1. 选择现成的项目模板还是自己搭建项目骨架
搭建一个前端项目的方式有两种:选择现成的项目模板、自己搭建项目骨架。
选择一个现成项目模板是搭建一个项目最快的方式,模板已经把基本的骨架都搭建好了,你只需要向里面填充具体的业务代码,就可以通过内置的工具与命令构建代码、部署到服务器等。
一般来说,一个现成的项目模板会预定义一定的目录结构、书写方式,在编写项目代码时需要遵循相应的规范;也会内置必要的工具,比如 .editorconfig、eslint、stylelint、prettier、husky、lint-staged 等;也会内置必要的命令(package.json | scripts),比如 本地开发:npm run dev、本地预览:npm run start、构建:npm run build、部署:npm run deploy等。
社区比较好的项目模板:
这些模板的使用又分为两种:使用 git 直接克隆到本地、使用命令行创建。
(使用现有模板构建的项目,可以跳过第 2 ~ 7 步)
1.1 使用 git 直接克隆到本地
这是一种真正意义上的模板,可以直接到模板项目的 github 主页,就能看到整个骨架,比如 react-boilerplate、ant-design-pro、vue-element-admin、react-starter-kit。
以 react-boilerplate 为例:
克隆到本地:
git clone --depth=1 https:
切换到目录下:
cd <你的项目名字>
一般来说,接下来运行 npm run install 安装项目的依赖后,就可以运行;有些模板可能有内置的初始化命令,比如 react-boilerplate:
npm run setup
启动应用:
npm start
这时,就可以在浏览器中预览应用了。
1.2 使用命令行创建
这种方式需要安装相应的命令,然后由命令来创建项目。
以 create-react-app 为例:
安装命令:
npm install -g create-react-app
创建项目:
create-react-app my-app
运行应用:
cd my-app
npm start
1.3 自己搭建项目骨架
如果你需要定制化,可以选择自己搭建项目的骨架,但这需要开发者对构建工具如 webpack、npm、node 及其生态等有相当的了解与应用,才能完美的把控整个项目。
下面将会一步一步的说明如何搭建一个定制化的项目骨架。
2. 选择合适的规范来写代码
js 模块化的发展大致有这样一个过程 iife => commonjs/amd => es6,而在这几个规范中:
iife: js 原生支持,但一般不会直接使用这种规范写代码amd: requirejs 定义的加载规范,但随着构建工具的出现,便一般不会用这种规范写代码commonjs: node 的模块加载规范,一般会用这种规范写 node 程序es6: ECMAScript2015 定义的模块加载规范,需要转码后浏览器才能运行
这里推荐使用 es6 的模块化规范来写代码,然后用工具转换成 es5 的代码,并且 es6 的代码可以使用 Tree shaking 功能。
参考:
3. 选择合适的构建工具
对于前端项目来说,构建工具一般都选用 webpack,webpack 提供了强大的功能和配置化运行。如果你不喜欢复杂的配置,可以尝试 parcel。
参考:
4. 确定是单页面应用(SPA)还是多页面应用
因为单页面应用与多页面应用在构建的方式上有很大的不同,所以需要从项目一开始就确定,使用哪种模式来构建项目。
4.1 多页面应用
传统多页面是由后端控制一个 url 对应一个 html 文件,页面之间的跳转需要根据后端给出的 url 跳转到新的 html 上。比如:
http:
http:
http:
这种方式的应用,项目里会有多个入口文件,搭建项目的时候就需要对这种多入口模式进行封装。另外,也可以选择一些封装的多入口构建工具,如 lila。
4.2 单页面应用
单页面应用(single page application),就是只有一个页面的应用,页面的刷新和内部子页面的跳转完全由 js 来控制。
一般单页面应用都有以下几个特点:
- 本地路由,由
js 定义路由、根据路由渲染页面、控制页面的跳转
- 所有文件只会加载一次,最大限度重用文件,并且极大提升加载速度
- 按需加载,只有真正使用到页面的时候,才加载相应的文件
这种方式的应用,项目里只有一个入口文件,便无需封装。
参考:
5. 选择合适的前端框架与 UI 库
一般在搭建项目的时候就需要定下前端框架与 UI 库,因为如果后期想更换前端框架和 UI 库,代价是很大的。
比较现代化的前端框架:
一些不错的组合:
参考:
6. 定好目录结构
一个好的目录结构对一个好的项目而言是非常必要的。
一个好的目录结构应当具有以下的一些特点:
- 解耦:代码尽量去耦合,这样代码逻辑清晰,也容易扩展
- 分块:按照功能对代码进行分块、分组,并能快捷的添加分块、分组
- 编辑器友好:需要更新功能时,可以很快的定位到相关文件,并且这些文件应该是很靠近的,而不至于到处找文件
比较推荐的目录结构:
多页面应用
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
单页面应用
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考:
7. 搭建一个好的脚手架
搭建一个好的脚手架,能够更好的编写代码、构建项目等。
可以查看 搭建自己的前端脚手架 了解一些基本的脚手架文件与工具。
比如:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考:
=================================================
到这里为止,一个基本的项目骨架就算搭建好了。
8. 使用版本控制系统管理源代码(git)
项目搭建好后,需要一个版本控制系统来管理源代码。
比较常用的版本管理工具有 git、svn,现在一般都用 git。
一般开源的项目可以托管到 http://github.com,私人的项目可以托管到 https://gitee.com、https://coding.net/,而企业的项目则需要自建版本控制系统了。
自建版本控制系统主要有 gitlab、gogs、gitea:gitlab 是由商业驱动的,比较稳定,社区版是免费的,一般建议选用这个;gogs, gitea 是开源的项目,还不太稳定,期待进一步的更新。
所以,git + gitlab 是不错的配合。
9. 编写代码
编写代码时,js 选用 es6 的模块化规范来写(如果喜欢用 TypeScript,需要加上 ts-loader),样式可以用 less、scss、css 来写。
写 js 模块文件时,注释可以使用 jsdoc 的规范来写,如果配置相应的工具,可以将这些注释导出接口文档。
因为脚手架里有 husky、lint-staged 的配合,所以每次提交的代码都会进行代码审查与格式优化,如果不符合规范,则需要把不规范的代码进行修改,然后才能提交到代码仓库中。
比如 console.log(haha.hehe); 这段代码就会遇到错误,不予提交:

这个功能定义在 package.json 中:
{
"devDependencies": { 工具依赖
"babel-eslint": "^8.2.6",
"eslint": "^4.19.1",
"husky": "^0.14.3",
"lint-staged": "^7.2.0",
"prettier": "^1.14.0",
"stylelint": "^9.3.0",
"eslint-config-airbnb": "^17.0.0",
"eslint-config-prettier": "^2.9.0",
"eslint-plugin-babel": "^5.1.0",
"eslint-plugin-import": "^2.13.0",
"eslint-plugin-jsx-a11y": "^6.1.0",
"eslint-plugin-prettier": "^2.6.2",
"eslint-plugin-react": "^7.10.0",
"stylelint-config-prettier": "^3.3.0",
"stylelint-config-standard": "^18.2.0"
},
"scripts": { 可以添加更多命令
"precommit": "npm run lint-staged",
"prettier": "prettier --write \"./**/*.{js,jsx,css,less,sass,scss,md,json}\"",
"eslint": "eslint .",
"eslint:fix": "eslint . --fix",
"stylelint": "stylelint \"./**/*.{css,less,sass,scss}\"",
"stylelint:fix": "stylelint \"./**/*.{css,less,sass,scss}\" --fix",
"lint-staged": "lint-staged"
},
"lint-staged": { 对提交的代码进行检查与矫正
"**/*.{js,jsx}": [
"eslint --fix",
"prettier --write",
"git add"
],
"**/*.{css,less,sass,scss}": [
"stylelint --fix",
"prettier --write",
"git add"
],
"**/*.{md,json}": [
"prettier --write",
"git add"
]
}
}
- 如果你想禁用这个功能,可以把
scripts 中 "precommit" 改成 "//precommit"
- 如果你想自定
eslint 检查代码的规范,可以修改 .eslintrc, .eslintrc.js 等配置文件
- 如果你想自定
stylelint 检查代码的规范,可以修改 .stylelintrc, .stylelintrc.js 等配置文件
- 如果你想忽略某些文件不进行代码检查,可以修改
.eslintignore, .stylelintignore 配置文件
参考:
10. 组件化
当项目拥有了一定量的代码之后,就会发现,有些代码是很多页面共用的,于是把这些代码提取出来,封装成一个组件,供各个地方使用。
当拥有多个项目的时候,有些组件需要跨项目使用,一种方式是复制代码到其他项目中,但这种方式会导致组件代码很难维护,所以,一般是用另一种方式:组件化。
组件化就是将组件独立成一个项目,然后在其他项目中安装这个组件,才能使用。
一般组件化会配合私有 npm 仓库一起用。
|
|
|
|
|
|
|
|
在 project1 中安装 component1, component2 组件:
# package.json
{
"dependencies": {
"component1": "^0.0.1",
"component2": "^0.0.1"
}
}
import compoennt1 from 'compoennt1';
import compoennt2 from 'compoennt2';
如果想要了解怎样写好一个组件(npm package),可以参考 从 1 到完美,写一个 js 库、node 库、前端组件库。
参考:
11. 测试
测试的目的在于能以最少的人力和时间发现潜在的各种错误和缺陷,这在项目更新、重构等的过程中尤其重要,因为每当更改一些代码后,你并不知道这些代码有没有问题、会不会影响其他的模块。如果有了测试,运行一遍测试用例,就知道更改的代码有没有问题、会不会产生影响。
一般前端测试分以下几种:
- 单元测试:模块单元、函数单元、组件单元等的单元块的测试
- 集成测试:接口依赖(ajax)、I/O 依赖、环境依赖(localStorage、IndexedDB)等的上下文的集成测试
- 样式测试:对样式的测试
- E2E 测试:端到端测试,也就是在实际生产环境测试整个应用
一般会用到下面的一些工具:
另外,可以参考 聊聊前端开发的测试。
12. 构建
一般单页面应用的构建会有 npm run build 的命令来构建项目,然后会输出一个 html 文件,一些 js/css/images ... 文件,然后把这些文件部署到服务器就可以了。
多页面应用的构建要复杂一些,因为是多入口的,所以一般会封装构建工具,然后通过参数传入多个入口:
npm run build
page1, page2 确定构建哪些页面;dir1/*, dir2/all 某个目录下所有的页面;all, * 整个项目所有的页面- 有时候可能还会针对不同的服务器环境(比如测试机、正式机)做出不同的构建,可以在后面加参数
-- 用来分割 npm 本身的参数与脚本参数,参考 npm – run-script 了解详情
多页面应用会导出多个 html 文件,需要注意这些导出的 html 不要相冲突了。
当然,也可以用一些已经封装好的工具,如 lila。
13. 部署
在构建好项目之后,就可以部署到服务器了。
传统的方式,可以用 ftp, sftp 等工具,手动传到服务器,但这种方式比较笨拙,不够自动化。
自动化的,可以用一些工具部署到服务器,如 gulp、gulp-ssh,当然也可以用一些封装的工具,如 md-sync、lila 等
以 md-sync 为例:
npm install md-sync
md-sync.config.js 配置文件:
module.exports = [
{
src: './build/**/*',
remotePath: 'remotePath',
server: {
ignoreErrors: true,
sshConfig: {
host: 'host',
username: 'username',
password: 'password'
}
},
},
{
src: './build/**/*.html',
remotePath: 'remotePath2',
server: {
ignoreErrors: true,
sshConfig: {
host: 'host',
username: 'username',
password: 'password'
}
},
},
];
在 package.json 的 scripts 配置好命令:
"scripts": {
"deploy": "md-sync"
}
npm run deploy
另外,一般大型项目会使用持续集成 + shell 命令(如 rsync)部署。
14. 持续集成测试、构建、部署
一般大型工程的的构建与测试都会花很长的时间,在本地做这些事情的话就不太实际,这就需要做持续集成测试、构建、部署了。
持续集成工具用的比较多的:
jenkins 是通用型的工具,可以与 github、bitbucket、gitlab 等代码托管服务配合使用,优点是功能强大、插件多、社区活跃,但缺点是配置复杂、使用难度较高。
gitlab ci 是 gitlab 内部自带的持续集成功能,优点是使用简单、配置简单,但缺点是不及 jenkins 功能强大、绑定 gitlab 才能使用。
以 gitlab 为例(任务定义在 .gitlab-ci.yml 中):
stages:
- install
- test
- build
- deploy
install:
stage: install
only:
- dev
- master
script:
- npm install
test:
stage: test
only:
- dev
- master
script:
- npm run test
build:
stage: build
only:
- dev
- master
script:
- npm run clean
- npm run build
deploy:
stage: deploy
only:
- dev
- master
script:
- npm run deploy
以上配置表示只要在 dev 或 master 分支有代码推送,就会进行持续集成,依次运行:
npm installnpm run testnpm run cleannpm run buildnpm run deploy
最终完成部署。如果中间某个命令失败了,将停止接下的命令的运行,并将错误报告给你。
这些操作都在远程机器上完成。
=================================================
到这里为止,基本上完成了一个项目的搭建、编写、构建。
15. 清理服务器上过期文件
现在前端的项目基本上都会用 webpack 打包代码,并且文件名(html 文件除外)都是 hash 化的,如果需要清除过期的文件而又不想把服务器上文件全部删掉然后重新构建、部署,可以使用 sclean 来清除过期文件。
16. 收集前端错误反馈
当用户在用线上的程序时,怎么知道有没有出 bug;如果出 bug 了,报的是什么错;如果是 js 报错,怎么知道是那一行运行出了错?
所以,在程序运行时捕捉 js 脚本错误,并上报到服务器,是非常有必要的。
这里就要用到 window.onerror 了:
window.onerror = (errorMessage, scriptURI, lineNumber, columnNumber, errorObj) => {
const data = {
title: document.getElementsByTagName('title')[0].innerText,
errorMessage,
scriptURI,
lineNumber,
columnNumber,
detailMessage: (errorObj && errorObj.message) || '',
stack: (errorObj && errorObj.stack) || '',
userAgent: window.navigator.userAgent,
locationHref: window.location.href,
cookie: window.document.cookie,
};
post('url', data);
};
线上的 js 脚本都是压缩过的,需要用 sourcemap 文件与 source-map 查看原始的报错堆栈信息,可以参考 细说 js 压缩、sourcemap、通过 sourcemap 查找原始报错信息 了解详细信息。
参考:
后续
更多博客,查看 https://github.com/senntyou/blogs
作者:深予之 (@senntyou)
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
from:https://segmentfault.com/a/1190000017158444





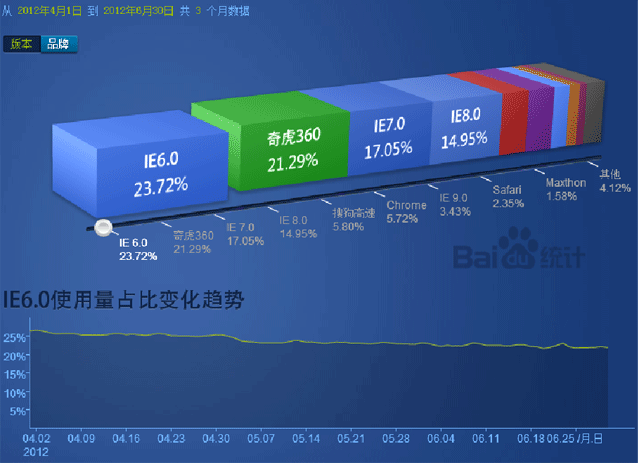 截图来自(http://tongji.baidu.com/data/browser),之所以选择百度的统计数据,是因为更加符合国内的实际情况。图中所展示的是2012年4月1日到2012年6月30日之间的统计数据,从图中不难看出IE6.0、奇虎360、IE7.0和IE8.0加起来一共占据了77%的市场,FireFox属于其他,chrome只有5.72%的份额,再一次告诉我们,我们的主战场依然是IE系。
截图来自(http://tongji.baidu.com/data/browser),之所以选择百度的统计数据,是因为更加符合国内的实际情况。图中所展示的是2012年4月1日到2012年6月30日之间的统计数据,从图中不难看出IE6.0、奇虎360、IE7.0和IE8.0加起来一共占据了77%的市场,FireFox属于其他,chrome只有5.72%的份额,再一次告诉我们,我们的主战场依然是IE系。
















