heap that are no longer being used by the application and performs the necessary operations to reclaim their memory.
Q 11 What is a Strong Name?
A strong name consists of the assembly’s identity — its simple text name, version number, and culture information (if provided) — plus a public key and a digital signature.
You can use strong naming to ensure that when you load a DLL you get exactly the DLL you were expecting and not some other DLL that happens to have the same name.
Strong names guarantee name uniqueness by relying on unique key pairs. No one can generate the same assembly name that you can, because an assembly generated with one private key has a different name than an assembly generated with another private key.
Q 12 What are the steps to create Strong Name?
Open .net command prompt.
Go to the folder containing DLL.
Type sn -k test.snk, you can use any file name instead of test.
This will create test .snk file in that folder.
Open the assemblyinfo.cs file of project.
Type file path in this tag [assembly:AssemblyKeyFile@”C:\Test\bin\Debug\test.snk”)]
Build application, finally your strong name created for your DLL.
Q 13 What are the Problems faced using Strong Name?
Requires Exact Match of the strong name key used
Cannot Lose Private Key – if lost we need to create the whole process again
Q 14 What is Program Database?
PDB files commonly have .pdb extention.When you create a class library project then after compilation,a .dll and .pdb file is created in ProjectRootFolder\bin\Debug.The created pdb file is program database for this project.
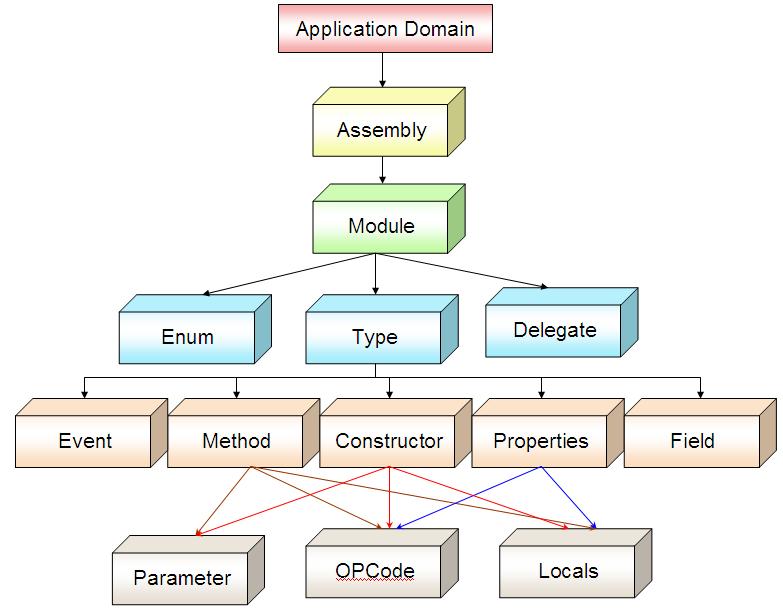
Q 16 What is an Assembly?
A chunk of (precompiled) code that can be executed by the .NET runtime environment. A .NET program consists of one or more assemblies. An assembly is a collection of types and resources that forms a logical unit of functionality.
When you compile an application, the MSIL code created is stored in an assembly .
Assemblies include both executable application files that you can run directly from Windows without the need for any other programs (these have a .exe file extension), and libraries (which have a .dll extension) for use by other applications.
There are two kind of assemblies in .NET;
private shared
Private assemblies are simple and copied with each calling assemblies in the calling assemblies folder.
Shared assemblies (also called strong named assemblies) are copied to a single location (usually the Global assembly cache). For all calling assemblies within the same application, the same copy of the shared assembly is used from its original location. Hence, shared assemblies are not copied in the private folders of each calling assembly. Each shared assembly has a four part name including its face name, version, public key token and culture information. The public key token and version information makes it almost impossible for two different assemblies with the same name or for two similar assemblies with different version to mix with each other.
Q 17 What are the Contents of an Assembly?
The assembly manifest, which contains assembly metadata.Type metadata,MSIL code that implements the types,A set of resources.
Q 18 What are Types of an Assemblies?
Private Assembly: – An assembly is used only for a particular application. It is stored in the application’s directory otherwise in the application’s sub directory. There is no version constraint in private assembly.
Public/shared Assembly:- It has version constraint. This public assembly is stored inside the global assembly cache or GAC.GAC contains a collection of shared assemblies.
A .NET Framework assembly containing resources specific to a given language. Using satellite assemblies, you can place the resources for different languages in different assemblies, and the correct assembly is loaded into memory only if the user elects to view the application in that language.”
Q 19 What is a Satellite assembly?
A satellite assembly is a .NET Framework assembly containing resources specific to a given language. Using satellite assemblies, you can place resources for different languages in different assemblies, and the correct assembly is loaded into memory only if the user selects to view the application in that language.
Q 20 What are Steps to Create Satellite Assembly?
Create a folder with a specific culture name (for example, en-US) in the application’s bin\debug folder.
Create a .resx file in that folder. Place all translated strings into it.
Create a .resources file by using the following command from the .NET command prompt. (localizationsample is the name of the application namespace. If your application uses a nested namespace structure like MyApp.YourApp.MyName.YourName as the type of namespace, just use the uppermost namespace for creating resources files—MyApp.)
resgen Strings.en-US.resx LocalizationSample.
Strings.en-US.resources
al /embed:LocalizationSample.Strings.en-US.resources
/out:LocalizationSample.resources.dll /c:en-US
The above step will create two files, LocalizationSample.Strings.en-US.resources and LocalizationSample.resources.dll. Here, LocalizationSample is the name space of the application.
In the code, find the user’s language; for example, en-US. This is culture specific.
Give the assembly name as the name of .resx file. In this case, it is Strings.
Q 21 What is an Assembly Loader?
The first thing the .NET assembly loader checks is whether the assembly is strongly signed. If it is, it will start its search in the Global Assembly Cache .
The loader will search for a policy file named in the format of:
policy.AssemblyMajorVersion.AssembyMinorVersion.AssemblyName
For example:
Policy.1.2.MyAssembly
If such a file exists it will look inside of it if the version of the assembly that we are trying to load matches the version/versions range written in the policy file. If it does, it will try to load the assembly with the version specified there. If no such policy file exists, it will try to load the assembly from the GAC.
If it will fail to find it in the GAC, it will start to search in the system’s search path.
In web applications it will also include the application’s Bin directory in the search path.
You can manually add folders to an AppDomain’s search path by using the “AppendPrivatePath” method.
Q 22 What is Multi Module Assembly or Assembly Linker?
An assembly is called Multi Module assembly if it refers to multiple files. It can be combinations of modules written in different languages. When we link different modules into final assembly, the hash of each module is recorded in the manifest file.
link.exe is used to link multiple modules
as
c:\>more a1.vb
c:\>more b1.cs
c:\>vbc /t:module a1.vb
c:\>csc /addmodule:a1.netmodule /t:module b1.cs
c:\>link /entry:MainClinetApp.Main /out:main.exe b1.netmodule a1.module
Q 23 What is an Assembly Manifest?
Assembly Manifest contains
Assembly Name,
Version number,
Culture,
Strong Name Information,
List of all files in the assembly,
Type Reference information,
Information on referenced assemblies.
Q 24 What is a Metadata?
COM provided a step towards solving this problem. The .NET Framework makes component interoperation even easier by allowing compilers to emit additional declarative information into all modules and assemblies. This information, called metadata, helps components to interact seamlessly.
Metadata is binary information describing your program that is stored either in a common language runtime portable executable (PE) file or in memory. When you compile your code into a PE file, metadata is inserted into one portion of the file, and your code is converted to Microsoft intermediate language (MSIL) and inserted into another portion of the file. Every type and member that is defined and referenced in a module or assembly is described within metadata. When code is executed, the runtime loads metadata into memory and references it to discover information about your code’s classes, members, inheritance, and so on.
Q 25 What is a Base class in .Net?
A base class, in the context of C#, is a class that is used to create, or derive, other classes. Classes derived from a base class are called child classes, subclasses or derived classes. A base class does not inherit from any other class and is considered parent of a derived class. Base class members (constructor, an instance method or instance property accessor) are accessed in derived class using the “base” keyword.
Base classes are automatically instantiated before derived classes.
Derived class can communicate to the base class during instantiation by calling the base class constructor with a matching parameter list.
Base class members can be accessed from the derived class through an explicit cast.
Since a base class itself can be a derived class, a class may have many base classes.
Members of a derived class can access the public, protected, internal and protected internal members of a base class.
Due to the transitive nature of inheritance, although a derived class has only one base class, it inherits the members declared in the parent of the base class.
By declaring a method in base class as virtual, the derived class can override that method with its own implementation. Both the overridden and overriding method and property must have the same access-level modifiers such as virtual, abstract or override.
When the keyword “abstract” is used for a method, it should be overridden in any nonabstract class that directly inherits from that class.
Abstract base classes are created using the “abstract” keyword in its declaration and are used to prevent direct initiation using the “new” keyword. They can only be used through derived classes that implement abstract methods.
A base class can prevent other classes from inheriting from it by declaring all the members as “sealed.”
Base class members can be hidden in a derived class by using the keyword “new” to indicate that the member is not intended to be an override of the base member. If “new” is not used, the compiler generates a warning.
Q 26 What is Full Assembly Reference?
Full Assembly reference: A full assembly reference includes the assembly’s text name, version, culture, and public key token (if the assembly has a strong name). A full assembly reference is required if you reference any assembly that is part of the common language runtime or any assembly located in the global assembly cache.
Partial Assembly reference: We can dynamically reference an assembly by providing only partial information, such as specifying only the assembly name. When you specify a partial assembly reference, the runtime looks for the assembly only in the application directory. We can make partial references to an assembly in your code one of the following ways:
Use a method such as System.Reflection.Assembly.Load and specify only a partial reference. The runtime checks for the assembly in the application directory.
Use the System.Reflection.Assembly.LoadWithPartialName method and specify only a partial reference. The run time checks for the assembly in the application directory and in the global assembly cache.
Q 28 What is an Assembly Qualified Name?
Type objType = typeof(System.Array);
// Print the full assembly name.
Console.WriteLine (“Full assembly name:\n {0}.”,
objType.Assembly.FullName.ToString());
// Print the qualified assembly name.
Console.WriteLine (“Qualified assembly name:\n {0}.”,
objType.AssemblyQualifiedName.ToString());
Q 29 What is ILDASM (Intermediate Language Disassembler)?
The Ildasm.exe parses any .NET Framework .exe or .dll assembly, and shows the information in human-readable format. Ildasm.exe shows more than just the Microsoft intermediate language (MSIL) code — it also displays namespaces and types, including their interfaces. You can use Ildasm.exe to examine native .NET Framework assemblies, such as Mscorlib.dll, as well as .NET Framework assemblies provided by others or created yourself. Most .NET Framework developers will find Ildasm.exe indispensable.http://msdn.microsoft.com/en-us/library/aa309387(v=vs.71).aspx
Q 30 What is Global Assembly Cache?
The global assembly cache stores assemblies specifically designated to be shared by several applications on the computer.
Q 31 What is an Attribute?
Attributes provide a powerful method of associating declarative information with C# code (types, methods, properties, and so forth). Once associated with a program entity, the attribute can be queried at run time and used in any number of ways.
Q 32 What is Serialization & Deserialization?
Serialization is the process of converting the state of an object into a form that can be persisted in a storage medium or transported across the processes/machines. The opposite of serialization is deserialization which is a process that converts the outcome of serialization into the original object.
Q 33 Where Serialization is used?
Communication: If you have two machines that are running the same code, and they need to communicate, an easy way is for one machine to build an object with information that it would like to transmit, and then serialize that object to the other machine. It’s not the best method for communication, but it gets the job done.
Persistence: If you want to store the state of a particular operation in a database, it can be easily serialized to a byte array, and stored in the database for later retrieval.
Deep Copy: If you need an exact replica of an Object, and don’t want to go to the trouble of writing your own specialized clone() class, simply serializing the object to a byte array, and then de-serializing it to another object achieves this goal.
Caching: Really just an application of the above, but sometimes an object takes 10 minutes to build, but would only take 10 seconds to de-serialize. So, rather than hold onto the giant object in memory, just cache it out to a file via serialization, and read it in later when it’s needed.
Serialization is useful any time you want to move a representation of your data into or out of your process boundary.
Saving an object to disk is a trivial example you’ll see in many tutorials.
More commonly, serialization is used to transfer data to and from a web service, or to persist data to or from a database.
Q 34 What are the types of Serialization available in .net?
Serialization can be Binary,SOAP or XML.
Q 35 What is Binary Serialization?
Binary serialization is the process where you convert your .NET objects into byte stream. In binary serialization all the public, private, even those which are read only, members are serialized and converted into bytes. So when you want a complete conversion of your objects to bytes then one can make use of binary serialization.In XML serialization only the public properties and fields of the objects are converted into XML. The private members are not taken into consideration in XML serialization.
Similar to XML serialization. When you serialize object to SOAP format it conforms to the SOAP specification.Binary Serialization: Light and compact used in Remoting
SOAP Serialization : Interoperable use SOAP and used in web Services
XML Serialization : Custom Serialization .
Q 36 What are the Advantages & Disadvantages of Binary Serialization?
Advantages of Binary Serialization
Object can be de-serialized from the same data you serialized it to.
Enhanced performance as it is faster and even more powerful in the sense that it provides support for complex objects, read only properties and even circular references.
Disadvantage of Binary Serialization: It is not easily portable to another platform.
Q 37 What is SOAP Serialization?
To support SOAP serialization, the .NET Framework provides the SoapFormatter class. This class is defined in the System.Runtime.Serialization.Formatters.Soap namespace that is part of the System.Runtime.Serialization.Formatters.Soap.dll assembly. In order to use The SoapFormatter class, you must reference this assembly. Then, you can create an object and initialize it as you see fit. Before saving it, as always, create a Stream-based object that would indicate the name (and location) of the file and the type of action to perform. Then, declare a SoapFormatter variable using its default constructor. To actually save the object, call the Serialize() method of this class. This method uses the same syntax as that of the BinaryFormatter class: it takes two arguments. The first is a Stream-based object. The second is the object that needs to be serialized.Typically the serialization process consists of creation of the serializer, opening of the stream and invocation of the serializer.
Q 38 What is Advantages of SOAP Serialization?
If you want full Type fidelity, and the “stability” that you are talking about you should use Soap Serialization. Soap Serialization preserves the
full type information.
XML Serialization is intended more for interoperability with other Operating Systems, and does not preserve all type information.
Q 39 What is a XML Serialization?
XML serialization serializes only the public fields and property values of an object into an XML stream. XML serialization does not include type information. For example, if you have a Book object that exists in the Library namespace, there is no guarantee that it is deserialized into an object of the same type.XML serialization does not convert methods, indexers, private fields, or read-only properties (except read-only collections). To serialize all an object’s fields and properties, both public and private, use the DataContractSerializer instead of XML serialization.
Q 40 What are the Advantages of XML Serialization?
The advantages of XML Serialization are as follows:
· XML based
· Support for cross platforms
· Easily readable and editable
Q 41 >What is Custom Serialization?
Custom serialization is the process of controlling the serialization and deserialization of a type. By controlling serialization, it is possible to ensure serialization compatibility, which is the ability to serialize and deserialize between versions of a type without breaking the core functionality of the type. For example, in the first version of a type, there may be only two fields. In the next version of a type, several more fields are added. Yet the second version of an application must be able to serialize and deserialize both types. The following sections describe how to control serialization.
Q 42 What is a Namespace?
The namespace keyword is used to declare a scope that contains a set of related objects. You can use a namespace to organize code elements and to create globally unique types.
Q 43 What is GUID?
A Globally Unique Identifier is a unique reference number used as an identifier.
The term GUID typically refers to various implementations of the universally unique identifier (UUID) standard.GUIDs are usually stored as 128-bit values, and are commonly displayed as 32 hexadecimal digits with groups separated by hyphens, such as {21EC2020-3AEA-4069-A2DD-08002B30309D}.the total number of unique such GUIDs is 2122 or 5.3×1036.
Q 44 What is a Formatter?
A formatter is an object that is responsible for encoding and serializing data into messages on one end, and deserializing and decoding messages into data on the other end.
Q 45 What is a Binary Formatter?
Serializes and deserializes an object, or an entire graph of connected objects, in binary format.
[ComVisibleAttribute(true)]
public sealed class BinaryFormatter : IRemotingFormatter, Iformatter
Q 46 What is a SOAP Formatter?
Serializes and deserializes an object, or an entire graph of connected objects, in SOAP format.
Q 47 What is Reflection?
Reflection provides objects (of type Type) that describe assemblies, modules and types. You can use reflection to dynamically create an instance of a type, bind the type to an existing object, or get the type from an existing object and invoke its methods or access its fields and properties. If you are using attributes in your code, reflection enables you to access them.
Reflection is useful in the following situations:
When you have to access attributes in your program’s metadata.
Retrieving Information Stored in Attributes.
For examining and instantiating types in an assembly.
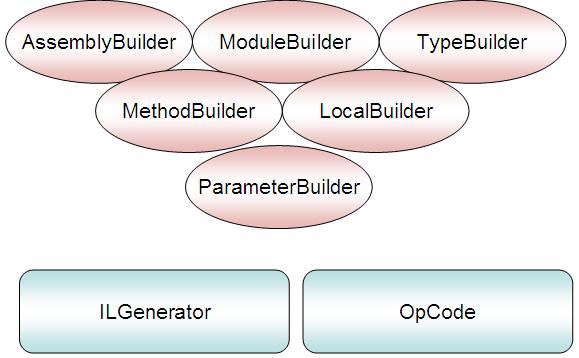
For building new types at runtime. Use classes in System.Reflection.Emit.
For performing late binding, accessing methods on types created at run time.
Q 48 What is Thread and Process?
A process, in the simplest terms, is an executing program. One or more threads run in the context of the process. A thread is the basic unit to which the operating system allocates processor time. A thread can execute any part of the process code, including parts currently being executed by another thread.
Q 49 What are the difference between a Dll and an Exe?
EXE:
It’s a executable file
When loading an executable, no export is called, but only the module entry point.
When a system launches new executable, a new process is created
The entry thread is called in context of main thread of that process.
DLL:
It’s a Dynamic Link Library
There are multiple exported symbols.
The system loads a DLL into the context of an existing process.
Q 50 What are Globalization and Localization?
Globalization is the process of designing and developing applications that function for multiple cultures. Localization is the process of customizing your application for a given culture and locale.
References:

from:http://www.sqlservercentral.com/blogs/querying-microsoft-sql-server/2014/04/16/top-50-net-framework-interview-and-general-faqs/