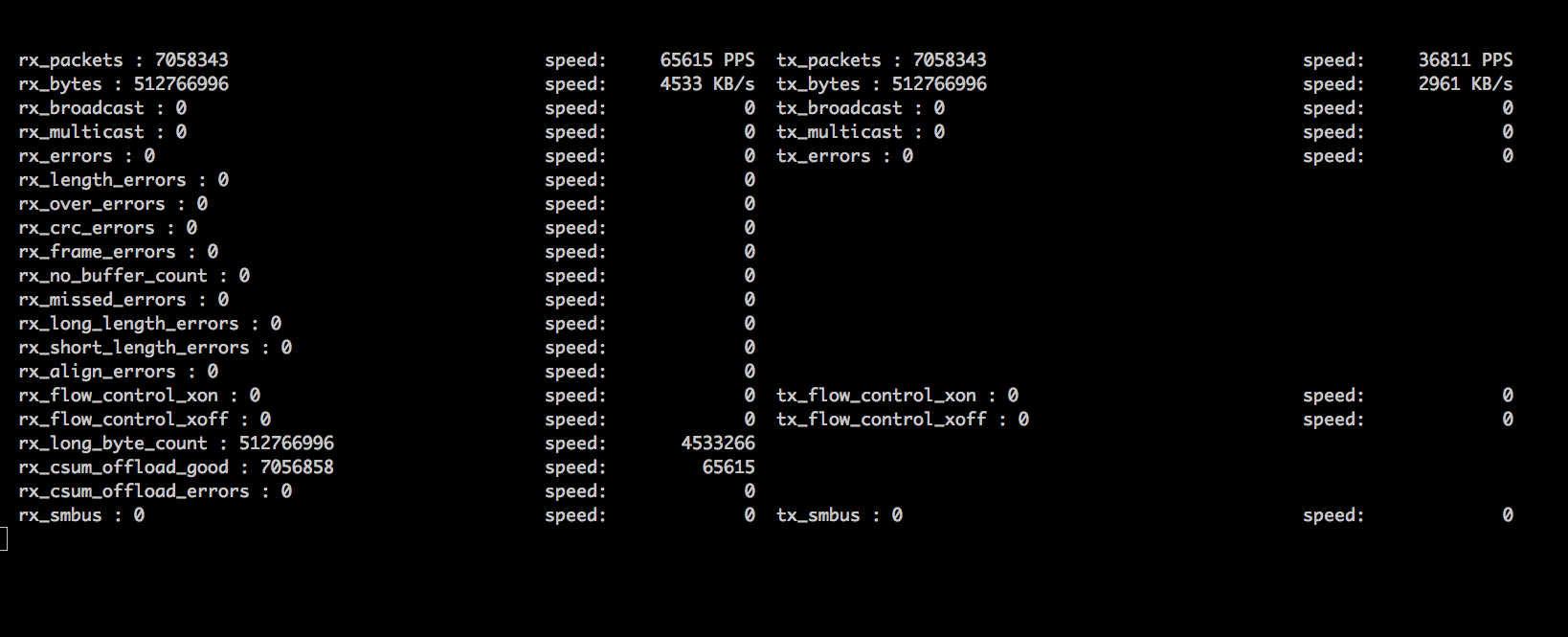
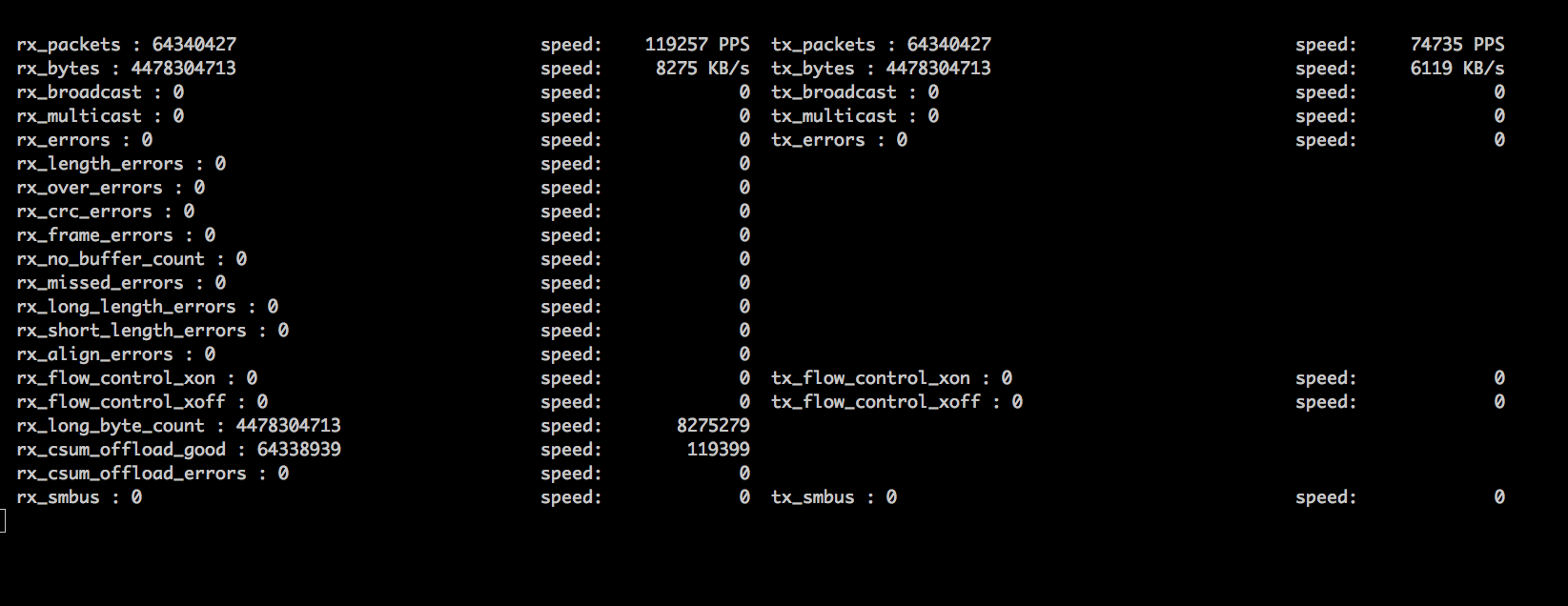
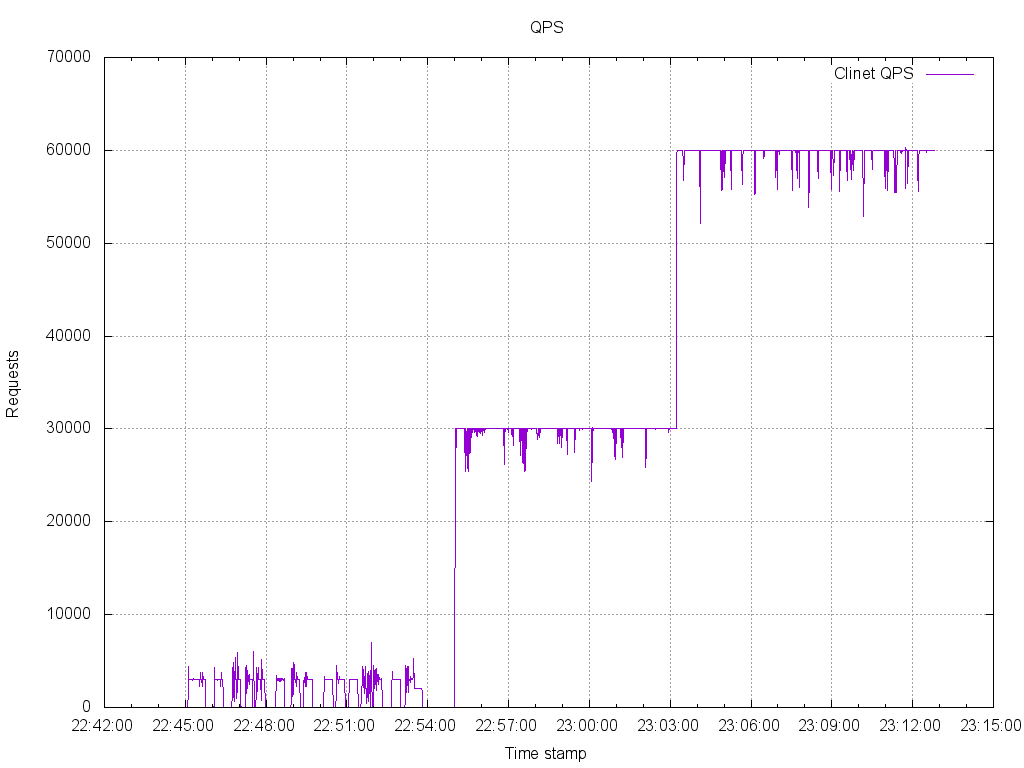
老司机程序员用到的各种优秀资料、神器及框架整理 | IT瘾
成为一名专业程序员的道路上,需要坚持练习、学习与积累,技术方面既要有一定的广度,更要有自己的深度。
笔者作为一位tool mad,将工作以来用到的各种优秀资料、神器及框架整理在此,毕竟好记性不如烂键盘,此项目可以作为自己的不时之需。
本人喜欢折腾,记录的东西也比较杂,各方面都会有一些,内容按重要等级排序,大家各取所需。
这里的东西会持续积累下去,欢迎Star,也欢迎发PR给我。
目录
<!– END doctoc generated TOC please keep comment here to allow auto update –>
资料篇
技术站点
- 在线学习: Coursera、 edX、 Udacity、 MIT公开课、 MOOC学院
- Hacker News:非常棒的针对编程的链接聚合网站
- Techmeme:美国知名科技新闻和博客聚集网站,类似的还有(Panda, Hacker & Designer News)
- Programming reddit:同上
- Java牛人必备: Program Creek
- stackoverflow:IT技术问答网站
- GitHub:全球最大的源代码管理平台,很多知名开源项目都在上面,如Linux内核,OpenStack等
- LeetCode:来做做这些题吧,看看自己的算法水平如何?这可比什么面试宝典强多了。
- Kaggle,Topcoder: 机器学习、大数据竞赛
- 掘金:高质量的技术社区
- 开发者头条
- InfoQ:企业级应用,关注软件开发领域
- V2EX: way to explore
- 国内老牌技术社区:OSChina、博客园、CSDN、51CTO
- 免费的it电子书: http://it-ebooks.info/
- 在线学习: http://www.udemy.com/
- 优质学习资源: http://plus.mojiax.com/
- 代码练习: http://exercism.io/ and https://www.codingame.com
- DevStore:开发者服务商店
- MSDN:微软相关的官方技术集中地,主要是文档类
必看书籍
- SICP( Structure and Interpretation of Computer Programs)
- 深入理解计算机系统
- 代码大全2
- 人件
- 人月神话
- 软件随想录
- 算法导论(麻省理工学院出版社)
- 离线数学及其应用
- 设计模式
- 编程之美
- 黑客与画家
- 编程珠玑
- The Little Schemer
- Simply Scheme_Introducing_Computer_Science
- C++ Prime
- Effective C++
- TCP/IP详解
- Unix 编程艺术
- 软件随想录
- 计算机程序设计艺术
- 职业篇:程序员的自我修养,程序员修炼之道,高效能程序员的修炼
- 《精神分析引论》弗洛伊德
- 《失控》《科技想要什么》《技术元素》凯文凯利
- 程序开发心理学
- 天地一沙鸥
- 搞定:无压力工作的艺术
大牛博客
- 云风(游戏界大牛): http://blog.codingnow.com/
- 王垠(不少文章喷到蛮有道理): http://www.yinwang.org/
- 冰河-伞哥(Lisp大牛): http://tianchunbinghe.blog.163.com/
- R大 【干货满满】RednaxelaFX写的文章/回答的导航帖
- 陈皓-左耳朵耗子: http://coolshell.cn/
- Jeff Atwood(国外知名博主): https://blog.codinghorror.com/
- 阮一峰(黑客与画家译者,Web): http://www.ruanyifeng.com/
- 廖雪峰(他的Python、Git教程不少人都看过): http://www.liaoxuefeng.com/
- 道哥的黑板报(安全): https://zhuanlan.zhihu.com/taosay
- 国内GitHub上关注度较高的开发者
GitHub篇
学习资料篇
- 自然语言处理NLP推荐学习路线及参考资料
- 1.Awesome:平台,语言,五花八门的技术合集 , 2.lists, 3.各种Awesome
- awesom-python
- Awesome Swift
- Awesome Nodejs(学习nodejs的资料够全了)
- Awesome Javascript
- Awesome R
- Awesome Scala
- awesome-java
- awesome-go
- awesome-react
- awesome-sysadmin
- awesome-ios
- awesome-ios-ui
- awesome-android-ui
- Awesome-MaterialDesign
- awesome-public-datasets
- awesome-AppSec(系统安全)
- awesome-datascience
- React-Native学习指南
- GoBooks
- Papers we love
- stackoverflow_scala_info
- Scala Tour
- Bast-App
- R的极客理想系列文章
- Nodejs学习路线图
- 如何学习nodejs
- 超级棒的机器学习资料(框架,库,软件), 中文翻译版
- 机器学习(Machine Learning)&深入学习(Deep Learning)资料
- 非常不错的语言类学习资料集合:Awesomeness
- free-programming-books 中文版
- 免费的编程中文书籍索引
- 《程序员编程艺术 — 面试和算法心得》
- 前端技能汇总
- 前端资源大导航
- 收集前端方面的书籍
- 分享自己长期关注的前端开发相关的优秀网站、博客、以及活跃开发者
- 2014年最新前端开发面试题
- 简单清晰的JavaScript语言教程,代码示例
- JavaScript编程规范
- JavaScript必看视频
- JavaScript标准参考教程(阮一峰的,整理的不错)
- JS必看
- 《Swift编程语言》中文版
- AngularJS Guide的中文分支
- Angular2学习资料
- AngularJS应用的最佳实践和风格指南
- 七天学会NodeJS
- node.js中文资料导航
- Nginx开发从入门到精通
- 一起写Python文章,一起看Python文章
- Android Code Path
- PHP 类库框架,资料集合
- Docker资料合集
- 学习使用Strom
- Hadoop Internals
- Spark Internals
- 大数据时代的数据分析与数据挖掘 – 基于Hadoop实现
- 如何制作操作系统
- 借助开源项目学习软件开发
- 几个不错的开源游戏引擎
- 最值得关注的10个C语言开源项目
- 15款值得学习的小型开源项目
- iOS-100个开源组件
- 十大Material Design开源项目
- GitHub秘籍
- Git风格指南
- 前端资源
- 前端开发指南
- HTTP接口设计指南
- Readings in Databases
- Data Science blogs
- 日志:每个软件工程师都应该知道的有关实时数据的统一概念
Swift相关
客户端
Framework
小工具
游戏
工作、工具篇
- 系统管理员工具集合
- Pro Git
- Google 全球 IP 地址库
- 收集整理远程工作相关的资料
- Color schemes for hackers
- 游戏开发工具集,MagicTools
- 开发者工具箱, free-for-dev
优秀项目篇
工具篇
平台工具
- Phabricator: 软件开发平台,Facebook出品,现已开源,CodeReview神器(从这个往下一直到GitLab之间的工具统统可以忽略了)
- Redmine/Trac:项目管理平台
- Jenkins/Jira(非开源):持续集成系统(Apache Continuum,这个是Apache下的CI系统,还没来得及研究)
- git,svn:源代码版本控制系统
- GitLab/Gitorious:构建自己的GitHub服务器
- Postman:RESTful,api测试工具,HTTP接口开发必备神器
- Sonar:代码质量管理平台
- Nessus: 系统漏洞扫描器
- gitbook: https://www.gitbook.io/写书的好东西,当然用来写文档也很不错的(发现不少产品的文档就是用的它)
- Travis-ci:开源项目持续集成必备,和GitHub相结合, https://travis-ci.org/
- Trello:简单高效的项目管理平台,注重看板管理
- 日志聚合:graylog、ELK(推荐新一代的graylog,基本上算作是开源的Splunk了)
- 开源测试工具、社区(Selenium、OpenQA.org)
- Puppet:一个自动管理引擎,可以适用于Linux、Unix以及Windows平台。所谓配置管理系统,就是管理机器里面诸如文件、用户、进程、软件包这些资源。无论是管理1台,还是上万台机器Puppet都能轻松搞定。其他类似工具:CFEngine、SaltStack、Ansible
- Nagios:系统状态监控报警,还有个Icinga(完全兼容nagios所有的插件,工作原理,配置文件以及方法,几乎一模一样。配置简单,功能强大)
- Ganglia:分布式监控系统
- fleet:分布式init系统
- Ansible:能够大大简化Unix管理员的自动化配置管理与流程控制方式。
- GeoLite免费数据库
- jsHint:js代码验证工具
- haproxy: 高可用负载均衡(此外类似的系统还有nginx,lvs)
- linux OS性能分析工具:dstat,iostat,iotop,nmon
- kimono:将网页信息转换为api接口的工具
- 集群管理工具:pdsh,ClusterSSH,mussh(可以用它快速管理Hadoop集群)ipa-server做统一的认证管理
- influxdb: 分布式时序数据库,结合Grafana可以进行实时数据分析
- dot: 程序员绘图利器(是种语言,也是个工具)
- Graph::Easy: (Ascii Art工具)字符流程图绘制,实乃程序员装逼神器。其他类似的工具Asciiflow, vi插件:drawit!
- spf13-vim: 让你的vim飞起来!
- Kubernetes: 容器集群管理系统
- Gatling: 服务器性能压力测试工具
- systemtap: Linux内核探测工具、内核调试神器
- Cygwin:Windows下的类UNIX模拟环境
- MinGW:Windows下的GNU工具集
常用工具
- Mac下的神兵利器
- asciinema: 终端录屏神器
- Fiddler:非常好用的Web前端调试工具,当然是针对底层http协议的,一般情况使用Chrome等自带的调试工具也足够了,特殊情况还得用它去处理
- Charles: Mac上的Web代理调试工具,类似Fiddler
- wireshark:知名的网络数据包分析工具
- PowerCmd:替代Windows Cmd的利器
- RegexBuddy:强大的正则表达式测试工具
- Soure Insight:源代码阅读神器
- SublimeText:程序员最爱的编辑器
- Database.NET:一个通用的关系型数据库客户端,基于.NET 4.0开发的,做简单的处理还是蛮方便的
- Navicat Premium:支持MySql、PostgreSQL、Oracle、Sqlite和SQL Server的客户端,通用性上不如Database.NET,但性能方面比Database.NET好很多,自带备份功能也用于数据库定时备份。
- Synergy : 局域网内一套键盘鼠标控制多台电脑
- DameWare:远程协助工具集(我在公司主要控制大屏幕用)
- Radmin: 远程控制工具,用了一段时间的DameWare,还要破解,对Win7支持的不好,还是发现这个好用
- Listary:能极大幅度提高你 Windows 文件浏览与搜索速度效率的「超级神器」
- Clover:给资源管理器加上多标签,我平时工作的时候就用它,像Chrome一样使用资源管理器,甚是方便啊(这是Windows平台的)
- WinLaunch:模拟Mac OS的Launch工具
- Fritzing:绘制电路图
- LICEcap:gif教程制作
- git,svn:版本控制系统
- Enigma Virtual Box(将exe,dll等封装成一个可执行程序)
- Open DBDiff(针对SqlServer)数据库同步
- SymmetricDS:数据库同步
- BIEE,Infomatica,SPSS,weka,R语言:数据分析
- CodeSmith,LightSwitch:代码生成
- Pandoc:Markdown转换工具,出书用的。以前玩过docbook,不过现在还是Markdown盛行啊。
- Window Magnet[Mac]:增强Mac窗口管理功能,想Win7一样具有窗口拖放到屏幕边缘自动调整的功能
- log explorer:查看SqlServer日志
- dependency walker:查询Windows应用程序dll依赖项
- Shairport4w:将iPhone,iPad,iPod上的音频通过AirPlay协议传输到PC上
- ngrok:内网穿透工具
- Axure:快速原型制作工具,还有个在线作图的工具国内的一个创业团队做的,用着很不错 http://www.processon.com/
- Origami: 次世代交互设计神器
- 百度脑图: http://naotu.baidu.com/
- tinyproxy:(Linux)小型的代理服务器支持http和https协议
- EaseUS Partition Master:超级简单的分区调整工具,速度还是蛮快的,C盘不够用了就用它从D盘划点空间吧,不用重装系统这么折腾哦。
- CheatEngine:玩游戏修改内存值必备神器(记得我在玩轩辕剑6的时候就用的它,超级方便呢)
- ApkIDE:Android反编译神器
- 翻、墙工具(自|由|门、天行浏览器,免费的VPN: http://www.mangovpn.com/),发现最方便还属Lantern,免费用起来超级方便(更新于2015-08-22)
- 设计工具:Sketch、OmniGraffle
- MindManger:思维导图
- MagicDraw:Uml图工具
- innotop:MySql状态监测工具
- 墨刀:比Axure更为简单的原型工具,可以快速制作原型
- Karabiner: Mac专用,修改键盘键位的神器,机械键盘必备
- Timing:Mac专用,统计你的时间都花在哪了
- f.lux: 护眼神器,过滤蓝光,程序员护眼必备良品
- LaTeX: 基于ΤΕΧ的排版系统, 让写论文更方便
- Antlr:开源的语法分析器,可以让你毫无压力的写个小parser
第三方服务
- DnsPod:一个不错的只能DNS服务解析提供商
- DigitalOcean:海外的云主机提供商,价格便宜,磁盘是SSD的,用过一段时间整体上还可以,不过毕竟是海外的,网速比较慢。国内的就是阿里云了。还有个比较知名的是:Linode,据说速度上比DigitalOcean好很多
- 移动端推送服务:个推、JPush、云巴
- LeanCloud:移动应用开发服务,包括:数据存储、用户管理、消息推送、应用统计、社交分享、实时聊天等服务
- Color Hunt: 漂亮炫酷的配色网站,程序员的福音
- Heroku: PaaS平台
爬虫相关(好玩的工具)
- Phantomjs(Web自动化测试,服务端渲染等)
- berserkJS(基于Phantomjs的改进版本)
- SlimerJS
- CasperJS
- selenium
- HtmlUnit(开源的java 页面分析工具,也是个Headless的浏览器)
安全相关
- sql注入检测:sqlmap、haviji
- 端口扫描:nmap
- 渗透测试:BurpLoader
- sqltools: sql漏洞利用工具
- snort: 入侵检测
Web服务器性能/压力测试工具/负载均衡器
- ab: ab是apache自带的一款功能强大的测试工具
- curl-loader: 真实模拟、测试Web负载
- http_load: 程序非常小,解压后也不到100K
- webbench: 是Linux下的一个网站压力测试工具,最多可以模拟3万个并发连接去测试网站的负载能力。
- Siege: 一款开源的压力测试工具,可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
- squid(前端缓存),nginx(负载),nodejs(没错它也可以,自己写点代码就能实现高性能的负载均衡器):常用的负载均衡器
- Piwik:开源网站访问量统计系统
- ClickHeat:开源的网站点击情况热力图
- HAProxy:高性能TCP /HTTP负载均衡器
- ElasticSearch:搜索引擎基于Lucene
- Page Speed SDK和YSLOW
- HAR Viewer: HAR分析工具
- protractor:E2E(end to end)自动化测试工具
大数据处理/数据分析/分布式工具
- Hadoop:分布式的文件系统,结合其MapReduce编程模型可以用来做海量数据的批处理(Hive,Pig,HBase啥的就不说了),值得介绍的是Cloudera的Hadoop分支CDH5,基于YARN MRv2集成了Spark可直接用于生产环境的Hadoop,对于企业快速构建数据仓库非常有用。
- Spark:大规模数据处理框架(可以应付企业中常见的三种数据处理场景:复杂的批量数据处理(batch data processing);基于历史数据的交互式查询(interactive query);基于实时数据流的数据处理(streaming data processing)),CSND有篇文章介绍的不错
- 除了Spark,其他几个不错的计算框架还有:Kylin,Flink,Drill
- Ceph:Linux分布式文件系统(特点:无中心)
- Storm:实时流数据处理,可以看下IBM的一篇介绍 (还有个Yahoo的S4,也是做流数据处理的)
- Druid: 实时数据分析存储系统
- Ambari: 大数据平台搭建、监控利器;类似的还有CDH
- Tachyon:分布式内存文件系统
- Mesos:计算框架一个集群管理器,提供了有效的、跨分布式应用或框架的资源隔离和共享
- Impala:新一代开源大数据分析引擎,提供Sql语义,比Hive强在速度上
- presto: facebook的开源工具,大数据分布式sql查询引擎
- SNAPPY:快速的数据压缩系统,适用于Hadoop生态系统中
- Kafka:高吞吐量的分布式消息队列系统
- ActiveMQ:是Apache出品,最流行的,能力强劲的开源消息总线
- MQTT:Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分
- RabbitMQ:记得OpenStack就是用的这个东西吧
- ZeroMQ:宣称是将分布式计算变得更简单,是个分布式消息队列,可以看下云风的一篇文章的介绍
- 开源的日志收集系统:scribe、chukwa、kafka、flume。这有一篇对比文章
- Zookeeper:可靠的分布式协调的开源项目
- Databus:LinkedIn 实时低延迟数据抓取系统
- 数据源获取:Flume、Google Refine、Needlebase、ScraperWiki、BloomReach
- 序列化技术:JSON、BSON、Thrift、Avro、Google Protocol Buffers
- NoSql:ScyllaDB(宣称是世界上最快的NoSql)、Apache Casandra、MongoDB、Apache CouchDB、Redis、BigTable、HBase、Hypertable、Voldemort、Neo4j
- MapReduce相关:Hive、Pig、Cascading、Cascalog、mrjob、Caffeine、S4、MapR、Acunu、Flume、Kafka、Azkaban、Oozie、Greenplum
- 数据处理:R、Yahoo! Pipes、Mechanical Turk、Solr/ Lucene、ElasticSearch、Datameer、Bigsheets、Tinkerpop
- NLP自然语言处理:Natural Language Toolkit、Apache OpenNLP、Boilerpipe、OpenCalais
- 机器学习:TensorFlow(Google出品),WEKA、Mahout、scikits.learn、SkyTree
- 可视化技术:GraphViz、Processing、Protovis、Google Fusion Tables、Tableau、Highcharts、EChats(百度的还不错)、Raphaël.js
- Kettle:开源的ETL工具
- Pentaho:以工作流为核心的开源BI系统
- Mondrian:开源的Rolap服务器
- Oozie:开源hadoop的工作流调度引擎,类似的还有:Azkaban
- 开源的数据分析可视化工具:Weka、Orange、KNIME
- Cobar:阿里巴巴的MySql分布式中间件
- 数据清洗:data wrangler, Google Refine
Web前端
- Material Design: 谷歌出品,必属精品
- Vue.js: 借鉴了Angular及React的JS框架,设计理念较为先进
- GRUNT: js task runner
- Sea.js: js模块化
- knockout.js:MVVM开发前台,绑定技术
- Angular.js: 使用超动感HTML & JS开发WEB应用!
- Highcharts.js,Flot:常用的Web图表插件
- NVD3: 基于d3.js的图表库
- Raw:非常不错的一款高级数据可视化工具
- Rickshaw:时序图标库,可用于构建实时图表
- JavaScript InfoVis Toolkit:另一款Web数据可视化插件
- Pdf.js,在html中展现pdf
- ACE,CodeMirror:Html代码编辑器(ACE甚好啊)
- NProcess:绚丽的加载进度条
- impress.js:让你制作出令人眩目的内容展示效果(类似的还有reveal)
- Threejs:3DWeb库
- Hightopo:基于Html5的2D、3D可视化UI库
- jQuery.dataTables.js:高度灵活的表格插件
- Raphaël:js,canvas绘图库,后来发现百度指数的图形就是用它绘出来的
- director.js:js路由模块,前端路由,Nodejs后端路由等,适合构造单页应用
- pace.js:页面加载进度条
- bower:Web包管理器
- jsnice:有趣的js反编译工具,猜压缩后的变量名, http://www.jsnice.org/
- D3.js: 是一个基于JavaScript数据展示库(类似的还有P5.js)
- Zepto.js:移动端替代jQuery的东东,当然也可以使用jquery-mobile.
- UI框架:Foundation,Boostrap,Pure,EasyUI,Polymer
- 前段UI设计师必去的几个网站:Dribbble,awwwards,unmatchedstyle,UIMaker
- Mozilla 开发者中心: https://developer.mozilla.org/en-US/
- 图标资源:IcoMoon(我的最爱),Font Awesome, Themify Icons,FreePik,Glyphicons
- artDialog:非常漂亮的对话框
- AdminLTE:github上的一个开源项目,基于Boostrap3的后台管理页面框架
- Respond.js:让不懂爱的IE6-8支持响应式设计
- require.js: js模块加载库
- select2:比chosen具有更多特性的选择框替代库
- AngularUI:集成angular.js的UI库
- normalize.css: 采用了现代化标准让各浏览器渲染出的html保持一致的库
- CreateJS:Html5游戏引擎
- Less,Compass:简化CSS开发
- emojify.js:用于自动识别网页上的Emoji文字并将其显示为图像
- simditor:一个不错的开源的html编辑器,简洁高效
- Sencha: 基于html5的移动端开发框架
- SuperScrollorama+TweenMax+skrollr:打造超酷的视差滚动效果网页动画
- jquery-smooth-scroll:同上,平滑滚动插件
- Animate.css:实现了各种动画效果的css库
- Emmet:前端工程师必备,ZenCode的前身
- React: facebook出品的js UI库
- highlight.js:专门用来做语法高亮的库
- GoJS: Html5交互式图表库,看demo更适合层次结构的图表。
- 10 Pure CSS (Mostly) Flat Mobile Devices: http://marvelapp.github.io/devices.css/
- CodePen: http://codepen.io/
- jsfiddle: http://jsfiddle.net/ 前端js,html,css测试利器
语言篇
折腾中:Scala、Python、Lua、JavaScript、Go
待折腾:
Scala
- Scala Standard Library API
- Scala School!: A Scala tutorial by Twitter
- A Tour of Scala: Tutorial introducing the main concepts of Scala
- Scala Overview on StackOverflow: A list of useful questions sorted by topic
- Programming in Scala,最新的第3版,还没有电子版,电子版是第一版
- 《Scala for the Impatient》
- 《Scala in Depth》
- 《Programming Scala》Dean Wampler and Alex Payne. O’Reilly 2009
- Scala By Example
- Scala Cheatsheet学习模式匹配的好资料
- Glossary of Scala and FP terms
- Metascala: A JVM written in Scala
- LMS: Program Generation and Embedded Compilers in Scala
Java
- 常用的IDE:IntelliJ IDEA(强烈推荐),Eclipse,Netbeans
- fastutil: 性能更好的Java集合框架
- Guava: 谷歌的Java工具包,应用广泛
- Curator:Netflix公司开源的一个Zookeeper client library,用于简化Zookeeper客户端编程,现在已经是apache下的一个独立项目了。Spark的HA也用的这货。
- Rx(Reactive Extensions)框架:Vert.x, RxJava(Android中用的比较多), Quasar
- FindBugs: 代码静态分析工具,找出代码缺陷
- Java反编译工具:Luyten,JD-Gui
- Drools: 规则引擎
- Jersey: Java RESTful 框架
- canal: 阿里巴巴出品,binlog增量订阅&消费组件
- Web开发相关:Tomcat、Resin、Jetty、WebLogic等,常用的组件Struts,Spring,Hibernate
- Netty: 异步事件驱动网络应用编程框架,用于高并发网络编程比较好(NIO框架,spark 1.2.0就用netty替代了nio)
- MINA:简单地开发高性能和高可靠性的网络应用程序(也是个NIO框架),不少手游服务端是用它开发的
- jOOQ:java Orm框架
- Janino: 超级小又快的Java编译器,Spark的Tungsten引起用的它
- Activiti:工作流引擎,类似的还有jBPM、Snaker
- Perfuse:是一个用户界面包用来把有结构与无结构数据以具有交互性的可视化图形展示出来.
- Gephi:复杂网络分析软件, 其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具
- Nutch:知名的爬虫项目,hadoop就是从这个项目中发展出来的
- web-harvest:Web数据提取工具
- POM工具:Maven+Artifactory
- Akka:一款基于actor模型实现的 并发处理框架
- EclEmma:覆盖测试工具
- Shiro:安全框架
- joda-time:简化时间处理
- parboiled:表达式解析
- dozer: 深拷贝神器
- dubbo: 阿里巴巴出品的分布式服务框架
- jackson databind: json序列化工具(fastjson,simplejson)
- Atomikos: 分布式事务管理
- BoneCP:性能很赞的数据库连接池组件,据说比c3p0快好多
- ProGuard: obconfuscation tool, 强大的混淆工具
- S-99:Scala相关的99个问题
Python
- PyCharm:最佳Python IDE
- Eric,Eclipse+pydev,比较不错的Python IDE
- PyWin:Win32 api编程包
- numpy:科学计算包,主要用来处理大型矩阵计算等,此外还有SciPy,Matplotlib
- GUI相关:PyQt,PyQwt
- supervisor:进程监控工具
- PyGame: 基于Python的多媒体开发和游戏软件开发模块
- Web框架: Django 开源web开发框架,它鼓励快速开发,并遵循MVC设计
.NET
- Xilium.CefGlue:基于CEF框架的.NET封装,基于.NET开发Chrome内核浏览器
- CefSharp:同上,有一款WebKit的封装,C#和Js交互会更简单
- netz:免费的 .NET 可执行文件压缩工具
- SmartAssembly:变态的.net代码优化混淆工具
- NETDeob0:.net反混淆工具,真是魔高一尺道高一丈啊(还有个de4dot,在GitHub上,都是开源的)
- ILMerge:将所有引用的DLL和exe文件打成一个exe文件
- ILSpy:开源.net程序反编译工具
- Javascript.NET:很不错的js执行引擎,对v8做了封装
- NPOI: Excel操作
- DotRAS:远程访问服务的模块
- WinHtmlEditor: Winform下的html编辑器
- SmartThreadPool:使用C#实现的,带高级特性的线程池
- Snoop: WPF Spy Utility
- Autofac: 轻量级IoC框架
- HtmlAgilityPack:Html解析利器
- Quartz.NET:Job调度
- HttpLib:@CodePlex,简化http请求
- SuperSocket:简化Socket操作,基于他的还有个SuperWebSocket,可以开发独立的WebSocket服务器了
- DocX:未安装Office的情况下操作Word文件
- Dapper:轻量级的ORM类,性能不错
- HubbleDotNet:支持接入数据库的全文搜索系统
- fastJSON:@CodeProject,高性能的json序列化类
- ZXing.NET:@CodePlex,QR,条形码相关
- Nancy:轻量级Http服务器,做个小型的Web应用可以摆脱IIS喽(Nancy.Viewengines.Razor,可以加入Razor引擎)
- AntiXSS:微软的XSS防御库Microsoft Web Protection Library
- Jint:JavaScript解释器
- CS-Script:将C#代码文件作为脚本执行
- Jexus:Linux下 高性能、易用、免费的ASP.NET服务器
- Clay:将dynamic发挥的更加灵活,像写js一样写C#
- DynamicJSON:不必定义数据模型获取json数据
- SharpPcap:C#版的WinPcap调用端,牛逼的网络包分析库(自带PacketNotNet用于包协议分析)
- Roslyn:C#,VB编译器
- ImageResizer: 服务端自由控制图片大小,真乃神器也,对手机端传小图,PC端传大图,CMS用它很方便
- UI相关:DevExpress, Fluent(Office 07风格), mui(Modern UI for WPF)
- NetSparkle:应用自动更新组件
- ConfuserEx: 开源.net混淆工具
- ServiceStack: 开源高性能Web服务框架,可用于构建高性能的REST服务
- Expression Evaluator:Eval for C#,处理字符串表达式
- http://nugetmusthaves.com/
- Reactive Extensions (Rx):异步,事件驱动编程包, Rx = Observables + LINQ + Schedulers
C & C++
- Thrift:用来进行可扩展且跨语言的服务的开发(类似的还有个Avro,Google protobuf)。
- libevent:是一个事件触发的网络库,适用于windows、linux、bsd等多种平台,内部使用select、epoll、kqueue等系统调用管理事件机制。(对了还有个libev呢)
- Boost:不多说了,准C++标准库
- Valgrind/Ptmalloc/Purify: 调试工具
- NetworkServer架构:acceptor->dispatcher->worker(这个不算工具哦)
- breakpad:崩溃转储和分析模块,很多crashreport会用到
- UI界面相关:MFC、BCG和QT这类的就不说了,高端一点的还有Html和DirectUI技术:libcef(基于chrome内核的,想想使用html5开发页面,还真有点小激动呢)、HtmlLayout、Duilib、Bolt,非C++的,还有node-webkit也不错,集成了node和webkit内核。
其他
游戏开发相关
- MINA:使用Java开发手游和页游服务器(对了还有Netty,也很猛的,都是基于NIO的)
- HP-Socket:见有有些页游服务器使用这个构建的
- Unreal: 虚幻引擎,C++,基于这个引擎的游戏很多
- OGRE:大名鼎鼎的3D图形渲染引擎,天龙八部OL、火炬之光等不少游戏都用了这个引擎
- OpenVDB:梦工厂C++的特效库,开源的
- cocos2d:跨平台2D游戏引擎
- unity3d:跨平台3D游戏引擎,很火的哦
- Nodejs:也有不少使用它来开发手游和也有服务器(网易的Pomelo)
日志聚合,分布式日志收集
- Scribe:Facebook的(nodejs + scribe + inotify 同步日志)
- logstash:强大的日志收集系统,可以基于logstash+kibana+elasticsearch+redis开发强大的日志分析平台
- log.io: nodejs开发的实时日志收集系统
RTP,实时传输协议与音视频
- RTP,RTCP,RTSP-> librtp,JRTPLIB(遵循了RFC1889标准)
- 环形缓冲区,实时数据传输用
- SDL,ffmpeg,live555,Speex
- Red5:用Java开发开源的Flash流媒体服务器。它支持:把音频(MP3)和视频(FLV)转换成播放流; 录制客户端播放流(只支持FLV);共享对象;现场直播流发布;远程调用。
from:http://itindex.net/detail/56707-%E8%80%81%E5%8F%B8-%E7%A8%8B%E5%BA%8F%E5%91%98-%E8%B5%84%E6%96%99