基本概念
学习方法
应用场景
相关技巧
- 数据分析和挖掘有哪些公开的数据来源?
- 如何成为一名数据科学家?
- 数据科学家 / 统计学家应该养成哪些好习惯?
- 用户画像如何验证准确性?
- 一个有三年工作经验的优秀数据分析师所具备的能力有哪些?怎么衡量?从哪几个方面?
- 精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
培训材料:
from:https://www.zhihu.com/topic/19553534
培训材料:
from:https://www.zhihu.com/topic/19553534
这个问题思考了很久,作为过来人谈一谈,建议先看下以前的一些回答。
磨刀不误砍柴工。在学习数据挖掘之前应该明白几点:
如果你阅读了以上内容觉得可以接受,那么继续往下看。
学习一门技术要和行业靠拢,没有行业背景的技术如空中楼阁。技术尤其是计算机领域的技术发展是宽泛且快速更替的(十年前做网页设计都能成立公司),一般人没有这个精力和时间全方位的掌握所有技术细节。但是技术在结合行业之后就能够独当一面了,一方面有利于抓住用户痛点和刚性需求,另一方面能够累计行业经验,使用互联网思维跨界让你更容易取得成功。不要在学习技术时想要面面俱到,这样会失去你的核心竞争力。
一、目前国内的数据挖掘人员工作领域大致可分为三类。
二、说说各工作领域需要掌握的技能。
(1).数据分析师
(2).数据挖掘工程师
(3).科学研究方向
三、以下是通信行业数据挖掘工程师的工作感受。
真正从数据挖掘项目实践的角度讲,沟通能力对挖掘的兴趣爱好是最重要的,有了爱好才可以愿意钻研,有了不错的沟通能力,才可以正确理解业务问题,才能正确把业务问题转化成挖掘问题,才可以在相关不同专业人才之间清楚表达你的意图和想法,取得他们的理解和支持。所以我认为沟通能力和兴趣爱好是个人的数据挖掘的核心竞争力,是很难学到的;而其他的相关专业知识谁都可以学,算不上个人发展的核心竞争力。
说到这里可能很多数据仓库专家、程序员、统计师等等都要扔砖头了,对不起,我没有别的意思,你们的专业对于数据挖掘都很重要,大家本来就是一个整体的,但是作为单独一个个体的人来说,精力有限,时间有限,不可能这些领域都能掌握,在这种情况下,选择最重要的核心,我想应该是数据挖掘技能和相关业务能力吧(从另外的一个极端的例子,我们可以看, 比如一个迷你型的挖掘项目,一个懂得市场营销和数据挖掘技能的人应该可以胜任。这其中他虽然不懂数据仓库,但是简单的Excel就足以胜任高打6万个样本的数据处理;他虽然不懂专业的展示展现技能,但是只要他自己看的懂就行了,这就无需什么展示展现;前面说过,统计技能是应该掌握的,这对一个人的迷你项目很重要;他虽然不懂编程,但是专业挖掘工具和挖掘技能足够让他操练的;这样在迷你项目中,一个懂得挖掘技能和市场营销业务能力的人就可以圆满完成了,甚至在一个数据源中根据业务需求可以无穷无尽的挖掘不同的项目思路,试问就是这个迷你项目,单纯的一个数据仓库专家、单纯的一个程序员、单纯的一个展示展现技师、甚至单纯的一个挖掘技术专家,都是无法胜任的)。这从另一个方面也说明了为什么沟通能力的重要,这些个完全不同的专业领域,想要有效有机地整合在一起进行数据挖掘项目实践,你说没有好的沟通能力行吗?
数据挖掘能力只能在项目实践的熔炉中提升、升华,所以跟着项目学挖掘是最有效的捷径。国外学习挖掘的人都是一开始跟着老板做项目,刚开始不懂不要紧,越不懂越知道应该学什么,才能学得越快越有效果。我不知道国内的数据挖掘学生是怎样学的,但是从网上的一些论坛看,很多都是纸上谈兵,这样很浪费时间,很没有效率。
另外现在国内关于数据挖掘的概念都很混乱,很多BI只是局限在报表的展示和简单的统计分析,却也号称是数据挖掘;另一方面,国内真正规模化实施数据挖掘的行业是屈指可数(银行、保险公司、移动通讯),其他行业的应用就只能算是小规模的,比如很多大学都有些相关的挖掘课题、挖掘项目,但都比较分散,而且都是处于摸索阶段,但是我相信数据挖掘在中国一定是好的前景,因为这是历史发展的必然。
讲到移动方面的实践案例,如果你是来自移动的话,你一定知道国内有家叫华院分析的公司(申明,我跟这家公司没有任何关系,我只是站在数据挖掘者的角度分析过中国大多数的号称数据挖掘服务公司,觉得华院还不错,比很多徒有虚名的大公司来得更实际),他们的业务现在已经覆盖了绝大多数中国省级移动公司的分析挖掘项目,你上网搜索一下应该可以找到一些详细的资料吧。我对华院分析印象最深的一点就是2002年这个公司白手起家,自己不懂不要紧,一边自学一边开始拓展客户,到现在在中国的移动通讯市场全面开花,的确佩服佩服呀。他们最开始都是用EXCEL处理数据,用肉眼比较选择比较不同的模型,你可以想象这其中的艰难吧。
至于移动通讯的具体的数据挖掘的应用,那太多了,比如不同话费套餐的制订、客户流失模型、不同服务交叉销售模型、不同客户对优惠的弹性分析、客户群体细分模型、不同客户生命周期模型、渠道选择模型、恶意欺诈预警模型,太多了,记住,从客户的需求出发,从实践中的问题出发,移动中可以发现太多的挖掘项目。最后告诉你一个秘密,当你数据挖掘能力提升到一定程度时,你会发现无论什么行业,其实数据挖掘的应用有大部分是重合的相似的,这样你会觉得更轻松。
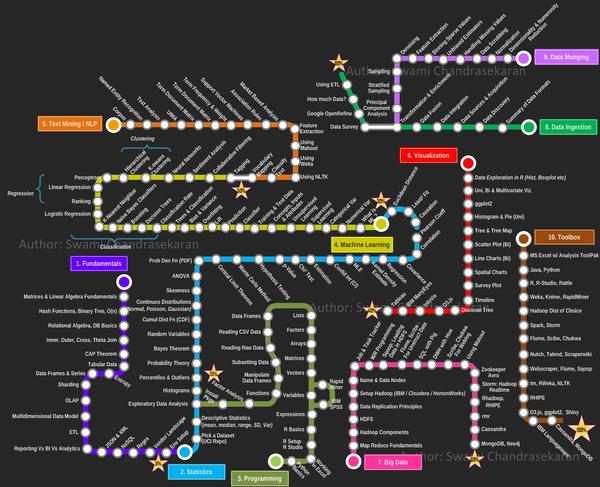
四、成为一名数据科学家需要掌握的技能图。(原文:Data Science: How do I become a data scientist?)
人一能之,己十之;人十能之,己千之。果能此道矣,虽愚,必明;虽柔,必强。
与君共勉。
目录
· 机器学习、大数据相关岗位的职责
· 面试问题
· 答题思路
· 准备建议
· 总结
各个企业对这类岗位的命名可能有所不同,比如推荐算法/数据挖掘/自然语言处理/机器学习算法工程师,或简称算法工程师,还有的称为搜索/推荐算法工程师,甚至有的并入后台工程师的范畴,视岗位具体要求而定。
机器学习、大数据相关岗位的职责
根据业务的不同,岗位职责大概分为:
1、平台搭建类
· 数据计算平台搭建,基础算法实现,当然,要求支持大样本量、高维度数据,所以可能还需要底层开发、并行计算、分布式计算等方面的知识;
2、算法研究类
· 文本挖掘,如领域知识图谱构建、垃圾短信过滤等;
· 推荐,广告推荐、APP 推荐、题目推荐、新闻推荐等;
· 排序,搜索结果排序、广告排序等;
· 其它,· 广告投放效果分析;· 互联网信用评价;· 图像识别、理解。
3、数据挖掘类
· 商业智能,如统计报表;
· 用户体验分析,预测流失用户。
以下首先介绍面试中遇到的一些真实问题,然后谈一谈答题和面试准备上的建议。
面试问题
1、你在研究/项目/实习经历中主要用过哪些机器学习/数据挖掘的算法?
2、你熟悉的机器学习/数据挖掘算法主要有哪些?
3、你用过哪些机器学习/数据挖掘工具或框架?
4、基础知识· 无监督和有监督算法的区别?· SVM 的推导,特性?多分类怎么处理?· LR 的推导,特性?· 决策树的特性?· SVM、LR、决策树的对比?· GBDT 和 决策森林 的区别?· 如何判断函数凸或非凸?· 解释对偶的概念。· 如何进行特征选择?· 为什么会产生过拟合,有哪些方法可以预防或克服过拟合?· 介绍卷积神经网络,和 DBN 有什么区别?· 采用 EM 算法求解的模型有哪些,为什么不用牛顿法或梯度下降法?· 用 EM 算法推导解释 Kmeans。· 用过哪些聚类算法,解释密度聚类算法。· 聚类算法中的距离度量有哪些?· 如何进行实体识别?· 解释贝叶斯公式和朴素贝叶斯分类。· 写一个 Hadoop 版本的 wordcount· ……
5、开放问题
· 给你公司内部群组的聊天记录,怎样区分出主管和员工?
· 如何评估网站内容的真实性(针对代刷、作弊类)?
· 深度学习在推荐系统上可能有怎样的发挥?
· 路段平均车速反映了路况,在道路上布控采集车辆速度,如何对路况做出合理估计?采集数据中的异常值如何处理?
· 如何根据语料计算两个词词义的相似度?
· 在百度贴吧里发布 APP 广告,问推荐策略?
· 如何判断自己实现的 LR、Kmeans 算法是否正确?
· 100亿数字,怎么统计前100大的?
· ……
答题思路
1、用过什么算法?
· 最好是在项目/实习的大数据场景里用过,比如推荐里用过 CF、LR,分类里用过 SVM、GBDT;
· 一般用法是什么,是不是自己实现的,有什么比较知名的实现,使用过程中踩过哪些坑;
· 优缺点分析。
2、熟悉的算法有哪些?
· 基础算法要多说,其它算法要挑熟悉程度高的说,不光列举算法,也适当说说应用场合;
· 面试官和你的研究方向可能不匹配,不过在基础算法上你们还是有很多共同语言的,你说得太高大上可能效果并不好,一方面面试官还是要问基础的,另一方面一旦面试官突发奇想让你给他讲解高大上的内容,而你只是泛泛的了解,那就傻叉了。
3、用过哪些框架/算法包?
· 主流的分布式框架如 Hadoop,Spark,Graphlab,Parameter Server 等择一或多使用了解;
· 通用算法包,如 mahout,scikit,weka 等;
· 专用算法包,如 opencv,theano,torch7,ICTCLAS 等。
4、基础知识
· 个人感觉高频话题是 SVM、LR、决策树(决策森林)和聚类算法,要重点准备;
· 算法要从以下几个方面来掌握 产生背景,适用场合(数据规模,特征维度,是否有 Online 算法,离散/连续特征处理等角度);原理推导(最大间隔,软间隔,对偶);求解方法(随机梯度下降、拟牛顿法等优化算法);优缺点,相关改进;和其他基本方法的对比;
· 不能停留在能看懂的程度,还要对知识进行结构化整理,比如撰写自己的 cheet sheet,我觉得面试是在有限时间内向面试官输出自己知识的过程,如果仅仅是在面试现场才开始调动知识、组织表达,总还是不如系统的梳理准备;从面试官的角度多问自己一些问题,通过查找资料总结出全面的解答,比如如何预防或克服过拟合。
5、开放问题
· 由于问题具有综合性和开放性,所以不仅仅考察对算法的了解,还需要足够的实战经验作基础;
· 先不要考虑完善性或可实现性,调动你的一切知识储备和经验储备去设计,有多少说多少,想到什么说什么,方案都是在你和面试官讨论的过程里逐步完善的,不过面试官有两种风格:引导你思考考虑不周之处 or 指责你没有考虑到某些情况,遇到后者的话还请注意灵活调整答题策略;
· 和同学朋友开展讨论,可以从上一节列出的问题开始。
准备建议
1、基础算法复习两条线
· 材料阅读 包括经典教材(比如 PRML,模式分类)、网上系列博客,系统梳理基础算法知识;
· 面试反馈 面试过程中会让你发现自己的薄弱环节和知识盲区,把这些问题记录下来,在下一次面试前搞懂搞透。
2、除算法知识,还应适当掌握一些系统架构方面的知识,可以从网上分享的阿里、京东、新浪微博等的架构介绍 PPT 入手,也可以从 Hadoop、Spark 等的设计实现切入。
3、如果真的是以就业为导向就要在平时注意实战经验的积累,在科研项目、实习、比赛(Kaggle,Netflix,天猫大数据竞赛等)中摸清算法特性、熟悉相关工具与模块的使用。
总结
如今,好多机器学习、数据挖掘的知识都逐渐成为常识,要想在竞争中脱颖而出,就必须做到· 保持学习热情,关心热点;· 深入学习,会用,也要理解;· 在实战中历练总结;· 积极参加学术界、业界的讲座分享,向牛人学习,与他人讨论。最后,希望自己的求职季经验总结能给大家带来有益的启发。
附:其它可能的题目-算法/架构/ETL等
End.
转载请注明来自36大数据(36dsj.com):36大数据 » 机器学习及大数据相关面试的职责和面试问题
